一、用Delphi10.3模拟读取百度网页,并读取相关头部信息
一、读取网页的如下:
uses
TxHttp,
Classes,
TxCommon,
Frm_WebTool,
SysUtils; var
m_Url: string;
m_Http: TTxHttp;
m_PostData: string;
m_WebSource: string;
m_Stream: TStringStream; begin
m_Http := TTxHttp.Create;
// 网址
m_Url := Trim(Form_WebTool.LabeledEdit1.Text);
if Trim(m_Url) = '' then
begin
Exit;
end; // 设置Header
with m_Http do
begin
Accept := 'text/html, application/xhtml+xml, */*';
//AcceptEncoding := 'gzip, deflate';// 是否以GZIP方式访问网站
AcceptEncoding := '';
AcceptLanguage := 'zh-CN';
ContentType := 'application/x-www-form-urlencoded';
UserAgent := 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko';
end; // 设置Cookies
m_Http.SetCookies(Trim(Form_WebTool.Memo4.Text), m_Url); // 设置编码
if Form_WebTool.ComboBox2.Text = 'GB2312' then
begin
m_Http.Encoding := TxGB2312;
end
else
begin
m_Http.Encoding := TxUTF8;
end; // Get还是POST
if Form_WebTool.ComboBox1.Text = 'POST' then
begin
m_WebSource := m_Http.GetEx(m_Url);
end
else
begin
m_PostData := Trim(Form_WebTool.Memo3.Text);
// 网页访问函数
m_WebSource := m_Http.PosEx(m_Url, m_PostData);
end;
// 输出网页源码
Form_WebTool.Memo1.Text := m_WebSource;
// 取COOKIES
Form_WebTool.Memo4.Text := m_Http.Cookies;
// 取Header
Form_WebTool.Memo5.Text := m_Http.GetHttpHead;
m_Http.Free; end.
二、设计的界面如下:
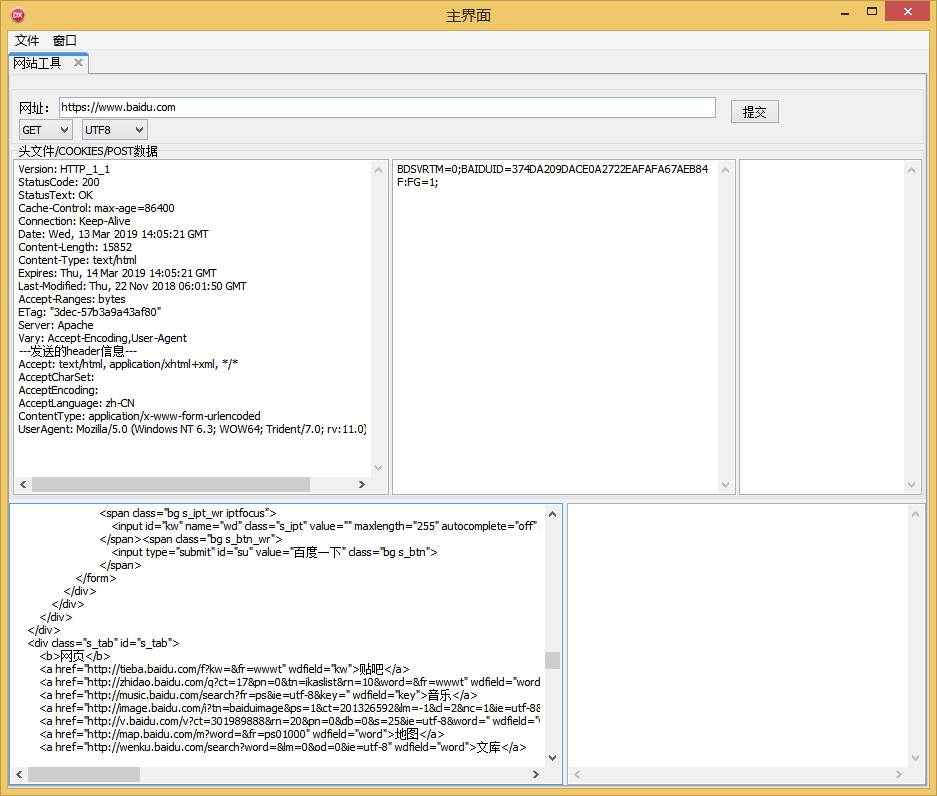
三、 左上的编辑框是我们读取的百度访问的头
Version: HTTP__
StatusCode:
StatusText: OK
Cache-Control: max-age=
Connection: Keep-Alive
Date: Wed, Mar :: GMT
Content-Length:
Content-Type: text/html
Expires: Thu, Mar :: GMT
Last-Modified: Thu, Nov :: GMT
Accept-Ranges: bytes
ETag: "3dec-57b3a9a43af80"
Server: Apache
Vary: Accept-Encoding,User-Agent
---发送的header信息---
Accept: text/html, application/xhtml+xml, */*
AcceptCharSet:
AcceptEncoding:
AcceptLanguage: zh-CN
ContentType: application/x-www-form-urlencoded
UserAgent: Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko
四、中间部分是我们读取的COOKIES
BDSVRTM=;BAIDUID=374DA209DACE0A2722EAFAFA67AEB84F:FG=;
五、最下面就是我们读取的百度的页面内容了。
总结:Delphi10.3读取百度页面是非常简单方便的。
不忘初心,如果您认为这篇文章有价值,认同作者的付出,可以微信二维码打赏任意金额给作者(微信号:382477247)哦,谢谢。

一、用Delphi10.3模拟读取百度网页,并读取相关头部信息的更多相关文章
- Java Socket/HttpURLConnection读取HTTP网页
以读取百度的http网页为例.如果知道了IP地址和端口,然后新建一个Socket,就直接去读百度的首页,根本没反应,原因是www.baidu.com是以http协议传输的,而现在要以Socket原始的 ...
- 模拟登陆百度以及Selenium 的基本用法
模拟登陆百度,需要依赖于selenium 模块,调用浏览器,执行python命令 先来说一下这个selenium模块啦...... 本文参考内容来自 Selenium官网 SeleniumPython ...
- java.net.URL 模拟用户登录网页并维持session
java.net.URL 模拟用户登录网页并维持session 半成品,并非完全有用 import java.io.BufferedReader; import java.io.InputStream ...
- 【教程】模拟登陆百度之Java代码版
[背景] 之前已经写了教程,分析模拟登陆百度的逻辑: [教程]手把手教你如何利用工具(IE9的F12)去分析模拟登陆网站(百度首页)的内部逻辑过程 然后又去用不同的语言: Python的: [教程]模 ...
- Chrome模拟手机浏览网页
用Chrome模拟手机浏览网页,只需要编辑一个命令就可以实现 C:\Users\xxx\AppData\Local\Google\Chrome\Application\chrome.exe --use ...
- 百度网页搜索部来自Console的招聘信息
百度网页搜索部来自Console的招聘信息,小伙伴们,你发现了吗?
- Android 仿百度网页音乐播放器圆形图片转圈播放效果
百度网页音乐播放器的效果 如下 : http://www.baidu.com/baidu?word=%E4%B8%80%E7%9B%B4%E5%BE%88%E5%AE%89%E9%9D%99& ...
- 使用selenium webdriver+beautifulsoup+跳转frame,实现模拟点击网页下一页按钮,抓取网页数据
记录一次快速实现的python爬虫,想要抓取中财网数据引擎的新三板板块下面所有股票的公司档案,网址为http://data.cfi.cn/data_ndkA0A1934A1935A1986A1995. ...
- java.net.URL 模拟用户登录网页并维持session【转】
java.net.URL 模拟用户登录网页并维持session 半成品,并非完全有用 import java.io.BufferedReader; import java.io.InputStream ...
随机推荐
- 【转】Twitter Storm如何保证消息不丢失
Twitter Storm如何保证消息不丢失 发表于 2011 年 09 月 30 日 由 xumingming 作者: xumingming | 可以转载, 但必须以超链接形式标明文章原始出处和作者 ...
- 带你从零学ReactNative开发跨平台App开发[expo 打包发布](八)
ReactNative跨平台开发系列教程: 带你从零学ReactNative开发跨平台App开发(一) 带你从零学ReactNative开发跨平台App开发(二) 带你从零学ReactNative开发 ...
- redis mysql验证 redis_mysql_check.py
# coding:utf-8 import pymysql import redis import sys def con_mysql(sql): db = pymysql.connect(host= ...
- Oracle数据库通过DBLINK实现远程访问
什么是DBLINK? dblink(Database Link)数据库链接顾名思义就是数据库的链接 ,就像电话线一样,是一个通道,当我们要跨本地数据库,访问另外一个数据库表中的数据时,本地数据库中就 ...
- Eigen学习之Array类
Eigen 不仅提供了Matrix和Vector结构,还提供了Array结构.区别如下,Matrix和Vector就是线性代数中定义的矩阵和向量,所有的数学运算都和数学上一致.但是存在一个问题是数学上 ...
- leetCode题解之求二叉树最大深度
1.题目描述 Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along t ...
- 【Kendo UI系列开发使用笔记】01-简单介绍
ps:接触telerik出品的kendo ui系列已经快有一年了,使用过程中也在不断踩坑填坑.这套UI用起来还是非常爽的,尤其asp.net mvc版的配合lambda表达式来配置参数非常流畅.这次对 ...
- solr学习笔记
目录 前言 linux部署 使用 配置 使用 前言 solr是apach基于Lucene开发的成熟的框架,这里我们学习如何部署.使用.关于集群会在后面继续添加 linux部署 mkdir /usr/l ...
- 数据库对比:选择MariaDB还是MySQL?
作者 | EverSQL 译者 | 无明 这篇文章的目的主要是比较 MySQL 和 MariaDB 之间的主要相似点和不同点.我们将从性能.安全性和主要功能方面对这两个数据库展开对比,并列出在选择数据 ...
- Word2016“此功能看似已中断 并需要修复”
Word2016"此功能看似已中断 并需要修复" 文:铁乐与猫 在Win10系统上安装 Office 2016 之后,每次打开Word文档都会提示"很抱歉,此功能看似已中 ...