Spark Streaming概述
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。
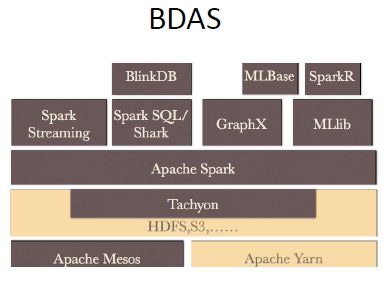
其中包括:资源管理框架,Apache YARN、Apache Mesos;基于内存的分布式文件系统,Tachyon;随后是Spark,更上面则是实现各种功能的系统,比如机器学习MLlib库,图计算GraphX,流计算Spark Streaming。再上面比如:SparkR,分析师的最爱;BlinkDB,我们可以强迫它几秒钟内给我们查询结果。
正是这个生态圈,让Spark可以实现“one stack to rule them all”,它既可以完成批处理也可以从事流计算,从而避免了去实现两份逻辑代码。
Spark Streaming是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库和现场仪表盘上。
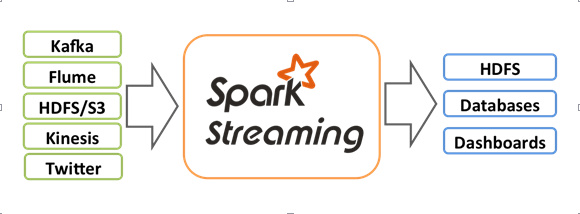
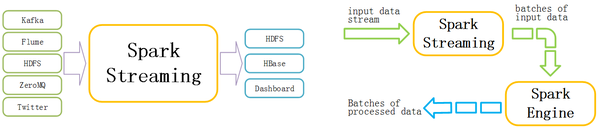
Spark的各个子框架,都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
Spark生态之Spark Streaming
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDD,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者-消费者模型
什么是DStream?
对应的就有生产者-消费者模型的问题,即如何协调生产速率和消费速率。
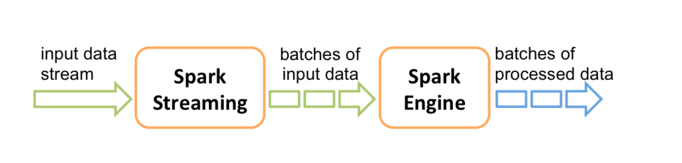
Spark Streaming的内部处理机制流程图
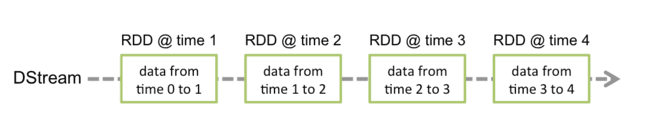
DStream内部的处理机制流程图
Spark Streaming概述的更多相关文章
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- [Spark Streaming_1] Spark Streaming 概述
0. 说明 Spark Streaming 介绍 && 在 IDEA 中编写 Spark Streaming 程序 1. Spark Streaming 介绍 Spark Stream ...
- spark streaming 概述
批处理 & 流处理 像这个是批处理 像这样就是流处理 为什么需要流处理--更多场景需要 Spark Core & RDD 本质上是离线运算 Spark Streaming是什么(分布式 ...
- 1. Spark Streaming概述
1.1 什么是Spark Streaming Spark Streaming类似于Apache Storm,用于流式数据的处理.根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强 ...
- Spark Streaming流式处理
Spark Streaming介绍 Spark Streaming概述 Spark Streaming makes it easy to build scalable fault-tolerant s ...
- 整合Kafka到Spark Streaming——代码示例和挑战
作者Michael G. Noll是瑞士的一位工程师和研究员,效力于Verisign,是Verisign实验室的大规模数据分析基础设施(基础Hadoop)的技术主管.本文,Michael详细的演示了如 ...
- Spark Streaming 实现思路与模块概述
一.基于 Spark 做 Spark Streaming 的思路 Spark Streaming 与 Spark Core 的关系可以用下面的经典部件图来表述: 在本节,我们先探讨一下基于 Spark ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- 2、 Spark Streaming方式从socket中获取数据进行简单单词统计
Spark 1.5.2 Spark Streaming 学习笔记和编程练习 Overview 概述 Spark Streaming is an extension of the core Spark ...
随机推荐
- Android组件化最佳实践 ARetrofit原理
ARetrofit原理讲原理之前,我想先说说为什么要ARetrofit.开发ARetrofit这个项目的思路来源其实是Retrofit,Retrofit是Square公司开发的一款针对Android网 ...
- bootstrap table分页(前后端两种方式实现)
bootstrap table分页的两种方式: 前端分页:一次性从数据库查询所有的数据,在前端进行分页(数据量小的时候或者逻辑处理不复杂的话可以使用前端分页) 服务器分页:每次只查询当前页面加载所需要 ...
- 【Apache Kafka】二、Kafka安装及简单示例
(一)Apache Kafka安装 1.安装环境与前提条件 安装环境:Ubuntu16.04 前提条件: ubuntu系统下安装好jdk 1.8以上版本,正确配置环境变量 ubuntu系统下安 ...
- Git ——Tool
Git: 何为Git: Git 是一个可以实时记录文件变化.维护文件的安全的一个仓库! Git仓库是由** Linux 系统之父 Linus Torvalds ** 创建的一个开源 的软件!Githu ...
- Thesis Viva checklist
This list gives you suggestions helpful in preparing to defend your thesis: I know my thesis thoroug ...
- hadoop手工移块
1.关于磁盘使用策略,介绍参考http://www.it165.net/admin/html/201410/3860.html 在hadoop2.0中,datanode数据副本存放磁盘选择策略有两种方 ...
- ACDream - Chasing Girl
先上题目: Chasing Girl Time Limit: 2000/1000MS (Java/Others) Memory Limit: 128000/64000KB (Java/Others) ...
- Sencha Touch中 xclass和xtype区别
1.xclass 就是 Ext.create(xclass) 和 xtype一样的性质,不一定非要是自己创建的. 2.xtype是xclass的简称. 3.使用xtype前,你要new的对象,先要re ...
- Tornado初学
http://datacademy.io/course 1.资源链接:http://demo.pythoner.com/itt2zh/index.html 2.windows中调用curl 方法:安装 ...
- 洛谷 P3067 [USACO12OPEN]平衡的奶牛群Balanced Cow S…
P3067 [USACO12OPEN]平衡的奶牛群Balanced Cow S… 题目描述 Farmer John's owns N cows (2 <= N <= 20), where ...