Python中的BeautifulSoup模块
目录
BeautifulSoup
BeautifulSoup 是Python的一个库,最主要的功能就是从网页爬取我们需要的数据。BeautifulSoup将 html 解析为对象进行处理,全部页面转变为字典或者数组,相对于正则表达式的方式,可以大大简化处理过程。
from bs4 import BeautifulSoupBeautifulSoup将htmll对象转成对象的过程
response=requests.get("https://www.baidu.com") ##获得网页的回应
html=response.text ##获得网页的源代码
soup=BeautifulSoup(html,"html.parser") ##将网页转化成BeautifSoup对象Beautiful Soup将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是python对象,所有对象可以归纳为4种
- Tag
- NavigableString
- BeautifulSoup
- Comment
Tag
Tag 是什么?通俗点讲就是 HTML 中的一个个标签,例如
<html>
<head>
<title>谢公子的小黑屋</title>
</head>
<body>
<h2>这是标题</h2>
<p class="xie" name="p标签">你好,世界</p>
<img src="1.jpg">
<form action='action.php' method="get">
用户名:<input type="text" name="username" /> <br/>
密码: <input type="password" name="passwd" /> <br/>
<input type="submit" value="登录" />
</form>
</body>
</html>上面的 title 、p 等等 HTML 标签加上里面的内容就是 Tag,下面我们来感受一下怎样用 Beautiful Soup 来方便地获取 Tags
print( soup.title ) ##打印出网页的title标签
print( soup.p) ##打印出网页的p标签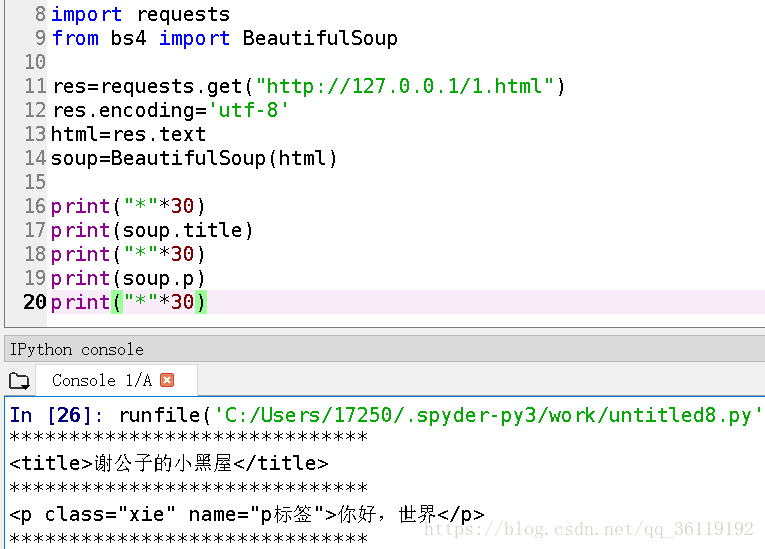
我们可以利用soup加标签名轻松地获取这些标签的内容,但是它查找的是在所有内容中的第一个符号要求的标签
对于 Tag,它有两个重要的属性,是 name 和 attrs
soup.p.name ##p标签的名字
soup.p.string ##p标签的内容
soup.p.attrs ##p标签的属性,返回的是一个字典
soup.p['class'] ##p标签的class属性
soup.p.get('class') ##p标签的class属性,和上面的等价
soup.p['class']="newClass" ##修改p标签的class属性
del soup.p['class'] ##删除p标签的class属性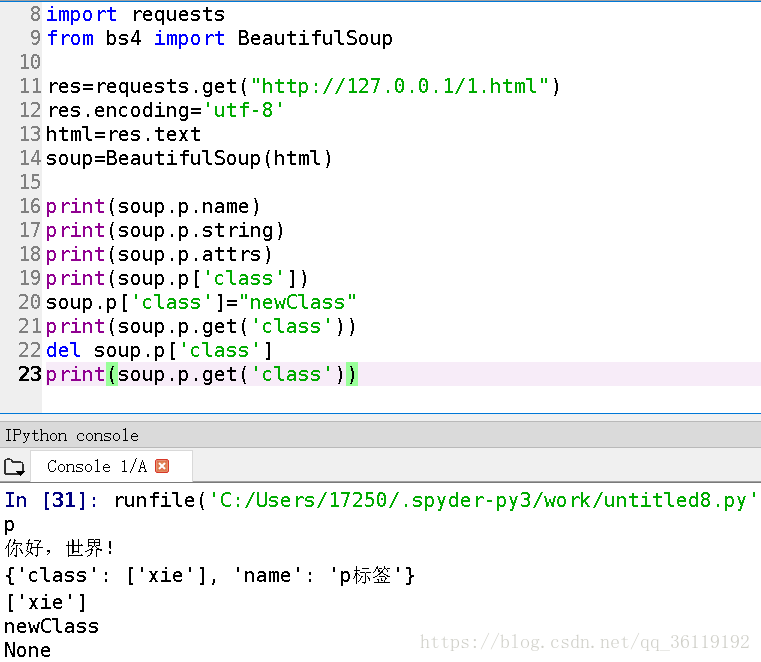
NavigableString
既然我们已经得到了标签的内容,那么如果我们想要获取标签内部的文字怎么办呢?很简单,用 .string 即可
print(soup.p)
print(soup.p.string) ##打印出p标签的内容
## <p class="xie" name="p标签">你好,世界!</p>
## 你好,世界!BeautifulSoup
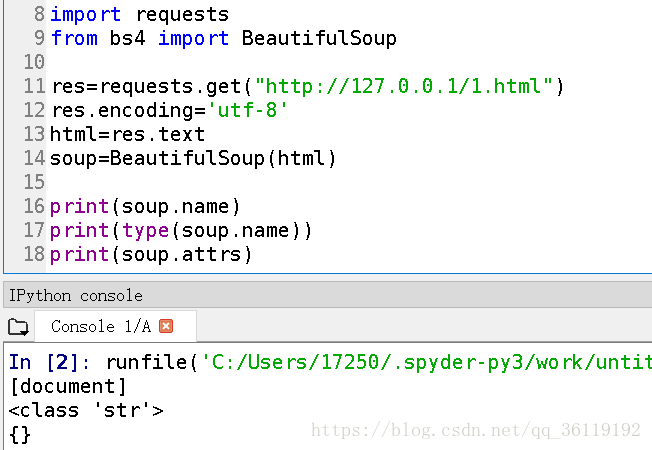
BeautifulSoup对象表示的是一个文档的全部内容。大部分时候,可以把它当做一个Tag对象,是一个特殊的Tag,我们可以分别获取它的类型,名称,以及属性
Comment
Comment对象是一个特殊类型的NavigableString对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦
现在有这么一个网页
<html>
<body>
<p class="xie" name="p标签"><!--你好,世界!--></p>
</body>
</html>
p标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释给去掉了,所以这可能会带给我们不必要的麻烦。如果标签中有注释,则是 comment 对象,没有注释则不是 comment对象所以我们在使用前判断是不是属于 comment类型 。

if type(soup.p.string) != bs4.element.Comment:
print (soup.p.string)遍历文档树
直接子节点
.contents 返回的是一个list列表,可以通过索引方式获取
.children 返回的是一个list生成器,我们需要遍历获取所有子孙节点
print(soup.body.contents) ##打印出body标签内的所有标签,返回的是一个列表,包含\n
print(soup.body.contents[0]) ##我们可以通过索引的方式获取
print(soup.body.children) ##返回的是list生成器,需要遍历获取值
for child in soup.body.children:
print(child)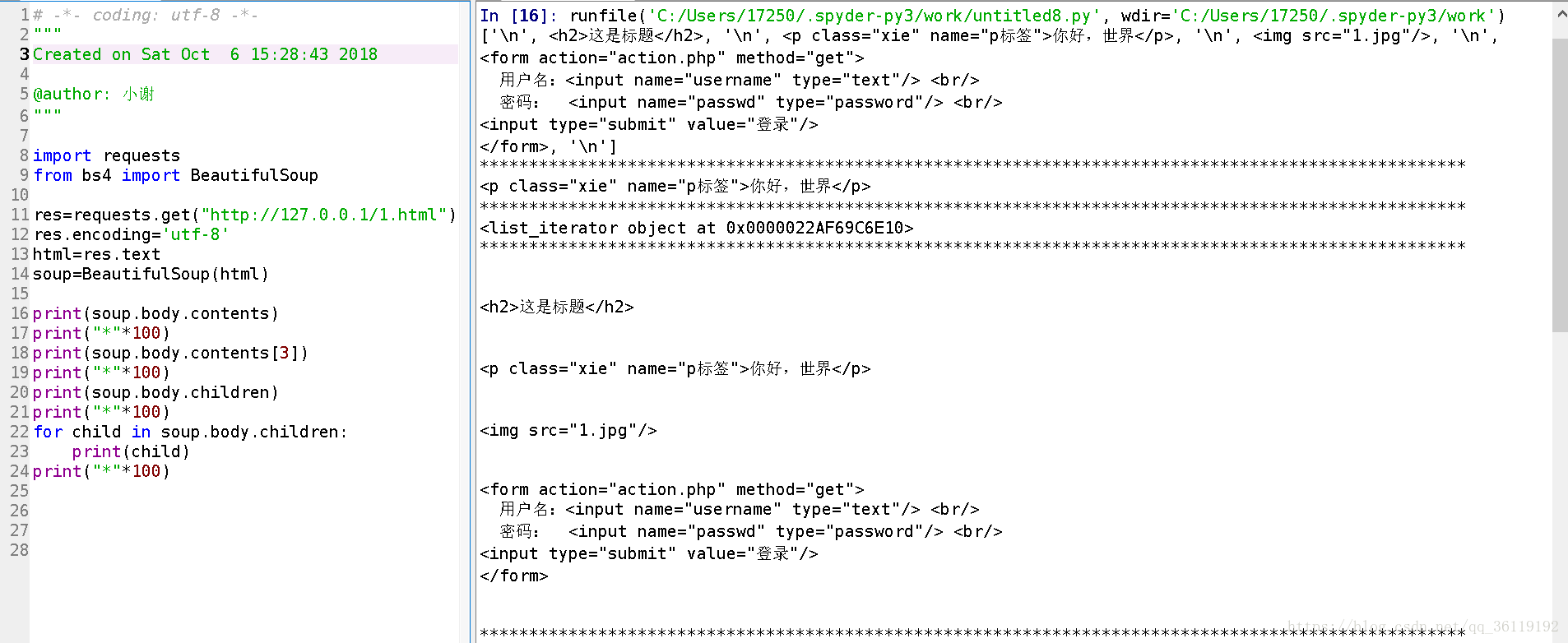
所有子孙节点
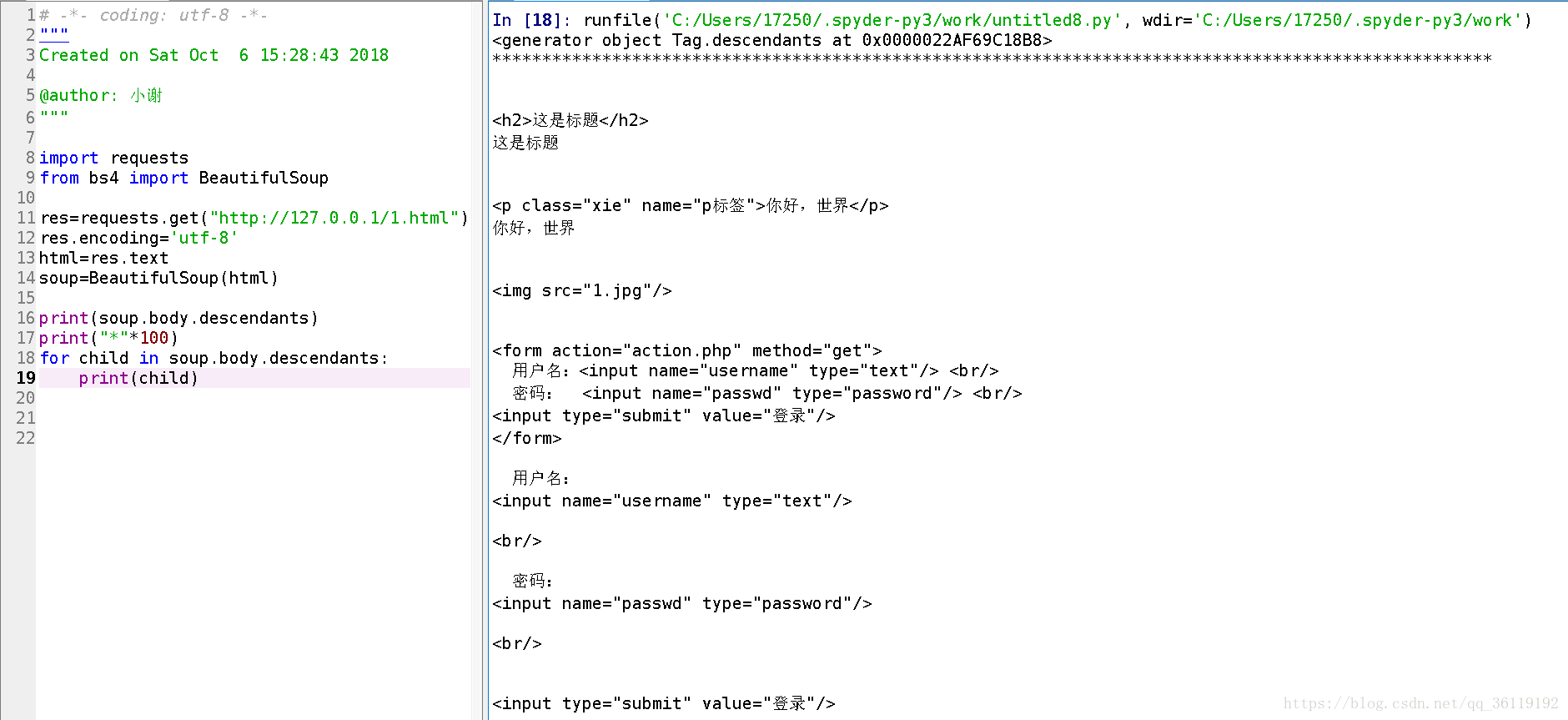
.contents和.children属性仅包含tag的直接子节点,.descendants属性可以对所有tag的子孙节点进行递归循环,和children类似
for child in soup.body.descendants: ##遍历所有子孙节点标签
print( child )
节点内容
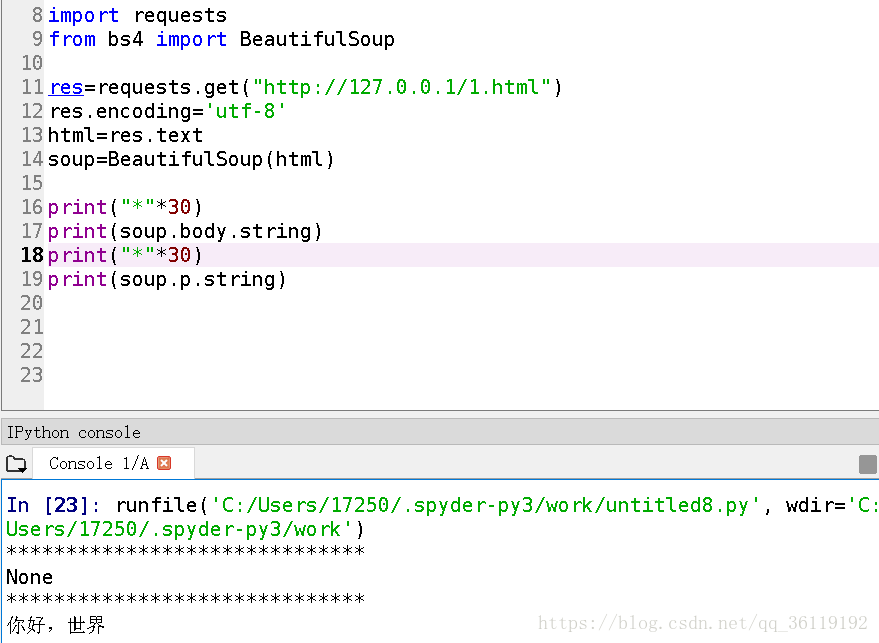
如果一个标签里面没有标签了,那么.string就会返回标签里面的内容。如果标签里面还有其他的标签,则会返回 None
搜索标签
find_all( name , attrs ,recursive , text , **kwargs) 搜素当前页面符合过滤器条件的第一个标签
find_all( name , attrs ,recursive , text , **kwargs) 搜素当前页面符合过滤器条件的所有标签
name参数,查找所有名字为name的 tag,字符串对象会被自动忽略掉
(A) 传字符串
最简单的过滤器是字符串,在搜索方法中传入一个字符串参数,find_all方法会查找所有与字符串完整匹配的内容
print(soup.find_all('a')) ##查找所有的a标签,返回的是一个list列表
print(soup.find_all('a',class_='xie')) ##查找class='xie'的a标签(B)传正则表达式
如果传入正则表达式作为参数,find_all方法会通过正则表达式的match()来匹配内容
for tag in soup.find_all(re.compile("^b")): ##找出所有以b开头的标签
print(tag.name)(c)传列表
如果传入列表参数,find_all将会与列表中任一元素匹配的内容返回。
print(soup.find_all(['a', 'table'])) ##找出所有的a标签和table标签(D)传True
True可以匹配任何值
for tag in soup.find_all(True):
print(tag.name)(E)传方法
如果没有合适过滤器,那么还可以定义一个方法,方法只接收一个元素。如果这个方法返回true,表示当前元素匹配并且被找到,如果不是,则返回false
def has_class_but_no_id(tag): ##定义一个方法,如果tag中包含class属性却不包含id属性,那么返回true
return tag.has_attr('class') and not tag.has_attr('id')
print( soup.find_all(has_class_but_no_id(tag)) )attrs的keyword参数
注意:如果一个指定的参数不是搜素内置的函数名,搜索时会把该参数当做指定名字tag的属性来搜素,如果包含一个名字为id的参数,find_all会搜素每个tag的id属性
print(soup.find_all( id='link' )) ##打印出所有id=link的标签
print(soup.find_all(href=re.compile("elsie"),id='link')) ##打印出href中含有elsie,并且id=link的标签
print(soup.find_all( class_='xie')) ##class是python的关键字,所以加下划线 打印出class为xie的标签text参数
通过text参数可以搜素文档中的字符串内容,与name参数的可选值一样,text参数接受字符串、列表、正则表达式和True
print(soup.find_all(text="name")) ##打印出网页中的name,返回一个列表,没有则返回空
print(soup.find_all(text=re.compile("name"))) ##打印出网页中含有name的词,返回一个列表limit参数
find_all()方法返回全部的搜素结构,如果文档树很大那么搜素会很慢,如果我们不需要全部结果,可以使用limit参数限制返回结果的数量
print(soup.find_all('a',limit=3)) ##找出3个a标签recursive参数
调用tag的find_all()方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜素tag的直接子节点,可以使用参数recursive=False
print(soup.find_all('head',recursive=False))find(name,attrs,recursive,text,**kwargs)
它与find_all()方法唯一的区别是find_all()方法返回结果是只包含第一个元素的列表,而find()方法直接返回结果
CSS选择器
我们在写CSS时,标签名不加任何修饰,类名前加点,id名前加#,在这里我们也可以利用类似的方法来筛选元素,用到的方法是soup.select() , 返回类型是list
通过标签名查找
print(soup.select('title')) ##打印出标签是title的通过类名查找
print(soup.select('.b')) ##打印出类名是b的通过id名查找
print(soup.select('#sister')) ##打印出id名是sister的组合查找
print(soup.select('p #link .xie')) ##打印出p标签中,id=link,class=xie的属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则匹配不到
print(soup.select("a[class='sister']")) ##打印出a标签中class属性是sister的以上的select方法返回的结果都是列表形式,可以遍历形式输出,然后用get_text()方法来获取他的内容
for i in soup.select('a'):
print(i.get_text()) ##打印出a标签中的文本Python中的BeautifulSoup模块的更多相关文章
- 第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问
一. 引言 在<第14.8节 Python中使用BeautifulSoup加载HTML报文>中介绍使用BeautifulSoup的安装.导入和创建对象的过程,本节介绍导入后利用Beauti ...
- Python中的random模块,来自于Capricorn的实验室
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
- Python中的logging模块
http://python.jobbole.com/86887/ 最近修改了项目里的logging相关功能,用到了python标准库里的logging模块,在此做一些记录.主要是从官方文档和stack ...
- Python中的random模块
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
- 浅析Python中的struct模块
最近在学习python网络编程这一块,在写简单的socket通信代码时,遇到了struct这个模块的使用,当时不太清楚这到底有和作用,后来查阅了相关资料大概了解了,在这里做一下简单的总结. 了解c语言 ...
- python中的StringIO模块
python中的StringIO模块 标签:python StringIO 此模块主要用于在内存缓冲区中读写数据.模块是用类编写的,只有一个StringIO类,所以它的可用方法都在类中.此类中的大部分 ...
- python中的select模块
介绍: Python中的select模块专注于I/O多路复用,提供了select poll epoll三个方法(其中后两个在Linux中可用,windows仅支持select),另外也提供了kqu ...
- Python中的re模块--正则表达式
Python中的re模块--正则表达式 使用match从字符串开头匹配 以匹配国内手机号为例,通常手机号为11位,以1开头.大概是这样13509094747,(这个号码是我随便写的,请不要拨打),我们 ...
- python中的shutil模块
目录 python中的shutil模块 目录和文件操作 归档操作 python中的shutil模块 shutil模块对文件和文件集合提供了许多高级操作,特别是提供了支持文件复制和删除的函数. 目录和文 ...
随机推荐
- HDOJ-6645(简单题+贪心+树)
Stay Real HDOJ-6645 由小根堆的性质可以知道,当前最大的值就在叶节点上面,所以只需要排序后依次取就可以了. #include<iostream> #include< ...
- 鸿蒙开源第三方件组件——轮播组件Banner
目录: 1.功能展示 2.Sample解析 3.Library解析 4.<鸿蒙开源第三方组件>系列文章合集 前言 基于安卓平台的轮播组件Banner(https://github.com/ ...
- WebRTC 音视频同步原理与实现
所有的基于网络传输的音视频采集播放系统都会存在音视频同步的问题,作为现代互联网实时音视频通信系统的代表,WebRTC 也不例外.本文将对音视频同步的原理以及 WebRTC 的实现做深入分析. 时间戳 ...
- IPFS矿池集群方案详解
IPFS作为一项分布式存储技术,可以说是web3.0发展的基石.关于IPFS的产业,如存储.技术.矿机.矿池等也发展得非常迅速. 什么是单机挖矿? 单机挖矿就是一台机器就是一个节点,一台机器就完成挖矿 ...
- Dynamics CRM 在表单上显示更改历史记录(审核历史记录)
前言 虽然Dynamics CRM自带的审计很好,但是对于缺乏使用CRM经验的用户来说,自带的UCI界面实在是太隐藏了: 于是乎就出现了需求:想通过在表单上直接看到看审计历史记录: 在网上搜索了很多中 ...
- 普通 Javaweb项目模板的搭建
普通 Javaweb项目模板的搭建 1. 创建一个web项目模板的maven项目 2.配置 Tomcat 服务器 3.先测试一下该空项目 4.注入 maven 依赖 5.创建项目的包结构 6.编写基础 ...
- [Fundamental of Power Electronics]-PART I-4.开关实现-4.3 开关损耗/4.4 小结
4.3 开关损耗/4.4 小结 使用半导体器件实现开关后,我们现在可以讨论变换器中损耗和低效的另一个主要来源:开关损耗.如前所述,半导体器件的导通和关断转换需要几十纳秒到几微秒的时间.在这些开关转换期 ...
- Laravel源码解析 — 服务容器
前言 本文对将系统的对 Laravel 框架知识点进行总结,如果错误的还望指出 阅读书籍 <Laravel框架关键技术解析> 陈昊 学习课程 Laravel5.4快速开发简书网站 轩脉刃 ...
- CLion 2020.1.2 激活
1 下载 官网. 2 运行 解压安装并运行,选择Evaluate. 3 激活 来这里下载jar补丁,拖进去即可.
- 07_利用pytorch的nn工具箱实现LeNet网络
07_利用pytorch的nn工具箱实现LeNet网络 目录 一.引言 二.定义网络 三.损失函数 四.优化器 五.数据加载和预处理 六.Hub模块简介 七.总结 pytorch完整教程目录:http ...