Spark-StructuredStreaming 下的checkpointLocation分析以及对接 Grafana 监控和提交Kafka Lag 监控
一、Spark-StructuredStreaming checkpointLocation 介绍
Structured Streaming 在 Spark 2.0 版本于 2016 年引入, 是基于 Spark SQL 引擎构建的可扩展且容错的流处理引擎,对比传统的 Spark Streaming,由于复用了 Spark SQL 引擎,代码的写法和批处理 API (基于 Dataframe 和 Dataset API)一样,而且这些 API 非常的简单。
Structured Streaming 还支持使用 event time,通过设置 watermark 来处理延时到达的数据;而 Spark Streaming 只能基于 process time 做计算,显然是不够用的。
比如 .withWatermark("timestamp", "10 minutes") 表示用 DataFrame 里面的 timestamp 字段作为 event time,如果 event time 比 process time 落后超过 10 分钟,那么就不会处理这些数据。
Structured Streaming 默认情况下还是使用 micro batch 模式处理数据,不过从 Spark 2.3 开始提供了一种叫做 Continuous Processing 的模式,可以在至少一次语义下数据端到端只需 1ms 。
不过 Structured Streaming 的 Web UI 并没有和 Spark Streaming 一样的监控指标。
Checkpoint目录的结构:

1、checkpointLocation 在源码调用链
分析源码查看 StructuredStreaming 启动流程发现,DataStreamWriter#start 方法启动一个 StreamingQuery。
同时将 checkpointLocation配置参数传递给StreamingQuery管理。
StreamingQuery 接口实现关系如下:
StreamingQueryWrapper 仅包装了一个不可序列化的StreamExecution
StreamExecution 管理Spark SQL查询的执行器
MicroBatchExecution 微批处理执行器
ContinuousExecution 连续处理(流式)执行器
因此我们仅需要分析 checkpointLocation 在 StreamExecution中调用即可。
备注:StreamExecution 中 protected def checkpointFile(name: String): String 方法为所有与 checkpointLocation 有关逻辑,返回 $checkpointFile/name 路径
2、MetadataLog(元数据日志接口)
spark 提供了org.apache.spark.sql.execution.streaming.MetadataLog接口用于统一处理元数据日志信息。
checkpointLocation 文件内容均使用 MetadataLog进行维护。
分析接口实现关系如下:
类作用说明:
NullMetadataLog 空日志,即不输出日志直接丢弃
HDFSMetadataLog 使用 HDFS 作为元数据日志输出
CommitLog 提交日志
OffsetSeqLog 偏移量日志
CompactibleFileStreamLog 封装了支持按大小合并、删除历史记录的 MetadataLog
StreamSourceLog 文件类型作为数据源时日志记录
FileStreamSinkLog 文件类型作为数据接收端时日志记录
EsSinkMetadataLog Es作为数据接收端时日志记录
分析 CompactibleFileStreamLog#compact 合并逻辑简单描述为:假设有 0,1,2,3,4,5,6,7,8,9,10 个批次以此到达,合并大小为3当前合并结果为 `0,1,2.compact,3,4`下一次合并结果为 `0,1,2.compact,3,4,5.compact` , **说明:5.compact 文件内容 = 2.compact + 3 + 4**last.compact 文件大小会随着批次运行无限增大...
分析 CompactibleFileStreamLog 删除过期文件逻辑:CompactibleFileStreamLog#add 方法被调用时,默认会判断是否支持删除操作 override def add(batchId: Long, logs: Array[T]): Boolean = { val batchAdded = if (isCompactionBatch(batchId, compactInterval)) { // 是否合并 compact(batchId, logs) } else { super.add(batchId, logs) } if (batchAdded && isDeletingExpiredLog) { // 添加成功且支持删除过期文件 // 删除时判断当前批次是否在 spark.sql.streaming.minBatchesToRetain 配置以外且在文件保留时间内 // 配置项参考 第4节 解决方案配置说明 deleteExpiredLog(batchId) } batchAdded }
3、 分析 checkpointLocation 目录内容
目前 checkpointLocation 内容主要包含以下几个目录
offsets
commits
metadata
sources
sinks
3.1 offsets 目录
记录每个批次中的偏移量。为了保证给定的批次始终包含相同的数据,在处理数据前将其写入此日志记录。
此日志中的第 N 条记录表示当前正在已处理,第 N-1 个条目指示哪些偏移已处理完成。
// StreamExecution 中val offsetLog = new OffsetSeqLog(sparkSession, checkpointFile("offsets"))
// 该日志示例内容如下,文件路径=checkpointLocation/offsets/560504v1{"batchWatermarkMs":0,"batchTimestampMs":1574315160001,"conf":{"spark.sql.streaming.stateStore.providerClass":"org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider","spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion":"2","spark.sql.streaming.multipleWatermarkPolicy":"min","spark.sql.streaming.aggregation.stateFormatVersion":"2","spark.sql.shuffle.partitions":"200"}}{"game_dc_real_normal":{"17":279843310,"8":318732102,"11":290676804,"2":292352132,"5":337789356,"14":277147358,"13":334833752,"4":319279439,"16":314038811,"7":361740056,"1":281418138,"10":276872234,"9":244398684,"3":334708621,"12":290208334,"15":267180971,"6":296588360,"0":350011707}}
3.2 commitLog 目录
记录已完成的批次,重启任务检查完成的批次与 offsets 批次记录比对,确定接下来运行的批次
StreamExecution 中val commitLog = new CommitLog(sparkSession, checkpointFile("commits"))// 该日志示例内容如下,文件路径=checkpointLocation/commits/560504v1{"nextBatchWatermarkMs":0}
3.3 metadata 目录
metadata 与整个查询关联的元数据,目前仅保留当前job id
StreamExecution 中val offsetLog = new OffsetSeqLog(sparkSession, checkpointFile("offsets"))// 该日志示例内容如下,文件路径=checkpointLocation/metadata{"id":"5314beeb-6026-485b-947a-cb088a9c9bac"}
3.4 sources 目录
sources 目录为数据源(Source)时各个批次读取详情
3.5 sinks 目录
sinks 目录为数据接收端(Sink)时批次的写出详情
另外如果在任务中存在state计算时,还会存在state目录: 记录状态。当有状态操作时,如累加聚合、去重、最大最小等场景,这个目录会被用来记录这些状态数据。目录结构:checkpoint/state/xxx.delta、checkpoint/state/xxx.snapshot。新的.snapshot是老的.snapshot和.delta合并生成的文件。Structured Streaming会根据配置周期性地生成.snapshot文件用于记录状态。
二、Spark Structured Streaming 对接 Grafana 监控
Structured Streaming 有个 StreamingQueryListener 用于异步报告指标,这是一个官方示例:
val spark: SparkSession = ...
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})
StreamingQuery API含义:

我们监控的话,主要是利用 onQueryProgress 方法来上报数据给监控系统。
import com.codahale.metrics.graphite.{Graphite, GraphiteReporter}
import com.codahale.metrics.{Gauge, MetricFilter, MetricRegistry}
import org.apache.spark.sql.streaming.StreamingQueryListener
import java.net.InetSocketAddress
import java.util.concurrent.TimeUnit
class SparkStreamingGraphiteMetrics(prefix: String, graphiteHostName: String, graphitePort: Int) extends StreamingQueryListener {
val metrics = new MetricRegistry()
var inputRowsPerSecond = 0D
var processedRowsPerSecond = 0D
var numInputRows = 0D
var triggerExecution = 0L
var batchDuration = 0L
var sourceEndOffset = 0L
var sourceStartOffset = 0L
override def onQueryStarted(event: StreamingQueryListener.QueryStartedEvent): Unit = {
val graphite = new Graphite(new InetSocketAddress(graphiteHostName, graphitePort))
val reporter: GraphiteReporter = GraphiteReporter
.forRegistry(metrics)
.prefixedWith(s"spark_structured_streaming_${prefix}") // 指标名称前缀,便于在 Grafana 里面使用
.convertRatesTo(TimeUnit.SECONDS)
.convertDurationsTo(TimeUnit.MILLISECONDS)
.filter(MetricFilter.ALL)
.build(graphite)
reporter.start(30, TimeUnit.SECONDS)
metrics.register(s"inputRowsPerSecond", new Gauge[Double] {
override def getValue: Double = inputRowsPerSecond
})
metrics.register(s"processedRowsPerSecond", new Gauge[Double] {
override def getValue: Double = processedRowsPerSecond
})
metrics.register("numInputRows", new Gauge[Double] {
override def getValue: Double = numInputRows
})
metrics.register("triggerExecution", new Gauge[Long] {
override def getValue: Long = triggerExecution
})
metrics.register("batchDuration", new Gauge[Long] {
override def getValue: Long = batchDuration
})
metrics.register("sourceEndOffset", new Gauge[Long] {
override def getValue: Long = sourceEndOffset
})
metrics.register("sourceStartOffset", new Gauge[Long] {
override def getValue: Long = sourceStartOffset
})
}
override def onQueryProgress(event: StreamingQueryListener.QueryProgressEvent): Unit = {
// 对各个指标进行赋值、上报
inputRowsPerSecond = event.progress.inputRowsPerSecond
processedRowsPerSecond = event.progress.processedRowsPerSecond
numInputRows = event.progress.numInputRows
triggerExecution = event.progress.durationMs.getOrDefault("triggerExecution", 0L)
batchDuration = event.progress.batchDuration
event.progress.sources.foreach(source => {
sourceEndOffset = source.endOffset.toLong
sourceStartOffset = source.startOffset.toLong
})
}
override def onQueryTerminated(event: StreamingQueryListener.QueryTerminatedEvent): Unit = {
println("onQueryTerminated")
}
}
在主程序里面添加监听:
spark.streams.addListener(xxxxxx)
需要启动 graphite_exporter,随便找一台服务器即可,有两个默认端口:
- 9109 用来上报数据,即 spark -> graphite_exporter
- 9108 是 Prometheus 从 graphite_exporter 拉去数据用的
还需要在 Prometheus 配置文件 prometheus.yml 里面配置读取数据
scrape_configs:
- job_name: 'spark'
static_configs:
- targets: ['192.168.1.xx:9108']
最后启动 spark 程序之后,就可以在 Grafana 里面配置图表了。
配置 Grafana 图表
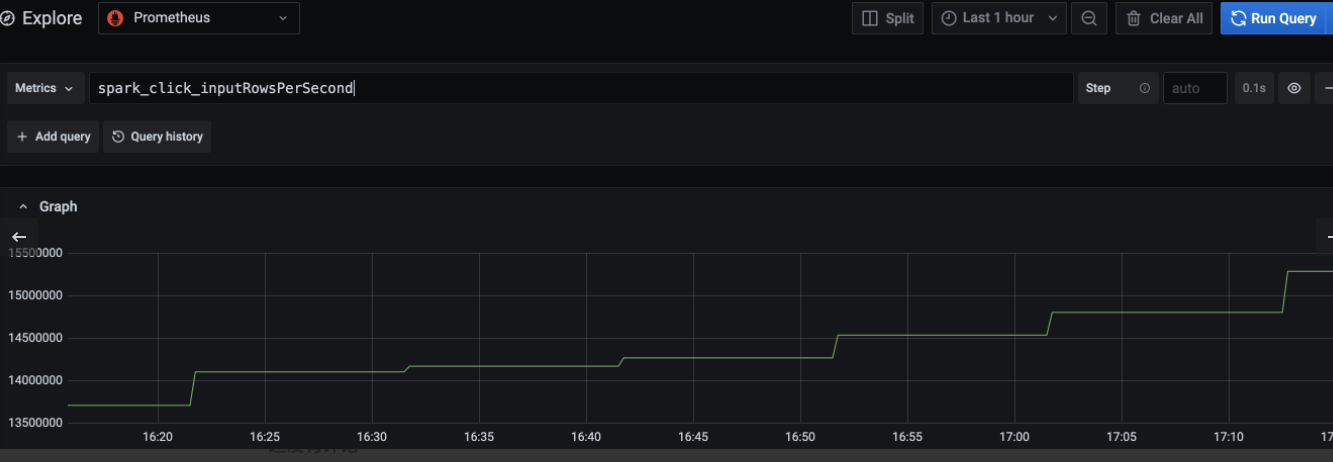
比如我设置的 prefix 是 click,那么我们在 Grafana 里面的 Explore 模块可以选择 Prometheus 数据源,输入指标 spark_click_inputRowsPerSecond ,点击 Query 就可以获取读取速率这个指标了,如图:
三、基于StreamingQueryListener向Kafka提交Offset
我们可以在SparkStreamingGraphiteMetrics的基础上做向kafka提交offset。如下所示
import com.fasterxml.jackson.databind.{DeserializationFeature, ObjectMapper}
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import org.apache.kafka.clients.consumer.{KafkaConsumer, OffsetAndMetadata}
import org.apache.kafka.common.TopicPartition
import org.apache.spark.sql.streaming.StreamingQueryListener.QueryProgressEvent
import java.util
import java.util.Properties
class KafkaOffsetCommiter(prefix: String, graphiteHostName: String, graphitePort: Int, kafkaProperties: Properties) extends SparkStreamingGraphiteMetrics(prefix: String, graphiteHostName: String, graphitePort: Int) {
val kafkaConsumer = new KafkaConsumer[String, String](kafkaProperties)
// 提交Offset
override def onQueryProgress(event: QueryProgressEvent): Unit = {
super.onQueryProgress(event)
// 遍历所有Source
event.progress.sources.foreach(source => {
val objectMapper = new ObjectMapper()
.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false)
.configure(DeserializationFeature.USE_LONG_FOR_INTS, true)
.registerModule(DefaultScalaModule)
val endOffset = objectMapper.readValue(source.endOffset, classOf[Map[String, Map[String, Long]]])
// 遍历Source中的每个Topic
for ((topic, topicEndOffset) <- endOffset) {
val topicPartitionsOffset = new util.HashMap[TopicPartition, OffsetAndMetadata]()
//遍历Topic中的每个Partition
for ((partition, offset) <- topicEndOffset) {
val topicPartition = new TopicPartition(topic, partition.toInt)
val offsetAndMetadata = new OffsetAndMetadata(offset)
topicPartitionsOffset.put(topicPartition, offsetAndMetadata)
}
kafkaConsumer.commitSync(topicPartitionsOffset)
}
})
}
}
Spark-StructuredStreaming 下的checkpointLocation分析以及对接 Grafana 监控和提交Kafka Lag 监控的更多相关文章
- Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就standalone部署方式下的容错性问题做比较细致的分析,主要回答standalone部署方式下的包含哪些主要节点,当某一类节点出现问题时,系统是如 ...
- Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续)
Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续) 今天延续昨天的内容,主要对为什么一个处理会分解成多个Job执行进行解析. 让我们跟踪下Job调用过 ...
- Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析
Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析 今天通过集群运行模式观察.研究和透彻的刨析SparkStreaming的日志和web监控台. Day28 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(二)
本文由 网易云发布. 本文内容接上一篇Apache 流框架 Flink,Spark Streaming,Storm对比分析(一) 2.Spark Streaming架构及特性分析 2.1 基本架构 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(2)
此文已由作者岳猛授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 2.Spark Streaming架构及特性分析 2.1 基本架构 基于是spark core的spark s ...
- spark structured-streaming 最全的使用总结
一.spark structured-streaming 介绍 我们都知道spark streaming 在v2.4.5 之后 就进入了维护阶段,不再有新的大版本出现,而且 spark strea ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- 【原】Spark中Master源码分析(一)
Master作为集群的Manager,对于集群的健壮运行发挥着十分重要的作用.下面,我们一起了解一下Master是听从Client(Leader)的号召,如何管理好Worker的吧. 1.家当(静态属 ...
随机推荐
- WPF进阶技巧和实战08-依赖属性与绑定02
将元素绑定在一起 数据绑定最简单的形式是:源对象是WPF元素而且源属性是依赖项属性.依赖项属性内置了更改通知支持,当源对象中改变依赖项属性时,会立即更新目标对象的绑定属性. 元素绑定到元素也是经常使用 ...
- 分布式锁Redission
Redisson 作为分布式锁 官方文档:https://github.com/redisson/redisson/wiki 引入依赖 <dependency> <groupId&g ...
- FastAPI 学习之路(三)
系列文章: FastAPI 学习之路(一)fastapi--高性能web开发框架 FastAPI 学习之路(二) 之前的文章分享了如何去创建一个简单的路径的请求.那么我们这次分享的如何在请求路径中,增 ...
- 2020.3.28-ICPC训练联盟周赛,选用试题:UCF Local Programming Contest 2016
A.Majestic 10 签到题. #include<iostream> #include<cstdio> #include<cstring> #include& ...
- 初探JavaScript PDF blob转换为Word docx方法
PDF转WORD为什么是历史难题 PDF 转Word 是一个非常非常普遍的需求,可谓人人忌危,为什么如此普遍的需求,却如此难行呢,还得看为什么会有这样的一个需求: PDF文档遵循iOS32000的规范 ...
- 激活NX窗口的按钮
原理:取得按钮名称以后,通过运行宏文件激活按钮 Imports System.IO Imports System.Runtime.InteropServices Imports NXOpen.Menu ...
- 【UE4】GAMES101 图形学作业1:mvp 模型、视图、投影变换
总览 到目前为止,我们已经学习了如何使用矩阵变换来排列二维或三维空间中的对象.所以现在是时候通过实现一些简单的变换矩阵来获得一些实际经验了.在接下来的三次作业中,我们将要求你去模拟一个基于CPU 的光 ...
- OSI参考模型(应用层、表示层、会话层、传输层、网络层、数据链路层、物理层)
文章转自:https://blog.csdn.net/weixin_43914604/article/details/104589085 学习课程:<2019王道考研计算机网络> 学习目的 ...
- 攻防世界 web4.cookie
题有几种解法,我有点懒,懒的打开burp,所以可以直接在浏览器拿flag, 首先访问ip/cookie.php,提示:See the http response 接着F12查看响应头 给你cyberp ...
- 21.6.21 test
\(NOI\) 模拟赛 字符串滚出 \(OI\) 看到题目名称,\(T1\) 串,\(T2\) 两个串,\(T3\) K个串,我 \(\cdots\),血压已经上来了. \(T1\) 写了 \(O(n ...