提问式复习:图文回顾 redo log 相关知识
原文链接:提问式复习:图文回顾 redo log 相关知识
1、如何提升 redo日志 的写性能?
- 为了保证 redo日志 不丢失,会在磁盘中开辟一块空间将日志保存起来。但是这样会有一个问题,磁盘的读写性能非常的差。
- 所以 redo日志 和数据页一样,系统都是会分配一块连续的内存,来提升读写性能;数据页对应的是 buffer pool,而 redo日志 对应的是 log buffer。
buffer pool可以利用「innodb_buffer_pool_size」指定总大小,利用「innodb_buffer_pool_instances」指定实例数,但是必须size大于等于1G才生效。
log buffer 可利用「innodb_log_buffer_size」指定 log buffer 的大小;一片连续的内存空间会被划分为N个512字节大小的block。
log file 可以利用「innodb_log_file_size」指定每个 log file 的大小,利用「innodb_log_files_in_group」指定一共多少个log file。
2、redo日志 何时写入log buffer?
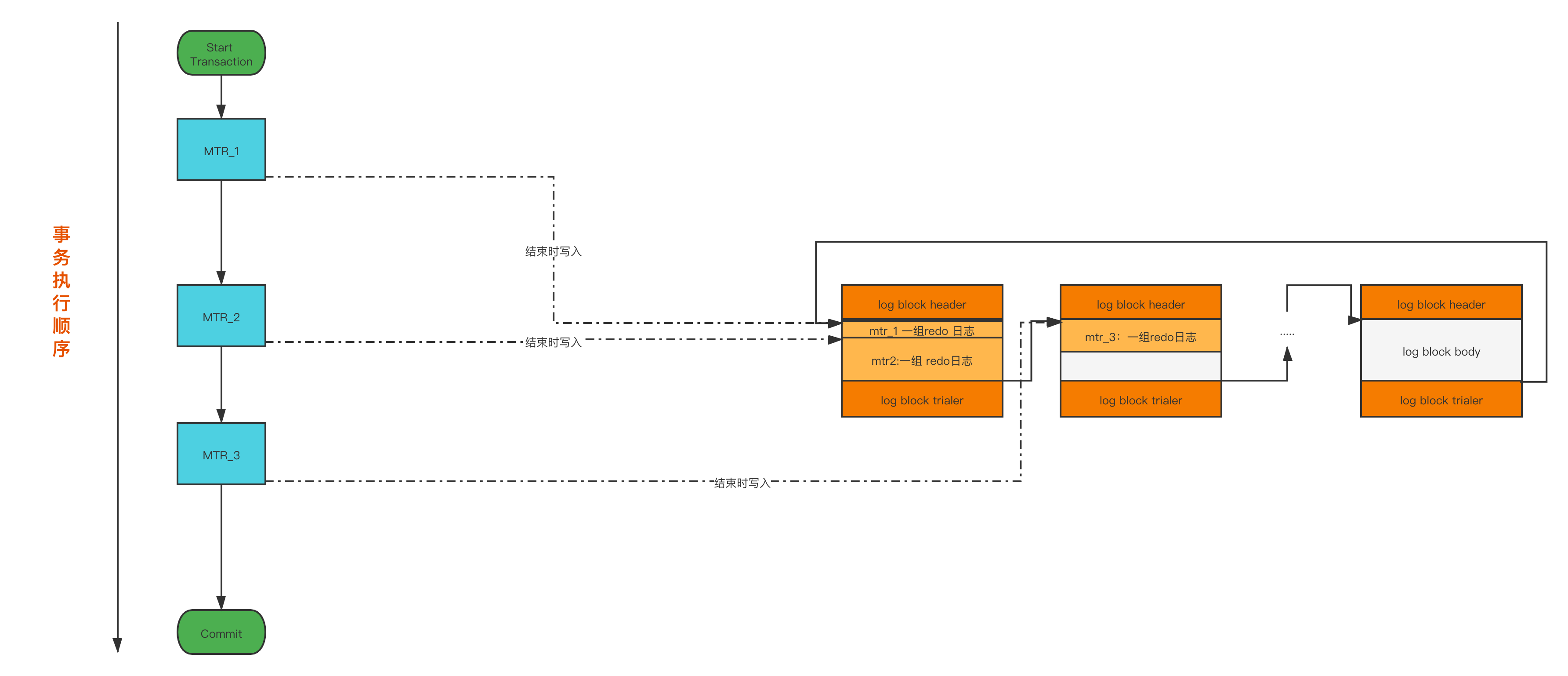
- 对底层页面(可能是多个页面)进行一次原子性访问,等于一个MTR,即 Mini Transaction。一个 MTR对应一组 redo日志 。一个事务对应多个语句,一个语句对应多个个MTR,一个MTR对应一组redo日志,即多个 redo日志 。
- 在MTR结束后,会将一组 redo日志 写入到log buffer中。
详情可看下图:
3、log buffer 中的 redo日志 何时刷盘?
- 当 log buffer 已经被写入约一半左右,下次再写入 redo日志 时,需将 log buffer 的 redo日志 刷到磁盘文件中。
- 当事务结束时,需先将 log buffer 中,被修改的缓存页对应的 redo日志 刷回磁盘中。
- 后台线程刷,大概每隔一秒刷一次 log buffer 中的 redo日志 到磁盘中。
- 执行checkpoint。
- 正常关闭服务器。
4、我们都知道每次写入 redo日志 ,都是以组为单位,那么我们怎么知道哪些是一组?
- 在该组中的最后一条 redo日志 后边加上一条特殊类型的 redo日志 ,该类型名称为「MLOG_MULTI_REC_END」,type字段对应的十进制数字为31,该类型的 redo日志 结构很简单,只有一个type字段。
5、如何知道下一次redo日志改写到log buffer的哪个位置?
- buf_free全局变量,指向log buffer中下个写入的位置。
6、如何知道下次从log buffer的哪个位置开始刷入磁盘?
- buf_next_to_write全局变量,指向log buffer中下个刷回磁盘的位置。
7、如何定位 log buffer 中的 redo日志 对应哪些被修改的数据页;在被修改的数据页中,如何定位到对应的是哪些 redo日志 ?
- 修改的缓存页找到对应的 redo日志
- lsn
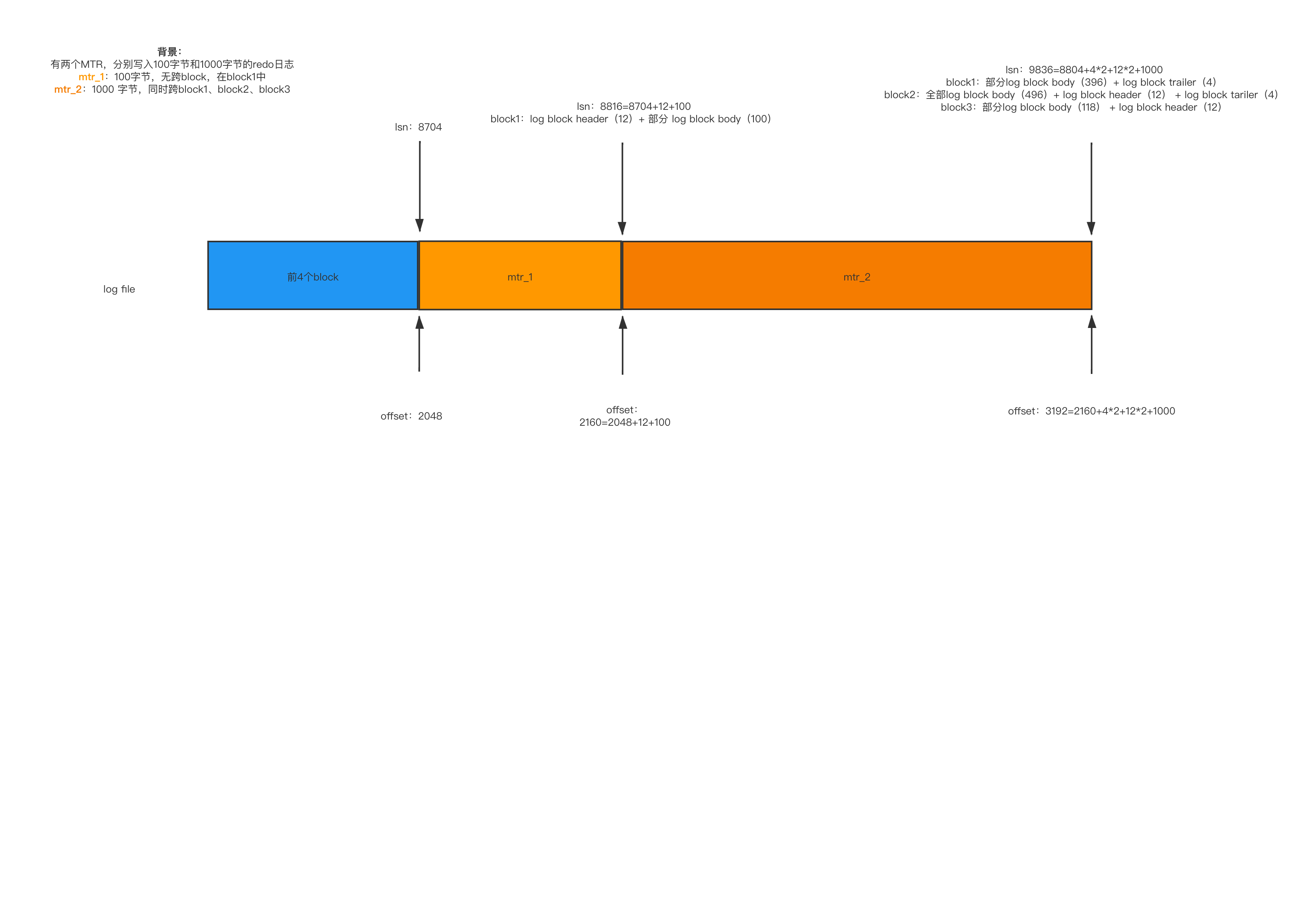
- 首先,出场一个变量,叫lsn,全称:log sequence number,日志序列号。它记录的是,redo日志 的总字节数,初始值为8704。当系统启动,初始化log buffer 时,lsn 值为 8704+12(一个log block header)=8716
- 接着,log buffer 是由多个block组成的(可以理解为buffer pull的缓存页),block由三部分组成,log block header(12个字节)、log block body、log block trailer(4个字节)。
- 当第一个 redo日志 组,如「mt_1」准备被写入,并且一个block能容纳,此时lsn为 8704+12(一个log block header)=8716,假设「mt_1」一共100字节,那么「mt_1」写入后,lsn为8716+100=8816
- 当第二个 redo日志 组,如「mt_2」准备被写入,并且需要跨block才能容纳,如跨一个(即包含一个log block header和一个log block trailer),开始写入前lsn:8816,假设「mt_2」一共1000个字节,那么「mt_2」写入后,lsn为8816+12(一个log header)+4(一个log tail)+1000=9832
- flush和lsn
- 当 MTR 结束时,会将被修改过的数据页对应的数据块放入 flush链表 的表头中,并且给两个参数赋值,分别是 old_modification 和 new_modification:old_m 赋值是 MTR 开始前的 lsn 值,而 new_m 赋值是 MTR 结束时的 lsn 值。
- 如果一个 MTR 修改的数据页对应的控制块本来就在 flush链表 中,则不调整数据页对应的数据块的位置,只是修改 new_modification 的值,old_modification还 是保持第一次进入 flush链表 时 lsn 的值。
- 就是说,在 flush链表 中,数据块是根据第一次修改的时间进行倒序排列的。
- 通过上面,那么我们可以根据flush链表中,数据块的 old_modification 和 new_modification 找到对应的一组 redo日志 ,因为通过 lsn 可以定位到对应 redo日志 在磁盘文件中的偏移量(这个下面会讲解到)。
- lsn
- redo日志 找到对应的缓存页面
- redo日志 的通用结构是:type-spaceId ID-page Number-data,即我们可以根据 redo日志 的 space ID 和 page Number 即可找到对应的缓存页。
- 顺带一提:在 InnoDB 中,有一个哈希表,key为表空间号+页号,value为缓存页地址。这样我们可以通过 space ID 和 page Number 快速定位到对应的缓存页。
8、我们知道可以利用 lsn 知道有多少字节数的 redo日志 写入到 log buffer 中,那么我们能有变量对应的知道有多少字节数的 redo日志 被刷入磁盘中吗?
- flushed_to_disk_lsn 全局变量,表示刷到磁盘的日志量。
9、lsn 和 log file 的偏移量怎么对得上么?
- lsn 初始值是 8704,随着 redo日志 的不断写入,lsn 不断增大。而 innodb 中,是利用 block 这个结构来存储 redo日志 (不管是 log buffer 还是 log file),而 block 包含三部分,上面已经提到。当 redo日志 不断写入,不断占用 block 的空间,那么 lsn 会增加对应的字节数,当然了,除了body、也算 header 和 trailer。
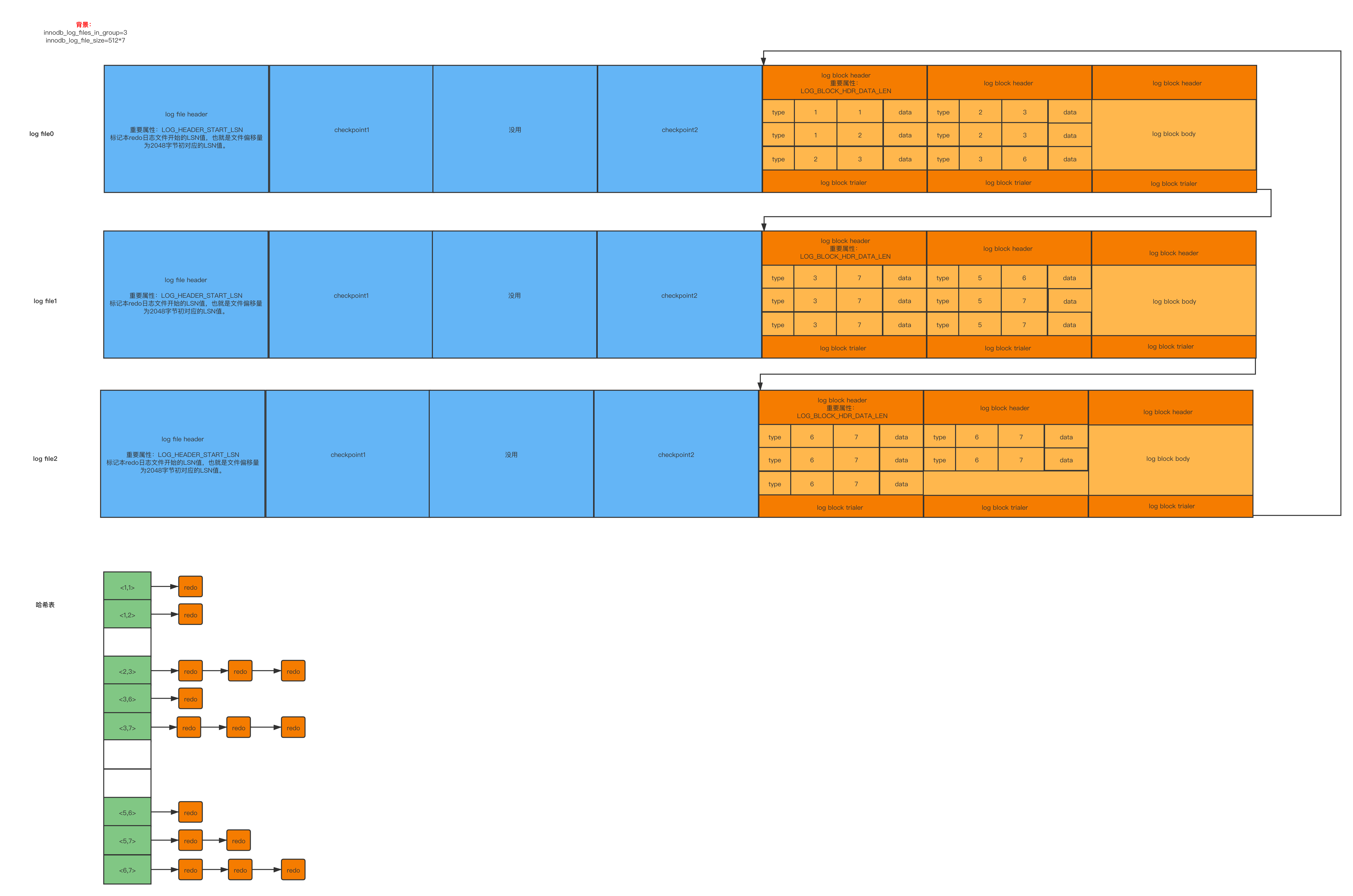
- log file 是由日志组组成,日志组最大设置100个文件数,每个日志文件也是由多个512字节的block镜像组成,日志组第一个日志文件前4个block镜像用于存储重要信息、如checkpoint等、即前2048个字节不用于存储 redo日志 ,即从2048个字节开始计算 redo日志 的存放量。
- log file 的 log file header 中有一个「LOG_HEADER_START_LSN」属性,标记本 redo日志 文件偏移量2048字节处对应的lsn值。
详情可看下图:
10、log buffer 中的 redo日志 真的会在事务结束时立马刷回到磁盘中吗?
- 默认是的,这里有一个参数控制:「innodb_flushing_log_at_trx_commit」,默认值是1
- 0:事务提交,不会立马刷到磁盘中,依赖后台线程刷入,即如果此时MySQL或系统挂掉重启,无法恢复脏页
- 1:事务提交,会立马将log buffer的 redo日志 刷回磁盘中
- 2:事务提交,会立马将log buffer的 redo日志 刷到操作系统的缓存中,而不是刷到磁盘中;如果此时MySQL挂掉了,重启后不会影响恢复脏页,而如果是系统挂掉,就无力回天了。
11、log file 都是循环使用,即可以覆盖,那么怎么判断是否可以覆盖?
- log file 中可被覆盖,那么首要条件就是 redo日志 对应的脏页已经被刷到磁盘中。
- innodb 有个全局变量:checkpoint_lsn,它记录的是可被覆盖的 redo日志量。初始值就是lsn的初始值,8704。
- 什么是 checkpoint?
- 当有脏页被刷到磁盘时,首先在flus链表中拿到最旧的缓存页,即需要拿到链表尾部的控制块,然后拿到 old_modification 的值,然后将这个值赋值给 checkpoint_lsn,因为只要是小于 flush 链表中最旧的控制块的 old_modification 的 lsn,就代表可以被覆盖,毕竟对应的脏页已经被刷到磁盘中了。
- 接着,将根据当前的 checkpoint_lsn 获取对应日志文件组的偏移量,记录为 checkpoint_offset,checkpoint_no 也需要加1,最后将三个信息记录在日志文件组的 checkpoint1 或 checkpoint2(checkpoint_no为奇数存1,否则存2)。
- 上面两步称为执行一次checkpoint。
- 什么是 checkpoint?
- 我们只需要从日志文件组中的 checkpoint1 和 checkpoint2 拿到信息,然后对比 checkpoint_no 看哪个是最新的,接着拿到checkpoint_lsn,那么 lsn 小于 checkpoint_lsn 的日志都可以被覆盖。
12、系统崩溃重启,如何利用 redo日志 进行恢复?
- redo日志 进行崩溃恢复主要是利用上面提到的 checkpoint_lsn,因为 checkpoint_lsn 表示可以覆盖的日志量,则表示 checkpoint_lsn 之前的 redo日志 对应的脏页都已经被刷回到磁盘中。
- 首先从 redo 日志组中拿到 checkpoint1 和 checkpoint2,接着判断谁的 checkpoint_no 大,大的就是最新的一次 checkpoint 执行。
- 接着拿到对应的 checkpoint_offset,那么 checkpoint_offset 后的 redo日志 都需要扫描一遍,然后根据 redo日志 的内容,对数据页进行恢复。
13、恢复是扫描一个 redo日志 ,就进行一次恢复吗?
- 问题:
- 因为根据 redo日志 恢复数据页的变更,是直接更新磁盘中的数据页;扫描一个 redo日志 ,就进行一次恢复,如果存在多个 redo日志 记录同一个数据页的变更,并且不是连续的,那么会导致多次随机IO,性能会非常的差。
- 解决:
- 所以会有一个哈希表,key为 space ID + page Number,value 为数据页地址。扫描 redo日志 时,会将同一个 space ID + page Number 的 redo日志 都放在同一个槽下。
- 接着遍历哈希表,执行每一个 space ID + page Number 对应所有的 redo日志 。
- 好处:
- 避免了多次的随机IO,提升恢复的速度。
- 按顺序根据 redo日志 进行恢复,避免出现恢复的顺序问题。
详情可看下图:
14、恢复时,如何知道什么时候结束?
- 首先,我们知道,在日志组里,有多个block镜像,然后 redo日志 刷盘,是按顺序填入每个block的,只有前一个block填满了,才接着填下一个
- 接着,每个 block 的大小都是 512 个字节,包括 log block header、log block body 和 log block trailer。在block的页面结构中,log block header 头部有一个「LOG_BLOCK_HDR_DATA_LEN」的属性,该属性值记录了当前block里使用了多少字节的空间。对于被填满的block来说,该值永远为512。
- 最后,所以只管往后面一直扫,直到 log block header 中 「LOG_BLOCK_HDR_DATA_LEN」属性不是512的 block,那么就是恢复的终点了。
15、如何兼容脏页已经已经刷回磁盘,但是 redo日志 没有刷回磁盘的场景?
- 场景复现:
- 当我们提交事务时,会根据参数「innodb_flush_at_trx_commit」来做下一步操作,如果是0或者2,那么此时的日志并没有刷回到磁盘中,而是留在log buffer中或操作系统缓存中。
- 接着,如果有后台线程将 LRU 链表或 flush 链表的某些脏页刷回磁盘中,刷回后;但是此时对应的 redo日志 还停留在上面提到的两个地方,如果服务器宕机,那么对应的 redo日志 就会丢失了。
- 因为刷 LRU 链表、flush 链表和刷 redo日志 的后台线程,往往都是不同的线程,无法知道对应的 redo日志 是否已经刷回去。
- 兼容:
- 每个数据页都有一个称之为 File Header 的部分,在 File Header 里有一个称之为 FIL_PAGE_LSN 的属性,该属性记载了最近一次修改页面时对应的 lsn 值(其实就是页面控制块中的 newest_modification 值)。
- 如果在做了某次 checkpoint 之后有脏页被刷新到磁盘中,那么该页对应的 FIL_PAGE_LSN 代表的 lsn 值肯定大于 checkpoint_lsn 的值,凡是符合这种情况的页面就不需要重复执行 lsn 值小于 FIL_PAGE_LSN 的 redo日志 了,
最后,祝大家国庆节快乐!
提问式复习:图文回顾 redo log 相关知识的更多相关文章
- MySQL学习总结:提问式回顾 undo log 相关知识
原文链接:MySQL学习总结:提问式回顾 undo log 相关知识 1.redo 日志支持恢复重做,那么如果是回滚事务中的操作呢,也会有什么日志支持么? 也回滚已有操作,那么就是想撤销,对应的有撤销 ...
- MySQL中Redo Log相关的重要参数总结
参数介绍 下面介绍.总结一下MySQL的Redo Log相关的几个重要参数:innodb_log_buffer_size.innodb_log_file_size.innodb_log_files ...
- redo log
1.redo log相关数据字典 v$log:display the redo log file information from the control file v$logfile:identif ...
- MySQL redo log及recover过程浅析
写在前面:作者水平有限,欢迎不吝赐教,一切以最新源码为准. InnoDB redo log 首先介绍下Innodb redo log是什么,为什么需要记录redo log,以及redo log的作用都 ...
- zz MySQL redo log及recover过程浅析
原作地址:http://www.cnblogs.com/liuhao/p/3714012.html 写在前面:作者水平有限,欢迎不吝赐教,一切以最新源码为准. InnoDB redo log 首先介绍 ...
- MySQL如何计算统计redo log大小
在MySQL中如何计算.统计重做日志(redo log)的生成情况呢? 例如10分钟内,生成了多少M的redo log呢?30分钟内又生成了多少M的redo log......MySQL没有像Or ...
- 说说MySQL中的Redo log Undo log都在干啥
在数据库系统中,既有存放数据的文件,也有存放日志的文件.日志在内存中也是有缓存Log buffer,也有磁盘文件log file,本文主要描述存放日志的文件. MySQL中的日志文件, ...
- 详细分析MySQL事务日志(redo log和undo log)
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- 【转】说说MySQL中的Redo log Undo log都在干啥
阅读目录(Content) 1 undo 1.1 undo是啥 1.2 undo参数 1.3 undo空间管理 2 redo 2.1 redo是啥 2.2 redo 参数 2.3 redo 空间管理 ...
随机推荐
- C# 中的异步问题 Task
public class SharedData { public int Value { get; set; } } public class Test { async Task ModifyValu ...
- jQuery中ajax请求的六种方法(三、四):$.getJSON()方法
4.$.getJSON()方法 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"&g ...
- vmware 配置不同网段双网卡。
一.前言 需求:由于LVS演练需要,需要配置两张linux OS网卡,而且是不同网段. 准备: 物理机:单网卡 VMware:centos 6.8 二.配置 第一步:新建虚拟机VMware,cento ...
- linux》centos6.1.环境下发送邮件设置
转自https://blog.csdn.net/bodybo/article/details/80817968 一. Sendmail安装 在CentOS下,sendmail一般默认是随操作系统一起安 ...
- 整理之Activity
基础 生命周期 执行层次 进 退 创建与销毁 onCreate() onDestroy() 是否可见 onStart() onStop() 是否在前台(可交互) onResume() onPause( ...
- ELK学习之Logstash篇
Logstash在ELK这一整套解决方案中作为数据采集终端,支持对接Kafka.数据库(MySQL.Oracle).文件等等. 而在Logstash内部的数据流转,主要经过三个环节:input -&g ...
- Python - 面向对象编程 - 什么是对象和类
面向对象编程 Object Oriented Programming,简称 OOP,是一种程序设计思想 OOP 把对象作为程序的基本单元,一个对象包含了数据和操作数据的方法 Python里面有一句话: ...
- 解决CSDN文章下载后,依然请求跳转至首页出错的问题
1. 搜索关键字:"onerror" 然后找到如下所示代码: <div style="display:none;"> <img ...
- uniapp 获取用户手机号
参考资料: 微信小程序官方文档 uniapp开发微信小程序获取用户手机号 页面增加一个按钮 <button open-type="getPhoneNumber" @getph ...
- 判断input radio选中那个
var _sex=$("input[name='sex']:checked").val(); if(_sex==null){ layer.msg("请选择性别" ...