机器学习--支持向量机 (SVM)算法的原理及优缺点
一、支持向量机 (SVM)算法的原理
支持向量机(Support Vector Machine,常简称为SVM)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析。它是将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。
1.支持向量机的基本思想
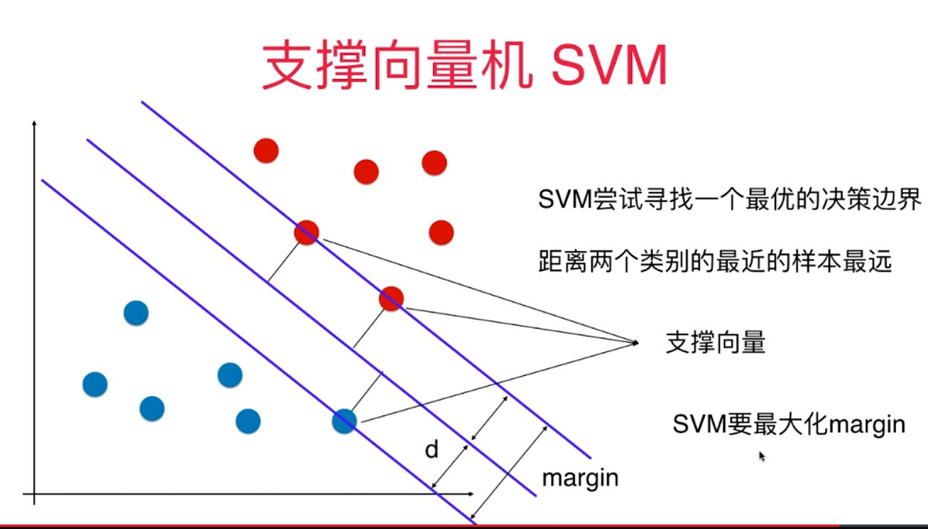
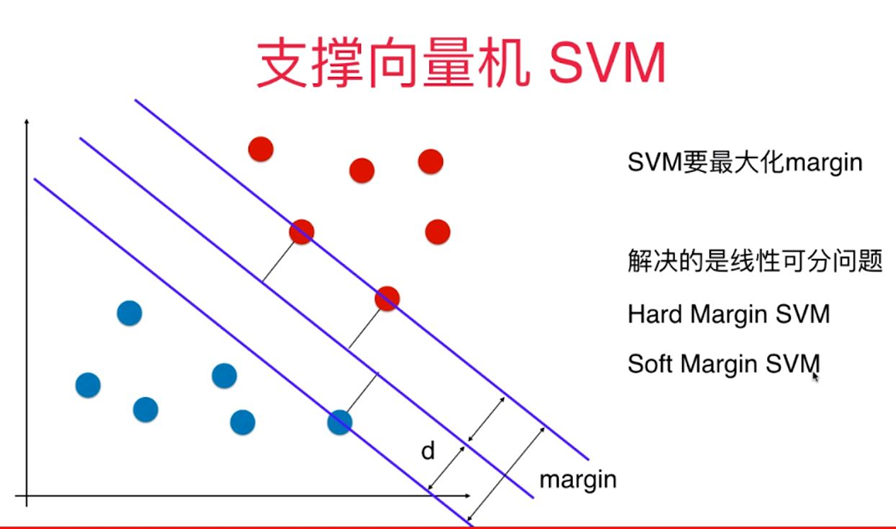
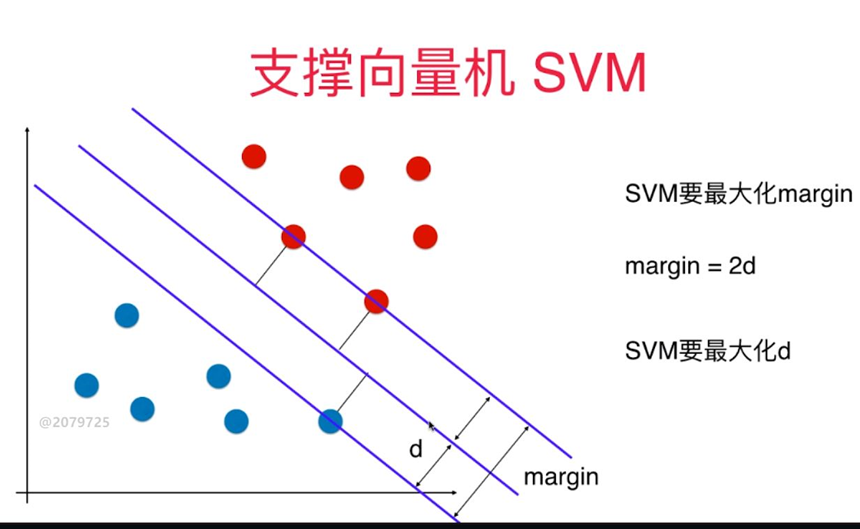
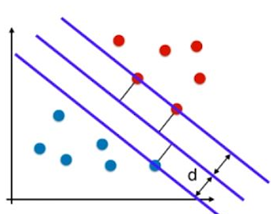
对于线性可分的任务,找到一个具有最大间隔超平面,如图所示,
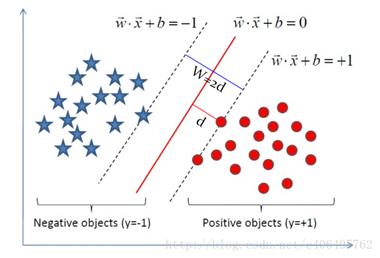
(1)支持向量机的基本型为:
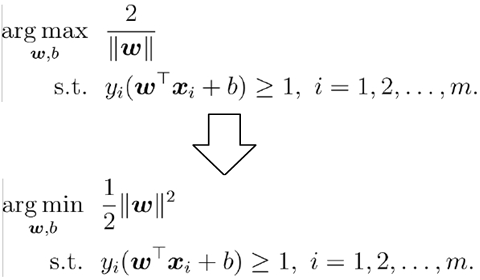
(2)软间隔的优化目标:
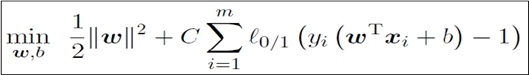
其中,0-1函数为错分样本的个数。
(3)核方法:
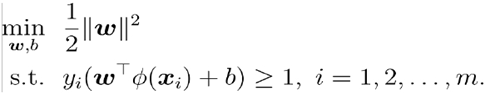
其中为特征映射函数。
2、实验一般步骤:
(1)导入数据;
(2)数据归一化;
(3)执行svm寻找最优的超平面;
(4)绘制分类超平面核支持向量;
(5)利用多项式特征在高维空间中执行线性svm
(6)选择合适的核函数,执行非线性svm;
3、算法优缺点:
算法优点:
(1)使用核函数可以向高维空间进行映射
(2)使用核函数可以解决非线性的分类
(3)分类思想很简单,就是将样本与决策面的间隔最大化
(4)分类效果较好
算法缺点:
(1)SVM算法对大规模训练样本难以实施
(2)用SVM解决多分类问题存在困难
(3)对缺失数据敏感,对参数和核函数的选择敏感
二、数学推导过程
对于线性可分的支持向量机求解问题实际上可转化为一个带约束条件的最优化求解问题:
推理过程:

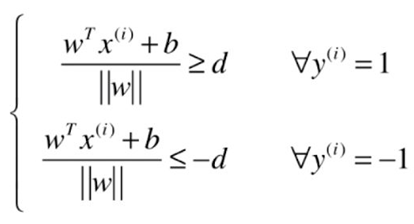

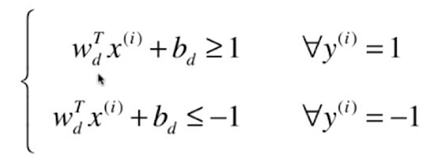
结果:

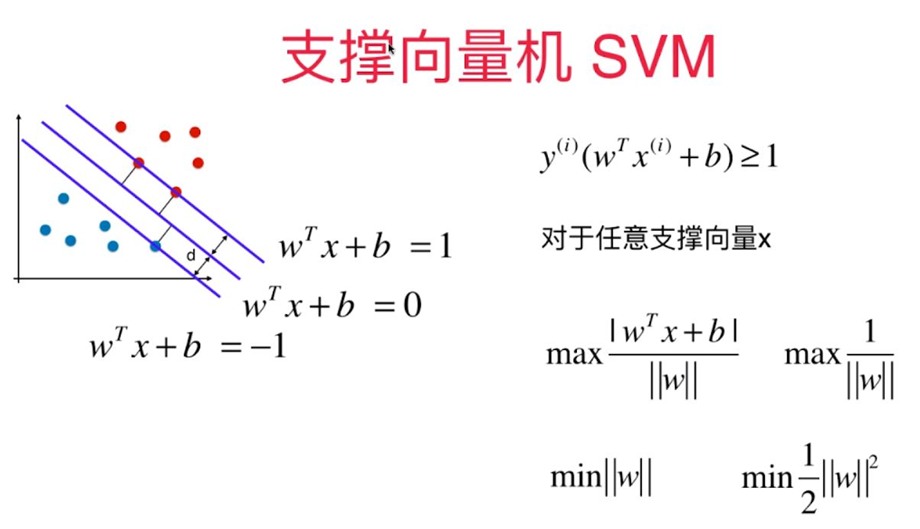
对于线性不可分的支持向量机求解问题实际上可转化为一个带约束条件的soft-margin最优化求解问题:
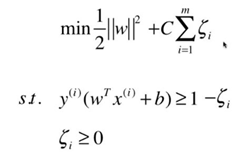
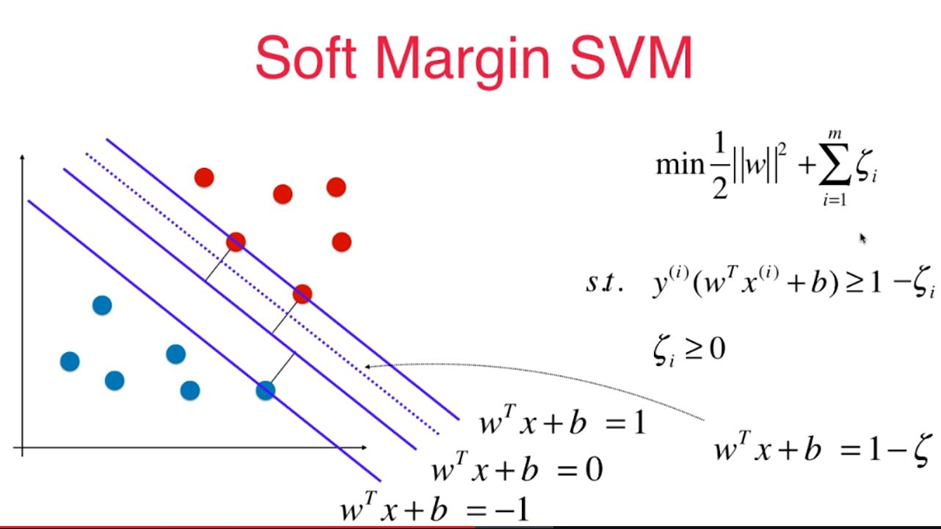
三、代码实现
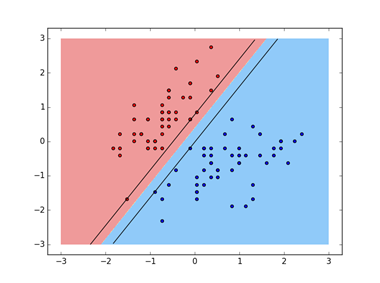
1、线性svm
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
from matplotlib.colors import ListedColormap
import warnings def plot_decision_boundary(model,axis):
x0,x1=np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1)
)
x_new=np.c_[x0.ravel(),x1.ravel()]
y_predict=model.predict(x_new)
zz=y_predict.reshape(x0.shape)
custom_cmap=ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_cmap) w = model.coef_[0]
b = model.intercept_[0]
plot_x = np.linspace(axis[0],axis[1],200)
up_y = -w[0]/w[1]*plot_x - b/w[1] + 1/w[1]
down_y = -w[0]/w[1]*plot_x - b/w[1] - 1/w[1]
up_index = (up_y>=axis[2]) & (up_y<=axis[3])
down_index = (down_y>=axis[2]) & (down_y<=axis[3])
plt.plot(plot_x[up_index],up_y[up_index],c='black')
plt.plot(plot_x[down_index],down_y[down_index],c='black')
warnings.filterwarnings("ignore")
data = load_iris()
x = data.data
y = data.target
x = x[y<2,:2]
y = y[y<2] scaler = StandardScaler()
scaler.fit(x)
x = scaler.transform(x)
svc = LinearSVC(C=1e9)
svc.fit(x,y) plot_decision_boundary(svc,axis=[-3,3,-3,3])
plt.scatter(x[y==0,0],x[y==0,1],c='r')
plt.scatter(x[y==1,0],x[y==1,1],c='b')
plt.show()
输出结果:
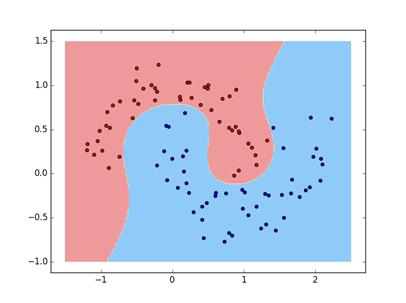
2、非线性-多项式特征
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
from matplotlib.colors import ListedColormap
import warnings def plot_decision_boundary(model,axis):
x0,x1=np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1)
)
x_new=np.c_[x0.ravel(),x1.ravel()]
y_predict=model.predict(x_new)
zz=y_predict.reshape(x0.shape)
custom_cmap=ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_cmap) def PolynomialSVC(degree,C=1.0):
return Pipeline([
('poly',PolynomialFeatures(degree=degree)),
('std_scaler',StandardScaler()),
('linearSVC',LinearSVC(C=1e9))
]) warnings.filterwarnings("ignore")
poly_svc = PolynomialSVC(degree=3)
X,y = datasets.make_moons(noise=0.15,random_state=666)
poly_svc.fit(X,y)
plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1],c='red')
plt.scatter(X[y==1,0],X[y==1,1],c='blue')
plt.show()
输出结果:
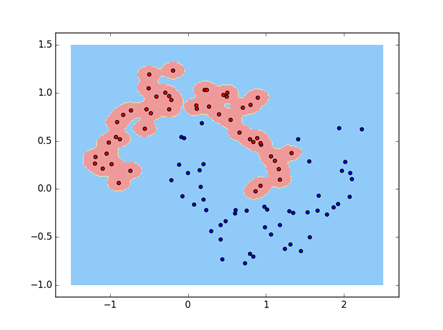
3、非线性-核方法
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn import datasets
from matplotlib.colors import ListedColormap
import numpy as np
import matplotlib.pyplot as plt
import warnings
def plot_decision_boundary(model,axis):
x0,x1=np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1)
)
x_new=np.c_[x0.ravel(),x1.ravel()]
y_predict=model.predict(x_new)
zz=y_predict.reshape(x0.shape)
custom_cmap=ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0,x1,zz,linewidth=5,cmap=custom_cmap)
def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
warnings.filterwarnings("ignore")
X,y = datasets.make_moons(noise=0.15,random_state=666)
svc = RBFKernelSVC(gamma=100)
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1],c='red')
plt.scatter(X[y==1,0],X[y==1,1],c='blue')
plt.show()
输出结果:
机器学习--支持向量机 (SVM)算法的原理及优缺点的更多相关文章
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 机器学习——支持向量机SVM
前言 学习本章节前需要先学习: <机器学习--最优化问题:拉格朗日乘子法.KKT条件以及对偶问题> <机器学习--感知机> 1 摘要: 支持向量机(SVM)是一种二类分类模型, ...
- 4、2支持向量机SVM算法实践
支持向量机SVM算法实践 利用Python构建一个完整的SVM分类器,包含SVM分类器的训练和利用SVM分类器对未知数据的分类, 一.训练SVM模型 首先构建SVM模型相关的类 class SVM: ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 机器学习笔记—svm算法(上)
本文申明:本文原创,如转载请注明原文出处. 引言:上一篇我们讲到了logistic回归,今天我们来说一说与其很相似的svm算法,当然问题的讨论还是在线性可分的基础下讨论的. 很多人说svm是目前最好的 ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 机器学习--K近邻 (KNN)算法的原理及优缺点
一.KNN算法原理 K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法. 它的基本思想是: 在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对 ...
随机推荐
- 计算机组成原理——I/O接口以及I/O设备数据传送控制方式
接口可以看作是两个部件之间交接的部分.硬件与硬件之间有接口,硬件与软件之间有接口,软件与软件之间也有接口. 这里我们所说的I/O接口,一边连接着主机,一边连接着外设. I/O接口的功能 I/O接口的基 ...
- Consul初探-集成ocelot
前言 由于 Consul 的高可用性.丰富的API.友好的 Web 控制台界面等特点,Consul 的发展非常迅猛,得益于 .NETCore 社区的快速发展和社区成员的贡献,我们现在可以非常方便快速的 ...
- django中使用原生的sql查询实例
在app文件夹下创建database_operations.py文件,写如下内容: import pymysql from 项目名.settings import DATABASES class Da ...
- .NET种Json时对单引号和特殊字符串的处理
转自:https://www.cnblogs.com/ITniao/archive/2011/01/06/1929261.html .NET种Json时对单引号和特殊字符串的处理 在Asp.NET ...
- iOS----------componentsJoinedByString 和 componentsSeparatedByString 的方法的区别
将string字符串转换为array数组 NSArray *array = [Str componentsSeparatedByString:@","]; ==反向方法 将arr ...
- 前端开发规范:4-JS
ESLint 使用ESLint的standard规范来编写js代码 更多参考: https://github.com/standard/standard/blob/master/docs/README ...
- 初级模拟电路:3-11 BJT实现电流源
回到目录 1. 恒流源 (1)简易恒流源 用BJT晶体管可以构造一个简易的恒流源,实现电路如下: 图3-11.01 前面我们在射极放大电路的分压偏置时讲过,分压偏置具有非常好的稳定性,几乎不受晶体管的 ...
- Paint.NET软件分享
date: 2019-07-26 下载链接 官网链接 这是一款类Photoshop的轻量级图片编辑软件,仅有8.7MB.不多说话,直接上链接. 百度网盘链接 提取码:v4b2 软件简介 (百度百科警告 ...
- BZOJ2820/LG2257 YY的GCD 莫比乌斯反演
问题描述 BZOJ2820 LG2257 题解 求 \(\sum\limits_{i=1}^{n}{\sum\limits_{j=1}^{m}{[gcd(i,j)==p]}}\) ,其中 \(p\)为 ...
- [译]Vulkan教程(06)验证层
[译]Vulkan教程(06)验证层 What are validation layers? 什么是验证层? The Vulkan API is designed around the idea of ...