Python数据结构性能分析
1.目标
告诉大家Python列表和字典操作的 大O 性能。然后我们将做一些基于时间的实验来说明每个数据结构的花销和使用这些数据结构的好处
2.实操
在列表的操作有一个非常常见的编程任务就是是增加一个列表。我们马上想到的有两种方法可以创建更长的列表,可以使用 append 方法或拼接运算符。但是这两种方法那种效率更高呢。这对你来说很重要,因为它可以帮助你通过选择合适的工具来提高你自己的程序的效率。
- 实例化一个空列表,然后将0-n范围的数据添加到列表中。(四种方式)
方式一:
def test01():
alist = []
for i in range(1000):
alist += i
return alist 方式二:
def test02():
alist = []
for i in range(1000):
alist.append(i)
return alist 方式三:
def test03():
return [i for i in range(1000)] 方式四:
def test04():
alist = list(range(1000))
return alist
-下面我们来使用timeit模块来计算上述方式的平均运行时长
- timeit 模块:该模块可以用来测试一段Python代码的运行速度/时长
- Timer类:该类是timeit模块中专门用于测试Python代码的执行速度/时长。原型为:class timeit.Timer(stmt='pass',setup='pass')。
- stmt参数:表示即将进行测试的代码块语句。
- setup参数:运行代码块语句时所需要的设置。
- timeit函数:timeit.Timer.timeit(number=100000),该函数返回代码块语句执行number次的平均耗时。
- 案例:
from timeit import Timer
#被测试的代码块
def func(n):
sum = 0
for i in range(0,100):
sum += i
print(sum) if __name__ == "__main__":
#参数2:因为参数1必须为字符串且表示的是即将被测试代码块函数的名字,因此参数2必须设置为执行参数1函数所需的设置
t = Timer('func(10)','from __main__ import func')
print(t.timeit(1000))
- timeit模块来计算上述四种方式的平均时长是多少
from timeit import Timer
def test01():
alist = []
for i in range(1000):
alist += [i]
return alist
def test02():
alist = []
for i in range(1000):
alist.append(i)
return alist
def test03():
return [i for i in range(1000)]
def test04():
alist = list(range(1000))
return alist
if __name__ == '__main__':
timer = Timer('test01()','from __main__ import test01')
t1 = timer.timeit(1000)
print(t1) timer2 = Timer('test02()','from __main__ import test02')
t2 = timer.timeit(1000)
print(t2) timer3 = Timer('test03()','from __main__ import test03')
t3 = timer.timeit(1000)
print(t3) timer4 = Timer('test04()','from __main__ import test04')
t4 = timer.timeit(1000)
print(t4) # 执行结果:
0.060362724815831825
0.058856628773583
0.05833806495468252
0.05742018511486435
注意:你上面看到的时间都是包括实际调用函数的一些开销,但我们可以假设函数调用开销在四种情况下是相同的,所以我们仍然得到的是有意义的比较。因此,拼接字符串操作需要 6.03毫秒并不准确,而是拼接字符串这个函数需要 6.03毫秒。你可以测试调用空函数所需要的时间,并从上面的数字中减去它。剩下的基于列表的其他操作大家也可以使用timeit进行平均耗时的测量计算。
- 列表的相关操作的方法都是被封装好的,我们没有必要对相关操作的底层算法时间进行分析,下面直接给出大家一张基于列表操作的时间复杂度的表,供大家参考:
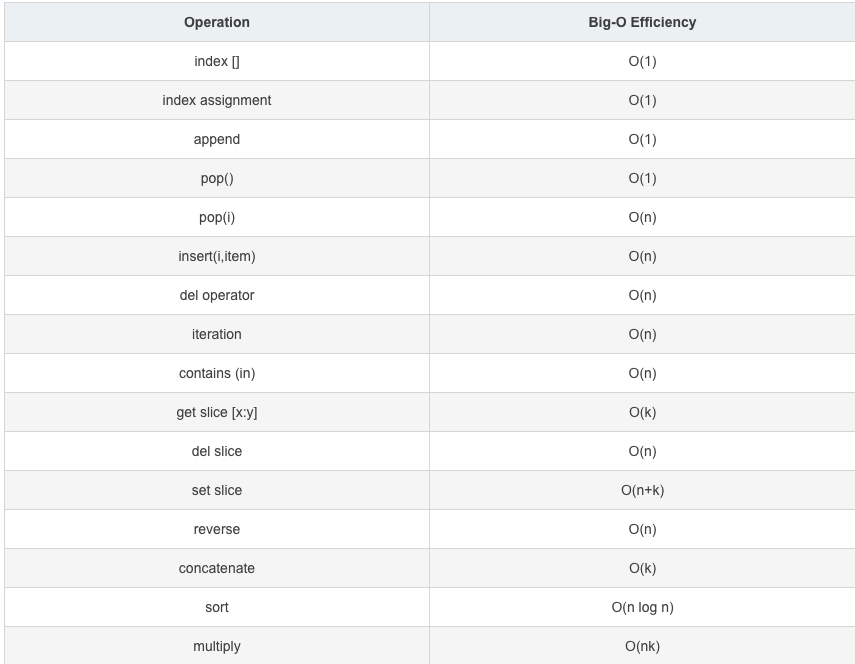
3. 字典
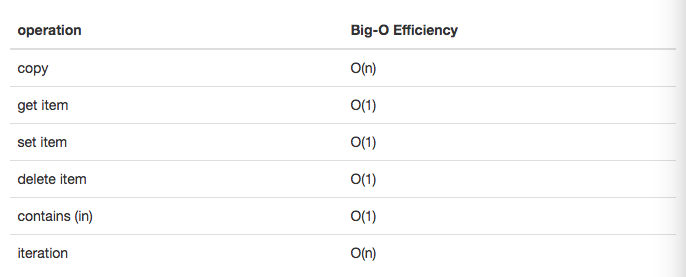
- python 中第二个主要的数据结构是字典。你可能记得,字典和列表不同,你可以通过键而不是位置来访问字典中的项目。
- 字典的时间复杂度:
Python数据结构性能分析的更多相关文章
- 关于python数据序列化的那些坑
-----世界上本来没那么多坑,python更新到3以后坑就多了 无论哪一门语言开发,都离不了数据储存与解析,除了跨平台性极好的xml和json之外,python要提到的还有自身最常用pickle模块 ...
- Python数据可视化编程实战——导入数据
1.从csv文件导入数据 原理:with语句打开文件并绑定到对象f.不必担心在操作完资源后去关闭数据文件,with的上下文管理器会帮助处理.然后,csv.reader()方法返回reader对象,通过 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据网络采集5--处理Javascript和重定向
Python数据网络采集5--处理Javascript和重定向 到目前为止,我们和网站服务器通信的唯一方式,就是发出HTTP请求获取页面.有些网页,我们不需要单独请求,就可以和网络服务器交互(收发信息 ...
- Python数据可视化——使用Matplotlib创建散点图
Python数据可视化——使用Matplotlib创建散点图 2017-12-27 作者:淡水化合物 Matplotlib简述: Matplotlib是一个用于创建出高质量图表的桌面绘图包(主要是2D ...
- Python数据可视化-seaborn库之countplot
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是s ...
- Python数据可视化编程实战pdf
Python数据可视化编程实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1vAvKwCry4P4QeofW-RqZ_A 提取码:9pcd 复制这段内容后打开百度 ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- 预测python数据分析师的工资
前两篇博客分别对拉勾中关于 python 数据分析有关的信息进行获取(https://www.cnblogs.com/lyuzt/p/10636501.html)和对获取的数据进行可视化分析(http ...
随机推荐
- Python爬虫之cookie的获取、保存和使用【新手必学】
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:huhanghao Cookie,指某些网站为了辨别用户身份.进行ses ...
- Python学习心得体会总结,不要采坑
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:樱桃小丸子0093 大家要持续关注哦,不定时更新Python知识 ...
- servlet读取请求参数后流失效的问题
在用reset接口的时候,常常会使用request.getInputStream()方法,但是流只能读取一次,一旦想要加上一个过滤器用来检测用户请求的数据时就会出现异常. 在过滤器中通过流读取出用户p ...
- 【Zuul】使用学习
[Zuul]使用学习 添加依赖 <dependency> <groupId>org.springframework.cloud</groupId> <arti ...
- java8新特性- 默认方法 在接口中有具体的实现
案例分析 在java8中在对list循环的时候,我们可以使用forEach这个方法对list进行遍历,具体代码如下demo所示 public static void main(String[] arg ...
- Django序列化时间报错
一.前言 当利用models模块从数据库获取数据时,当获的取数据序列化时,如果获取的数据中有关于时间类型的字段,则会报错,错误如下: TypeError: datetime.datetime(2018 ...
- Spring Cloud Alibaba 新一代微服务解决方案
本篇是「跟我学 Spring Cloud Alibaba」系列的第一篇, 每期文章会在公众号「架构进化论」进行首发更新,欢迎关注. 1.Spring Cloud Alibaba 是什么 Spring ...
- 人生苦短,我用Python(3)
1.对列表进行排序: (1)使用列表对象的sort()方法: 列表对象提供了sort()方法用于对原列表中的元素进行排序.排序后原列表中的元素顺序将发生改变.改变对象的sort()方法的语法格式如下: ...
- NodeJS2-3环境&调试----module.exports与exports的区别
exports默认会给他设置为module.exports的快捷方式,可以把它的里面添加属性,但是我们不能修改它的指向,如果修改了它的指向那它和普通对象没有任何区别了.因为在CommonJS中,模块对 ...
- SpringBoot内容聚合
分类整理一些内容,方便需要时回过头来看,整理不易,如有疏漏,请多担待!之后要查看这篇文章,公众号后台回复 “Springboot聚合” SpringBoot+Mybatis多模块(module)项目搭 ...