Spark学习之路(六)—— 累加器与广播变量
一、简介
在Spark中,提供了两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable):
- 累加器:用来对信息进行聚合,主要用于累计计数等场景;
- 广播变量:主要用于在节点间高效分发大对象。
二、累加器
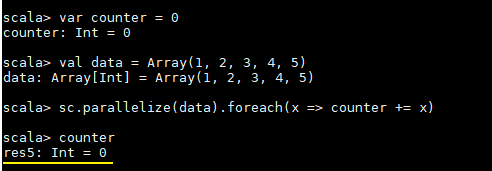
这里先看一个具体的场景,对于正常的累计求和,如果在集群模式中使用下面的代码进行计算,会发现执行结果并非预期:
var counter = 0
val data = Array(1, 2, 3, 4, 5)
sc.parallelize(data).foreach(x => counter += x)
println(counter)
counter最后的结果是0,导致这个问题的主要原因是闭包。
2.1 理解闭包
1. Scala中闭包的概念
这里先介绍一下Scala中关于闭包的概念:
var more = 10
val addMore = (x: Int) => x + more
如上函数addMore中有两个变量x和more:
- x : 是一个绑定变量(bound variable),因为其是该函数的入参,在函数的上下文中有明确的定义;
- more : 是一个自由变量(free variable),因为函数字面量本生并没有给more赋予任何含义。
按照定义:在创建函数时,如果需要捕获自由变量,那么包含指向被捕获变量的引用的函数就被称为闭包函数。
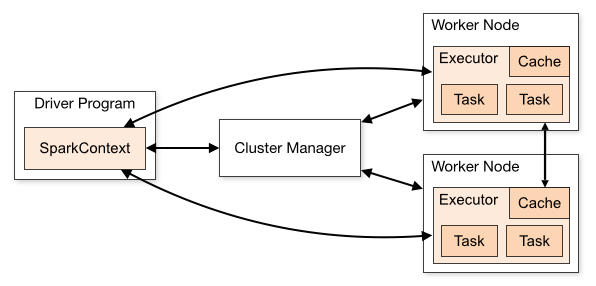
2. Spark中的闭包
在实际计算时,Spark会将对RDD操作分解为Task,Task运行在Worker Node上。在执行之前,Spark会对任务进行闭包,如果闭包内涉及到自由变量,则程序会进行拷贝,并将副本变量放在闭包中,之后闭包被序列化并发送给每个执行者。因此,当在foreach函数中引用counter时,它将不再是Driver节点上的counter,而是闭包中的副本counter,默认情况下,副本counter更新后的值不会回传到Driver,所以counter的最终值仍然为零。
需要注意的是:在Local模式下,有可能执行foreach的Worker Node与Diver处在相同的JVM,并引用相同的原始counter,这时候更新可能是正确的,但是在集群模式下一定不正确。所以在遇到此类问题时应优先使用累加器。
累加器的原理实际上很简单:就是将每个副本变量的最终值传回Driver,由Driver聚合后得到最终值,并更新原始变量。
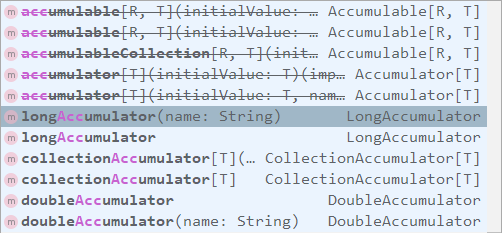
2.2 使用累加器
SparkContext中定义了所有创建累加器的方法,需要注意的是:被中横线划掉的累加器方法在Spark 2.0.0之后被标识为废弃。
使用示例和执行结果分别如下:
val data = Array(1, 2, 3, 4, 5)
// 定义累加器
val accum = sc.longAccumulator("My Accumulator")
sc.parallelize(data).foreach(x => accum.add(x))
// 获取累加器的值
accum.value

三、广播变量
在上面介绍中闭包的过程中我们说道每个Task任务的闭包都会持有自由变量的副本,如果变量很大且Task任务很多的情况下,这必然会对网络IO造成压力,为了解决这个情况,Spark提供了广播变量。
广播变量的做法很简单:就是不把副本变量分发到每个Task中,而是将其分发到每个Executor,Executor中的所有Task共享一个副本变量。
// 把一个数组定义为一个广播变量
val broadcastVar = sc.broadcast(Array(1, 2, 3, 4, 5))
// 之后用到该数组时应优先使用广播变量,而不是原值
sc.parallelize(broadcastVar.value).map(_ * 10).collect()
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Spark学习之路(六)—— 累加器与广播变量的更多相关文章
- Spark学习之编程进阶——累加器与广播(5)
Spark学习之编程进阶--累加器与广播(5) 1. Spark中两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable).累加器对信息进行聚合,而广播变 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
- Spark学习之路 (四)Spark的广播变量和累加器[转]
概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上,并 ...
- Spark 系列(六)—— 累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark--DataFrames,RDD,DataSets 一.弹性数据集(RDD) 创建RDD 1.1RDD的宽依赖和窄依赖 二.DataFrames 三.DataSets 四.什么时候使用Dat ...
- Spark学习之路 (九)SparkCore的调优之数据倾斜调优
摘抄自:https://tech.meituan.com/spark-tuning-pro.html 数据倾斜调优 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Sp ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark入门3(累加器和广播变量)
一.概要 通常情况下,当向Spark操作传递一个函数时,它会在一个远程集群节点上执行,它会使用函数中所有变量的副本.这些变量被复制到所有的机器上,远程机器上并没有被更新的变量会向驱动程序回传.在任务之 ...
随机推荐
- java学习笔记(6)——序列化
一.序列化与基本类型序列化 1,将类型int转换为4byte,或将其它数据类型(如long->8byte)的过程, 即将数据转换为n个byte序列叫序列化(数据->n byte) 如:0x ...
- DDD实战12 值对象不创建表,而是直接作为实体中的字段
这里的值对象如下风格: namespace Order.Domain.PocoModels { //订单地址 //虽然是值对象 但是不继承ValueObject //因为继承ValueObject会有 ...
- 监听WPF依赖属性
原文:监听WPF依赖属性 当我们使用依赖属性的时候,有时需要监听它的变化,这在写自定义控件的时候十分有用, 下面介绍一种简单的方法. 如下使用DependencyPropertyDescripto ...
- 【HLSL学习笔记】WPF Shader Effect Library算法解读之[BandedSwirl]
原文:[HLSL学习笔记]WPF Shader Effect Library算法解读之[BandedSwirl] 因工作原因,需要在Silverlight中使用Pixel Shader技术,这对于我来 ...
- modern-cpp-features
C++17/14/11 Overview Many of these descriptions and examples come from various resources (see Acknow ...
- Win7 64位系统,使用(IME)模式VS2010 编写 和 安装 输入法 教程(1)
原文:Win7 64位系统,使用(IME)模式VS2010 编写 和 安装 输入法 教程(1) 首先感谢:http://blog.csdn.net/shuilan0066/article/detail ...
- 3ds Max建模,Blend设计,VS2008控制WPF的3D模型例子
原文:3ds Max建模,Blend设计,VS2008控制WPF的3D模型例子 3ds Max建模,Blend设计,VS2008控制WPF的3D模型例子 所用的软件 3ds Max 9.0,Mic ...
- cefsharp 与webbrowser简单对比概述
原文:cefsharp 与webbrowser简单对比概述 有个项目需要做个简单浏览器,从网上了解到几个相关的组件有winform自带的IE内核的WebBrowser,有第三方组件谷歌内核的webki ...
- Jenkins build失败条件
在Jenkins 项目写了很多剧本.有时候,我发现脚本失败,但Jenkins运行成功. Jenkins无论是通过退出代码0比量build成功. 因此,newLISP在.您可以使用(exit)对于成功. ...
- WPF DataTemplateSelector的使用
<Window x:Class="CollectionBinding.MainWindow" xmlns="http://schemas.micros ...