Spark学习之路 (四)Spark的广播变量和累加器[转]
概述
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)
广播变量broadcast variable
为什么要将变量定义成广播变量?
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
广播变量图解
错误的,不使用广播变量
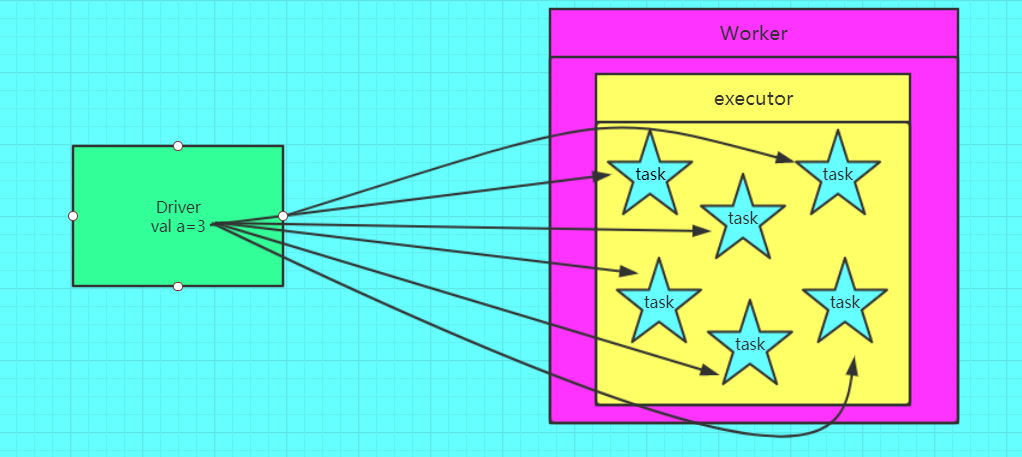
正确的,使用广播变量的情况

如何定义一个广播变量?
val a = 3
val broadcast = sc.broadcast(a)如何还原一个广播变量?
val c = broadcast.value定义广播变量需要的注意点?
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
注意事项
- 能不能将一个RDD使用广播变量广播出去?不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
- 广播变量只能在Driver端定义,不能在Executor端定义。
- 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
- 如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
- 如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
累加器
为什么要将一个变量定义为一个累加器?
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
图解累加器
错误的图解

正确的图解

如何定义一个累加器?
val a = sc.accumulator(0)如何还原一个累加器?
val b = a.value注意事项
- 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
- 累加器不是一个调优的操作,因为如果不这样做,结果是错的
Spark学习之路 (四)Spark的广播变量和累加器[转]的更多相关文章
- Spark——DataFrames,RDD,DataSets、广播变量与累加器
Spark--DataFrames,RDD,DataSets 一.弹性数据集(RDD) 创建RDD 1.1RDD的宽依赖和窄依赖 二.DataFrames 三.DataSets 四.什么时候使用Dat ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark(三)RDD与广播变量、累加器
一.RDD的概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可 ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark RDD持久化、广播变量和累加器
Spark RDD持久化 RDD持久化工作原理 Spark非常重要的一个功能特性就是可以将RDD持久化在内存中.当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内 ...
- Spark 广播变量和累加器
Spark 的一个核心功能是创建两种特殊类型的变量:广播变量和累加器 广播变量(groadcast varible)为只读变量,它有运行SparkContext的驱动程序创建后发送给参与计算的节点.对 ...
- Spark(八)【广播变量和累加器】
目录 一. 广播变量 使用 二. 累加器 使用 使用场景 自定义累加器 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的 ...
- SparkCore | Rdd| 广播变量和累加器
Spark中三大数据结构:RDD: 广播变量: 分布式只读共享变量: 累加器:分布式只写共享变量: 线程和进程之间 1.RDD中的函数传递 自己定义一些RDD的操作,那么此时需要主要的是,初始化工作 ...
- 广播变量、累加器、collect
广播变量.累加器.collect spark集群由两类集群构成:一个驱动程序,多个执行程序. 1.广播变量 broadcast 广播变量为只读变量,它由运行sparkContext的驱动程序创建后发送 ...
- Spark学习之路 (四)Spark的广播变量和累加器
一.概述 在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本.这些变量会被复制到每台机器上 ...
随机推荐
- 【Detection】物体识别-制作PASCAL VOC数据集
PASCAL VOC数据集 PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge 默认为20类物体 1 数据集结构 ...
- python学习(2)关于字符编码
关于字符编码的学习内容笔记如下: 1.计算机只能用0和1来进行记录和存储.计算机是二进制. 2.ASCII(American Standard Code for Information Interch ...
- Spring——管理Bean的生命周期
我们可以自定义bean的初始化和销毁方法,这里所指的的初始化和bean的构造不同,初始化是在bean构造完成后,对bean内部的属性或一些逻辑进行初始化. 首先要弄清一些概念: 构造(对象创建) 单实 ...
- 14-SSM整合
今日知识 1. Spring整合MyBatis 2. SSM普通整合 3. SSM整合(Spring和SpringMVC分离) 4. 纯JavaConfig的SSM Spring整合MyBatis 1 ...
- golang-练习ATM --面向对象实现
package utils import ( "fmt" "strings" ) type StructAtm struct { action int loop ...
- python网络爬虫(三)requests库的13个控制访问参数及简单案例
酱酱~小编又来啦~
- 学习分享--python网络爬虫(一)关于如何更新python pip以及如何安装python requests库
一.python pip的更新(我的是window10 界面可能不太一样) 1.找到电脑左下角开始按钮,并点击: 2.输入cmd 3.打开以后,先查看自己的pip版本 输入:pip -V 敲回 ...
- 一种高灵敏度自带DSP降噪算法的音频采集解决方案
背景调研 随着AI渗透到各行各业,人们对语音的需求也越来越大,最近一两年,各种AI音频设备如雨后春笋般冒出.各种智能AI设备的推出,意味者市场对低成本的音频采集设备越来越多.针对这种情况,我们开发 ...
- Javascript 基础学习(六)js 的对象
定义 对象是JS中的引用数据类型.对象是一种复合数据类型,在对象中可以保存多个不同数据类型的属性.使用typeof检查一个对象时,会返回object. 分类 内置对象 由ES标准定义的对象,在任何ES ...
- sql对于表格中列的删改
mysql与oracle char为定长字符串 var为可变字符串 修改表名:rename table1 to table2:(mysql) alter table1 rename to table2 ...