python 爬虫时遇到问题及解决
源代码:
#unicoding=utf-8
import re
import urllib
def gethtml(url):
html=urllib.urlopen(url)
page=html.read()
return page
def img(page):
reg=r'src="(.+?\jpg)" alt'
imgre=re.compile(reg)
imglist=re.findall(imgre,page)
x=0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
#page=gethtml("http://www.51tietu.net/tp/")
page=gethtml("http://mm.51tietu.net/qingchun/90/")
img(page)
这样执行的话,会出现IOError 大致意思时文件操作时,出现错误
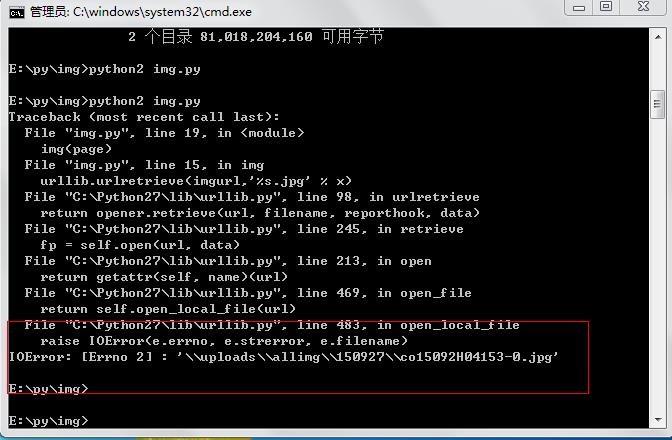
在这里可以看到IOError后跟着你抓取到的jip文件的路径,但是这个路径不是整个url的路径,所以才会在urlretrieve调用imgurl的时候报错。
去网站查看整个URL

因此可以根据图中的url进行修改代码, 想法:可以在urlretrieve中把url补完整,之后代码如下
#unicoding=utf-8
import re
import urllib
def gethtml(url):
html=urllib.urlopen(url)
page=html.read()
return page
def img(page):
reg=r'src="(.+?\jpg)" alt'
imgre=re.compile(reg)
imglist=re.findall(imgre,page)
x=0
for imgurl in imglist:
urllib.urlretrieve('http://mm.51tietu.net'+imgurl,'%s.jpg' % x)
x+=1
#page=gethtml("http://www.51tietu.net/tp/")
page=gethtml("http://mm.51tietu.net/qingchun/90/")
img(page)
之后再进行运行的话,就可以将图片爬取到本地了。
效果如下:

python 爬虫时遇到问题及解决的更多相关文章
- Python爬虫老是被封的解决方法【面试必问】
在爬取的过程中难免发生 ip 被封和 403 错误等等,这都是网站检测出你是爬虫而进行反爬措施,在这里为大家总结一下 Python 爬虫动态 ip 代理防止被封的方法. PS:另外很多人在学习Pyth ...
- python爬虫时,解决编码方式问题的万能钥匙(uicode,utf8,gbk......)
转载 原文:https://blog.csdn.net/xiongzaiabc/article/details/81008330 无论遇到的网页代码是何种编码方式,都可以用以下方法统一解决 imp ...
- Python 爬虫常见的坑和解决方法
1.请求时出现HTTP Error 403: Forbidden headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23. ...
- python爬虫框架scrapy问题的解决
2016-09-24:今天的弄了一天的scrapy的环境的配置的,linux很多的学过的事情都忘记啦.理论和实践的结合还是非常的重要的,不光要学会思考,更要学会总结纪录.还要多多回忆的和复习.学习了不 ...
- Python爬虫技术:爬虫时如何知道是否代理ip伪装成功?
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. python爬虫时如何知道是否代理ip伪装成功: 有时候我们的爬虫程序添加了 ...
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- 从python爬虫引发出的gzip,deflate,sdch,br压缩算法分析
今天在使用python爬虫时遇到一个奇怪的问题,使用的是自带的urllib库,在解析网页时获取到的为b'\x1f\x8b\x08\x00\x00\x00\x00...等十六进制数字,尝试使用chard ...
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- python爬虫中文乱码解决方法
python爬虫中文乱码 前几天用python来爬取全国行政区划编码的时候,遇到了中文乱码的问题,折腾了一会儿,才解决.现特记录一下,方便以后查看. 我是用python的requests和bs4库来实 ...
随机推荐
- CodeForces 222D - Olympiad
第一行给出两个个数字k和n,第二三行分别有k个数字,求将第二.三行之间的数字相互组合,求最多有多少个组合的和不小于n 纯粹暴力 #include <iostream> #include & ...
- Unique Binary Search Trees,Unique Binary Search Trees II
Unique Binary Search Trees Total Accepted: 69271 Total Submissions: 191174 Difficulty: Medium Given ...
- 个人的IDE制作(vim)——适用于C++/C
引用文章A:http://learnvimscriptthehardway.onefloweroneworld.com/ 引用介绍:初学者建议通读一遍.对VIM能有整体性的了解. 引用文章B:http ...
- Arcgis Engine 添加一个Symbol符号样式步骤
public static void DrawPictureMarkerSymbol(IGlobe globe, String layerName) { //添加一个图层 ESRI.ArcGIS.Ca ...
- Ubuntu14.04安装配置SVN及Trac
还是个实习生的时候,项目管理十分欠缺,会出现很多问题,痛定思痛,决定要改变现状,养成良好的项目管理习惯,看网上工具很多,在这里尝试使用SVN作代码版本控制,使用trac作为项目管理追踪.本文采用的操作 ...
- c++中在一个类中定义另一个只有带参数构造函数的类的对象
c++中在一个类中定义另一个只有带参数构造函数的类的对象,编译通不过 #include<iostream> using namespace std; class A { public: ...
- 测试框架mochajs详解
测试框架mochajs详解 章节目录 关于单元测试的想法 mocha单元测试框架简介 安装mocha 一个简单的例子 mocha支持的断言模块 同步代码测试 异步代码测试 promise代码测试 不建 ...
- Inno Setup 安装inf文件的一个例子
原文 http://zwkufo.blog.163.com/blog/static/2588251201063033524889/ ; INF安装例子; [Setup]; 注意: AppId 的值是唯 ...
- cf455A Boredom
A. Boredom time limit per test 1 second memory limit per test 256 megabytes input standard input out ...
- linux之grep实例讲解
文件testgrep内容: 1.显示所有包含San的行 2.显示所有以J开始的人名所在的行 3.显示所有以700结尾的行 4.显示所有不包括834的行 5.显示所有生日在December的行 ...