Oracle Spatial分区应用研究之一:分区与分表查询性能对比
1、名词解释
分区:将一张大表在物理上分成多个分区,逻辑上仍然是同一个表名。
分表:将一张大表拆分成多张小表,不同表有不同的表名。
两种数据组织形式的原理图如下:

图 1分表与分区的原理图
2、实验目的
本实验的目的,在于对比分区与分表技术,分析其在"大图层"(大图层指要素数量超过200万条的图层)上的适用性。
3、实验数据
实验数据为贵州省87县地类图斑数据,要素总数为6695554。根据不同的数据组织+索引形式,形成了3个不同的实验主体:
- 分表存储+空间索引
- 按县分区+全局空间索引
- 按县分区+本地空间索引
4、实验过程
4.1 实验方法
在1:500、1:2000、1:10000、1:25000、1:50000、1:100000比例尺下,随机从贵州省省域内选择3个样本范围,作为空间查询时的查询范围。将6*3个样本范围分别与3个实验主体进行空间查询运算,记录每次查询的耗时。
为了使查询实验覆盖所有的使用场景,将在基于磁盘、基于内存的两种查询场景中重复上述实验。
4.2 实验算法
实验算法用来描述实现上述空间查询的计算方法。
4.2.1 分表算法
多表的算法有两种,分别命名为part_query、nopart_query,其伪代码如下:
4.2.1.1 nopart_query
根据xzq_xj (县级行政区底图),判断BR(Boundary Rectangle,范围矩形)与哪些县级行政区相交
loop
根据xzqdm查询县级图层名layername;
根据layername,判断BR与哪些要素相交,并返回结果;
end loop;
4.2.1.2 nopart_query2
根据xzq_xj (县级行政区底图),判断BR与哪些县级行政区相交
loop
根据xzqdm查询县级图层名layername;
得到与layername进行空间查询的SQL语句;
用UNION ALL进行SQL语句拼接;
end loop;
执行拼接后的SQL语句;
4.2.2 分区算法
分区的算法有3种,分别命名为part_query、part_query2、part_query3,其伪代码如下:
4.2.2.1 Part_query
根据xzq_xj (县级行政区底图),判断BR与哪些县级行政区相交
得到相交行政区列表 xzq_lists
将xzq_lists作为查询条件之一,SQL语句样式如下:
"select shape from part_table t where xzqdm in (xzq_lists) sdo_filter(t.shape,BR))";
4.2.2.2 Part_query2
将得到行政区列表 xzq_lists的过程内嵌到SQL语句里,其样式如下:
"select shape from part_table t where xzqdm in (select xzqdm from xzq_xj t where sdo_filter(t.shape,BR)) sdo_filter(t.shape,BR))";
4.2.2.3 Part_query3
仅使用BR作为查询条件,SQL语句样式如下:
select shape from part_table t where sdo_filter(t.shape,BR));
5、实验结果
5.1 基于磁盘的查询
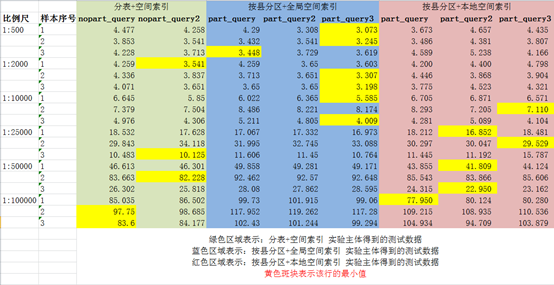
根据黄色斑块坐落的位置,可知:
- 在比例尺大于1:10000(包括)时,分区表+全局空间索引效率最高(命中7次),且part_query3算法最优(命中6次);
- 在比例尺小于1:10000时,分区表+本地空间索引效率最高(命中5次),且part_query2算法最优(命中3次)
5.2 基于内存的查询
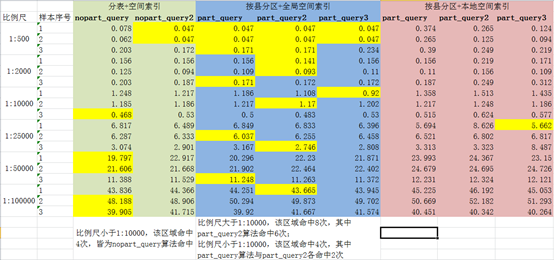
- 在比例尺大于1:10000(包括)时,分区表+全局空间索引效率最高(命中8次),且part_query2算法最优(命中6次);
- 在比例尺小于1:10000时,分表+空间索引与分区表+全局空间索引效率一致(命中4次),这其中分表+空间索引所使用的nopart_query算法最优(命中4次)。
6、实验结论
- 观察5实验结果中的两张图,横向比较,可知在该实验数据和实验条件下,不同数据组织方式和不同算法之间,其差异均不大。考虑到实验所在网络与服务器环境均非独占使用,单个查询性能可能会产生抖动性,因此上述分项结论仅作为参考,尚不能作为正式结论;
- 该实验所用的实验数据为87县市的地类图斑数据,而全国有近3000个县市,因此样本数据较之整体数据,仍显偏小。这从另一方面说明上述分项结论仅作为参考,尚不能作为正式结论;
- 上述实验所采集的时间数据,是在特定服务器与存储环境下得到的。在不同的设备情况下,其值会有不同。
- 若仅以此次实验结果为准,可得出如下结论:土地调查业务,大多数的应用场景,是在大比例尺,即1:10000-1:200比例尺下的查询浏览。因此在规划数据组织方式时,应更多考虑大多数应用场景的查询效率。基于此种考虑,建议数据物理组织采用:按县分区+全局空间索引。
(未完待续)
Oracle Spatial分区应用研究之一:分区与分表查询性能对比的更多相关文章
- Mysql分表和分区的区别、分库分表介绍与区别
分表和分区的区别: 一,什么是mysql分表,分区 什么是分表,从表面意思上看呢,就是把一张表分成N多个小表,具体请看:mysql分表的3种方法 什么是分区,分区呢就是把一张表的数据分成N多个区块,这 ...
- (转) MySQL分区与传统的分库分表
传统的分库分表 原文:http://blog.csdn.net/kobejayandy/article/details/54799579 传统的分库分表都是通过应用层逻辑实现的,对于数据库层面来说,都 ...
- Mysql分表和分区的区别、分库分表介绍与区别(转)
分表和分区的区别: 一,什么是mysql分表,分区 什么是分表,从表面意思上看呢,就是把一张表分成N多个小表,具体请看:mysql分表的3种方法 什么是分区,分区呢就是把一张表的数据分成N多个区块,这 ...
- 利用SpEL 表达式实现简单的动态分表查询
这里的动态分表查询并不是动态构造sql语句,而是利用SpEL操作同一结构的不同张表. 也可以参考Spring Data Jpa中的章节http://docs.spring.io/spring-data ...
- mysql如何查询多样同样的表/sql分表查询、java项目日志表分表的开发思路/按月分表
之前开发的一个监控系统,数据库的日志表是单表,虽然现在数据还不大并且做了查询sql优化,不过以后数据库的日志表数据肯定会越来越庞大,将会导致查询缓慢,所以把日志表改成分表,日志表可以按时间做水平分表, ...
- MySql分区后创建索引加速单表查询和连表查询
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/konkon2012/article/de ...
- 【MySQL】数据库(分库分表)中间件对比
分区:对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表 ...
- Mysql的Merge存储引擎实现分表查询
对于数据量很大的一张表,i/o效率底下,分表势在必行! 使用程序分,对不同的查询,分配到不同的子表中,是个解决方案,但要改代码,对查询不透明. 好在mysql 有两个解决方案: Partition(分 ...
- oracle数据迁移之Exp和Expdp导出数据的性能对比与优化
https://wangbinbin0326.github.io/2017/03/31/oracle%E6%95%B0%E6%8D%AE%E8%BF%81%E7%A7%BB%E4%B9%8BExp%E ...
随机推荐
- Thinkphp内核百度小程序输出接口
最近百度小程序比较火,自己站点用thinkphp打造的,所以写了这个Thinkphp的百度小程序输出接口,实现数据同步. 附上代码 <?php namespace app\article\con ...
- dimensionality reduction动机---visualization(将数据可视化帮助我们更好地理解数据)
如果我们能更好地理解我们的数据,这样会对我们开发高效的机器学习算法有作用,将数据可视化(将数据画出来能更好地理解数据)出来将会对我们理解我们的数据起到很大的帮助. 高维数据如何进行显示 GDP: gr ...
- jQuery通用遍历方法each的实现
each介绍 jQuery 的 each 方法,作为一个通用遍历方法,可用于遍历对象和数组. 语法为: jQuery.each(object, [callback]) 回调函数拥有两个参数:第一个为对 ...
- python面试题&练习题之运算符与if控制
1.任意的输入10个数字,按从大到小排序 l2 = [] for i in range(1,11): num = input('输入第{}个数字'.format(i)) if num.isdigit( ...
- OI歌曲汇总
在学习的间隙,我们广大的OIer创作了许多广为人知的歌曲 这里来个总结 (持续更新ing......) Lemon OI 葛平 Lemon OI chen_zhe Lemon OI kkksc03 膜 ...
- P3746 【[六省联考2017]组合数问题】
题目是要我们求出如下柿子: \[\sum_{i=0}^{n}C_{nk}^{ik+r}\] 考虑k和r非常小,我们能不能从这里切入呢? 如果你注意到,所有组合数上方的数\(\%k==r\),那么是不是 ...
- gulp/webpack运行sass报错解决方法
帮同事安装gulp和webpack运行环境,使用cnpm install安装node-sass之后,运行项目总是报错,提示vendor目录不存在,几番百度之后,找到处理方法,这里记录一笔,防止以后遇到 ...
- mysql adddate()函数
mysql> ); +---------------------------+ | adddate() | +---------------------------+ | -- | +----- ...
- MATLAB关闭科学计数法显示
- clion下批量删除断点