HBase安装指南
一.事前准备
- 此安装是建立在hadoop集群运行起来的基础上,此hadoop版本为2.6.0,其他版本未测试,可能存在兼容性问题。
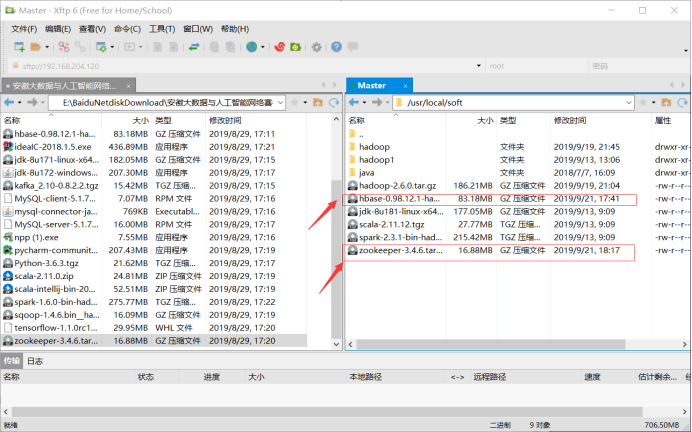
- 上传所需文件到/usr/local/soft
二.zookeeper安装
1.进入文件所在目录:cd /usr/local/soft/

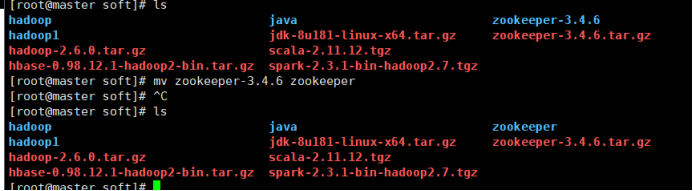
2. 解压:tar -zxvf zookeeper-3.4.6.tar.gz
3. 重命名:mv zookeeper-3.4.6 zookeeper
4. 进入conf目录:cd zookeeper/conf/
5. 复制并重命名zoo_sample.cfg为zoo.cfg:cp zoo_sample.cfg zoo.cfg

6.返回上一级,并新建一个data文件夹:mkdir data

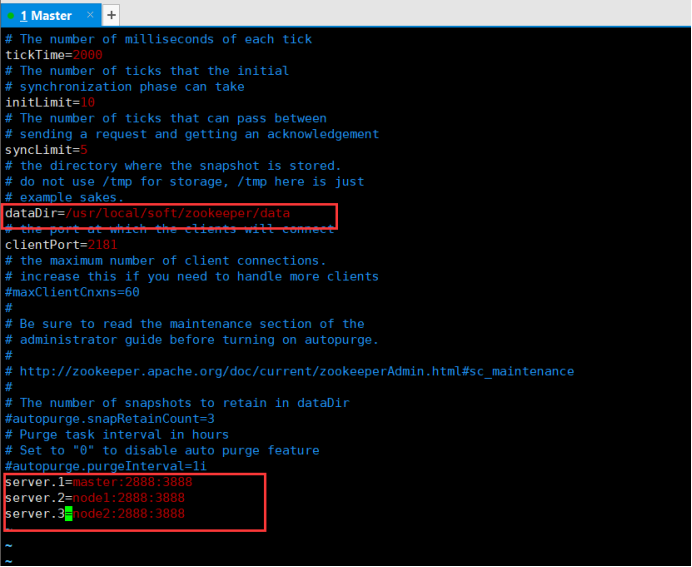
7.进入zoo.cfg文件并修改配置如下:vim conf/zoo.cfg
8. 返回软件安装目录soft,并将该配置目录同步到node1,node2
scp -r zookeeper root@node1:/usr/local/soft/
scp -r zookeeper root@node2:/usr/local/soft/

9.分别修改个三台主机的对应id:vim zookeeper/data/myid



10.启动zookeeper(三台都执行):bin/zkServer.sh start

11. 验证zookeeper(三台都执行):bin/zkServer.sh status
注意:node1为leader,master,node2为follower
以上zookeeper安装完成
三.Hbase安装
1.回到soft目录下,解压hbase:tar -zxvf hbase-0.98.12.1-hadoop2-bin.tar.gz
2.重命名hbase :mv hbase-0.98.12.1-hadoop2 hbase
3.配置profile文件并发送给其他节点:
vim /etc/profile.d/hbase.sh

# SET HBASE
export HBASE_HOME=/usr/local/soft/hbase
export PATH=$HBASE_HOME/bin:$PATH
发送节点:
scp -r /etc/profile.d/hbase.sh root@node1:/etc/profile.d/
scp -r /etc/profile.d/hbase.sh root@node2:/etc/profile.d/

4.使配置生效(三台都执行):source /etc/profile

5.修改hbase-env.sh配置文件: vim hbase/conf/hbase-env.sh


export JAVA_HOME=/usr/local/soft/java
export HBASE_MANAGES_ZK=false
6.修改hbase-site.xml配置文件:vim hbase/conf/hbase-site.xml

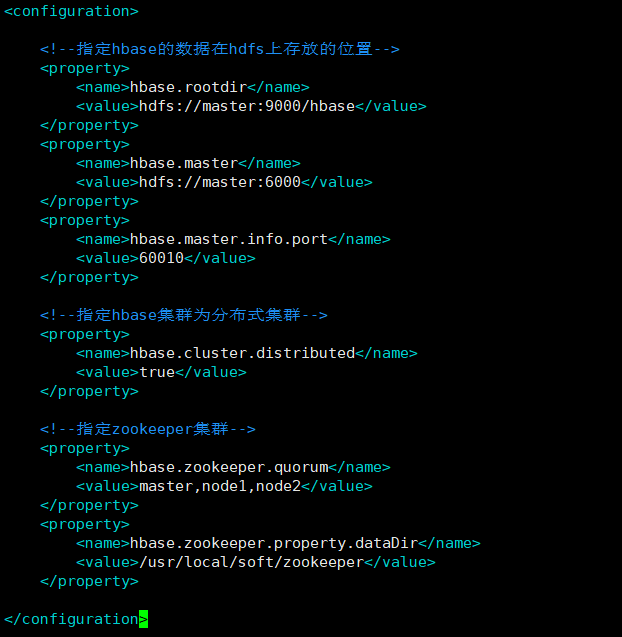
<!--指定hbase的数据在hdfs上存放的位置-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:6000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!--指定hbase集群为分布式集群-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--指定zookeeper集群-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,node1,node2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/soft/zookeeper</value>
</property>
7. 设置备用:vim hbase/conf/backup-masters

8. 修改regionservers 配置文件:vim hbase/conf/regionservers

9.复制hadoop配置文件到hbase目录下:
cp hadoop/etc/hadoop/core-site.xml hbase/conf/
cp hadoop/etc/hadoop/hdfs-site.xml hbase/conf/

10.将hbase安装目录发送到其他节点:
scp -r hbase root@node1:/usr/local/soft/
scp -r hbase root@node2:/usr/local/soft/

11.启动hbase:start-hbase.sh

12.各节点jps截图:

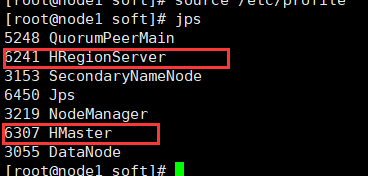

13. 验证hbase
网页验证:

简单命令验证

HBase安装指南的更多相关文章
- 菜鸟玩云计算之十一:Hadoop 手动安装指南
Hadoop 手动安装指南 cheungmine 2013-4 本文用于指导在Windows7,VMWare上安装Ubuntu, Java, Hadoop, HBase实验环境. 本指南用于实验的软件 ...
- Hadoop+HBase+Spark+Hive环境搭建
杨赟快跑 简书作者 2018-09-24 10:24 打开App 摘要:大数据门槛较高,仅仅环境的搭建可能就要耗费我们大量的精力,本文总结了作者是如何搭建大数据环境的(单机版和集群版),希望能帮助学弟 ...
- Hive 1.2.1&Spark&Sqoop安装指南
目录 目录 1 1. 前言 1 2. 约定 2 3. 服务端口 2 4. 安装MySQL 2 4.1. 安装MySQL 2 4.2. 创建Hive元数据库 4 5. 安装步骤 5 5.1. 下载Hiv ...
- HBase-1.2.1和Phoenix-4.7.0分布式安装指南
目录 目录 1 1. 前言 2 2. 概念 2 2.1. Region name 2 3. 约定 2 4. 相关端口 3 5. 下载HBase 3 6. 安装步骤 3 6.1. 修改conf/regi ...
- HBase-0.98.0和Phoenix-4.0.0分布式安装指南
目录 目录 1 1. 前言 1 2. 约定 2 3. 相关端口 2 4. 下载HBase 2 5. 安装步骤 2 5.1. 修改conf/regionservers 2 5.2. 修改conf/hba ...
- ZooKeeper-3.4.10分布式安装指南
目录 目录 1 1. 前言 1 2. 约定 1 3. 安装步骤 2 3.1. 配置/etc/hosts 2 3.2. 设置myid 2 3.3. 修改conf/zoo.cfg 2 3.4. 修改/bi ...
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- Redis/HBase/Tair比较
KV系统对比表 对比维度 Redis Redis Cluster Medis Hbase Tair 访问模式 支持Value大小 理论上不超过1GB(建议不超过1MB) 理论上可配置(默认配置1 ...
- Hbase的伪分布式安装
Hbase安装模式介绍 单机模式 1> Hbase不使用HDFS,仅使用本地文件系统 2> ZooKeeper与Hbase运行在同一个JVM中 分布式模式– 伪分布式模式1> 所有进 ...
随机推荐
- Netty4的介绍(一)
Netty是由JBOSS提供给的一个java开源框架.Netty提供异步的.事件驱动的网络应用框架和工具,用以快速开发高性能.高可靠的网络服务器和客户端程序. 也就是说,Netty是一个基于NIO的客 ...
- CSS中的父相子绝布局
主要应用场景,就是我想要块的布局根据父级来定位,而不是根据页面. 例如,下面的例子中,我用两个半圆拼成一个正圆,思路是用一个父级标签把两个子标签包起来,父标签是一个正圆,然后子标签各占一半,先化成两个 ...
- 生产器&迭代器
生成器 列表生成器:简洁代码 >>> a = [i+1 for i in range(10)] >>> a [1, 2, 3, 4, 5, 6, 7, 8, 9, ...
- CSS换行知识
换行规则 CSS可以指定文字多行时换行的规则,说白了就是指定哪些地方可以换行 相关属性 word-break The word-break CSS property sets whether line ...
- Java开发:字符串切割split函数——切割符转码注意事项
一.问题如下: 1.先对一个已有字符串进行操作,使用 ; 进行分割: //示例字符串 String string="sr1.db1.tb1.df1;sr2.db2.tb2.d ...
- 结合Spring实现策略模式
最近系统需要对不同维度的数据进行差异化计算,也就会使用不同算法.为了以后更加容易扩展,结合Spring框架及策略模式对实现架构做了系统设计. 1. 定义策略接口(Strategy): import c ...
- GC分析工具使用-gceacy分析堆栈
gceasy是一款在线的gc分析工具.试用一下分析jstack的日志 1.jstack -l 3539 > 3539.stack 2.打包成zip文件 3.上传https://gceasy.io ...
- Windows / Office - KMS激活
Windows / Office - KMS激活 支持Windows操作系统,支持Office软件:包括Windows 10,Office 2016:包括VL版本和MSDN版. (UPDATE: Of ...
- linux录制终端信息并回放
我们通常会录制桌面环境视频来作为教程使用,但是视频需要大量的存储空间,而终端脚本文件仅仅是一个文本文件,其文件大小不过是KB级别 1, 开始录制终端会话 [root@VM_0_15_centos ~] ...
- centos7上配置mysql8的双主互写
注意:1.主库1:10.1.131.75,主库2:10.1.131.762.server-id必须是纯数字,并且主从两个server-id在局域网内要唯一. [主节点1]vi /etc/my.cnf[ ...