hiveserver2和zookeeper的HA搭建(转)
最近公司新项目申请资源,虚拟机资源打开时候使用source login.sh的脚本来进行登录注册,好奇心驱使下看了看里面的shell脚本,使用到了hiveserver2的zookeeper连接,百度一下找了篇博客学习一下;
转自:https://blog.csdn.net/qq_30950329/article/details/78024282
在生产环境中使用Hive,强烈建议使用HiveServer2来提供服务,好处很多:
1. 在应用端不用部署Hadoop和Hive客户端;
2. 相比hive-cli方式,HiveServer2不用直接将HDFS和Metastore暴漏给用户;
3. 有安全认证机制,并且支持自定义权限校验;
4. 有HA机制,解决应用端的并发和负载均衡问题;
5. JDBC方式,可以使用任何语言,方便与应用进行数据交互;
6. 从2.0开始,HiveServer2提供了WEB UI。
如果使用HiveServer2的Client并发比较少,可以使用一个HiveServer2实例,没问题。

但如果这一个实例挂掉,那么会导致所有的应用连接失败。
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port。本文学习和研究HiveServer2的高可用配置。使用的Hive版本为apache-hive-2.0.0-bin。
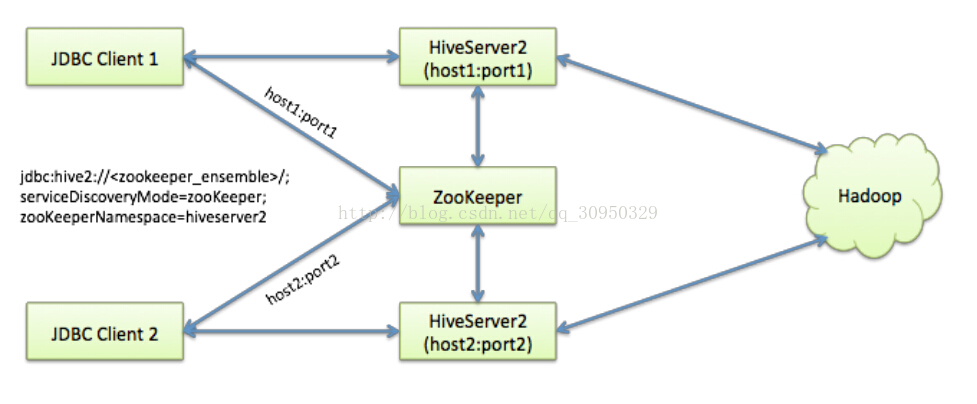
如上图,我准备在node1和node2上分别启用两个HiveServer2的实例,并通过zookeeper完成HA的配置。
Hive配置
注:这里假设你的Zookeeper已经安装好,并可用。
在两个安装了apache-hive-2.0.0-bin的机器上,分别编辑hive-site.xml,添加以下参数:
- <property>
- <name>hive.server2.support.dynamic.service.discovery</name>
- <value>true</value>
- </property>
- <property>
- <name>hive.server2.zookeeper.namespace</name>
- <value>hiveserver2_zk</value>
- </property>
- <property>
- <name>hive.zookeeper.quorum</name>
- <value> zkNode1:2181,zkNode2:2181,zkNode3:2181</value>
- </property>
- <property>
- <name>hive.zookeeper.client.port</name>
- <value>2181</value>
- </property>
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>0.0.0.0</value>
- </property>
- <property>
- <name>hive.server2.thrift.port</name>
- <value>10001</value> //两个HiveServer2实例的端口号要一致
- </property>
先启动第一个HiveServer2 :
cd $HIVE_HOME/bin
./hiveserver2

再启动另一个:

第二个实例启动后,ZK中可以看到两个都注册上来。
JDBC连接
JDBC连接的URL格式为:
jdbc:hive2://<zookeeper quorum>/<dbName>;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
其中:
<zookeeper quorum> 为Zookeeper的集群链接串,如zkNode1:2181,zkNode2:2181,zkNode3:2181
<dbName> 为Hive数据库,默认为default
serviceDiscoveryMode=zooKeeper 指定模式为zooKeeper
zooKeeperNamespace=hiveserver2 指定ZK中的nameSpace,即参数hive.server2.zookeeper.namespace所定义,我定义为hiveserver2_zk
使用beeline测试连接:
- cd $HIVE_HOME/bin
- ./beeline
- !connect jdbc:hive2://zkNode1:2181,zkNode2:2181,zkNode3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk liuxiaowen ""
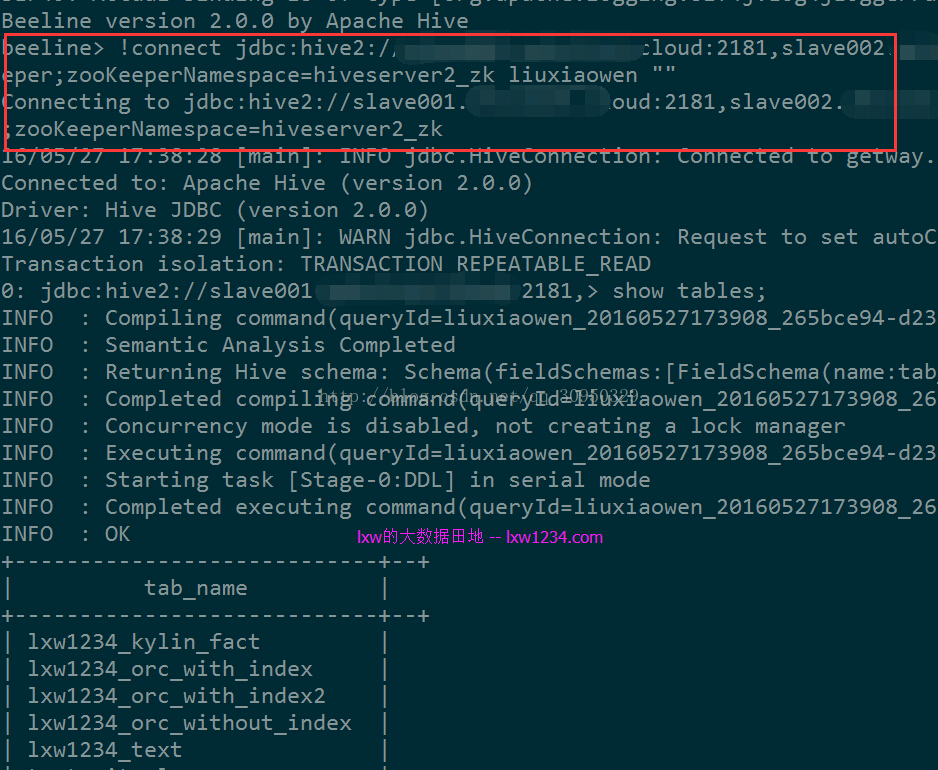
可以正常连接。
执行一个HQL查询,日志中显示连接到的HiveServer2实例为Node2,停掉Node2中的HiveServer2实例后,需要重新使用!connect命令连接,之后可以继续正常执行查询,日志显示连接到了Node1中的实例。
关于Hadoop2中的用户权限认证
本例中两个HiveServer2实例均使用普通用户liuxiaowen启动,
刚开始使用beeline链接时候报错:
1. Error: Failed to open new session:
2. java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):
3. User: liuxiaowen is not allowed to impersonate liuxiaowen (state=,code=0)
这是由于Hadoop2中的用户权限认证导致的。
参考资料:
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/Superusers.html
http://dongxicheng.org/mapreduce-nextgen/hadoop-secure-impersonation/
解决办法:
在Hadoop的core-site.xml中增加配置:
- <property>
- <name>hadoop.proxyuser.liuxiaowen.groups</name>
- <value>*</value>
- </property>
- <property>
- <name>hadoop.proxyuser.liuxiaowen.hosts</name>
- <value>*</value>
- </property>
其中 liuxiaowen 为启动HiveServer2的用户。
使用超级用户hadoop刷新配置:
yarn rmadmin -refreshSuperUserGroupsConfiguration
hdfs dfsadmin -refreshSuperUserGroupsConfiguration
如果是对namenode做过HA,则需要在主备namenode上执行:
hdfs dfsadmin -fs hdfs://cdh5 -refreshSuperUserGroupsConfiguration
之后问题解决,后续再详细研究这块。
至此,HiveServer2的多实例高可用-Ha配置完成,的确能解决生产中的很多问题,比如:并发、负载均衡、单点故障、安全等等。
因此强烈建议在生产环境中使用该模式来提供Hive服务。
hiveserver2和zookeeper的HA搭建(转)的更多相关文章
- Spark集群基于Zookeeper的HA搭建部署笔记(转)
原文链接:Spark集群基于Zookeeper的HA搭建部署笔记 1.环境介绍 (1)操作系统RHEL6.2-64 (2)两个节点:spark1(192.168.232.147),spark2(192 ...
- ActiveMQ笔记(2):基于ZooKeeper的HA方案
activemq官网给出了3种master/slave的HA方案,详见:http://activemq.apache.org/masterslave.html,基于共享文件目录,db,zookeepe ...
- ZooKeeper一二事 - 搭建ZooKeeper伪分布式及正式集群 提供集群服务
集群真是好好玩,最近一段时间天天搞集群,redis缓存服务集群啦,solr搜索服务集群啦,,,巴拉巴拉 今天说说zookeeper,之前搭建了一个redis集群,用了6台机子,有些朋友电脑跑步起来,有 ...
- HBase HA + Hadoop HA 搭建
HBase 使用的是 1.2.9 的版本. Hadoop HA 的搭建见我的另外一篇:Hadoop 2.7.3 HA 搭建及遇到的一些问题 以下目录均为 HBase 解压后的目录. 1. 修改 co ...
- hadoop HA + HBase HA搭建:
hadoop HA搭建参考:https://www.cnblogs.com/NGames/p/11083640.html (本节:用不到YARN 所以可以不用考虑部署YARN部分) Hadoop 使用 ...
- Spark HA搭建
正文 下载Spark版本,这版本又要求必须和jdk与hadoop版本对应. http://spark.apache.org/downloads.html tar -zxvf 解压到指定目录,进入con ...
- 分布式架构中一致性解决方案——Zookeeper集群搭建
当我们的项目在不知不觉中做大了之后,各种问题就出来了,真jb头疼,比如性能,业务系统的并行计算的一致性协调问题,比如分布式架构的事务问题, 我们需要多台机器共同commit事务,经典的案例当然是银行转 ...
- kafka学习(二)-zookeeper集群搭建
zookeeper概念 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名 服务等.Zookeeper是h ...
- [ZooKeeper] 2 环境搭建
上一篇中我们介绍了 ZooKeeper 的一些基本概念,这篇我们讲一下 ZooKeeper 的环境搭建. ZooKeeper 安装模式 单机模式:ZooKeeper 运行在一台服务器上,适合测试环境: ...
随机推荐
- winform 通用自动更新程序
通用自动更新程序 主要功能: 1. 可用于 C/S 程序的更新,集成到宿主主程序非常简单和配置非常简单,或不集成到主程序独立运行. 2. 支持 HTTP.FTP.WebService等多种更新下载方式 ...
- 记一次node节点异常排查
一.背景 公司进行kubernetes服务重启演练,集群重启后所有服务正常,仅node2节点处于notready状态 二.排查过程 查看对应节点的详细信息,发现kubelet一直处于starting状 ...
- selenium爬虫入门(selenium+Java+chrome)
selenium是一个开源的测试化框架,可以直接在浏览器中运行,就像用户直接操作浏览器一样,十分方便.它支持主流的浏览器:chrome,Firefox,IE等,同时它可以使用Java,python,J ...
- HDFS命令行及JAVA API操作
查看进程 jps 访问hdfs: hadoop-root:50070 hdfs bash命令: hdfs dfs <1> -help: 显示命令的帮助的信息 <2> - ...
- css3自定义上传图片输入框的方法
css3自定义上传图片输入框的方法 代码如下<pre> <form class="form1"> <img src="/kelatoupia ...
- 移相器——K波段有源移相器设计
博主之前在做一款K波段有源移相器,所用工艺为smic55nmll工艺,完成了几个主要模块的仿真,现对之前的工作做个总结. K波段的频率范围是18G——27GHz,所设计移相器的工作频率范围是19G—— ...
- docker 的Portainer和Dive
Portainer Portainer是Docker的图形化管理工具,提供状态显示面板.应用模板快速部署.容器镜像网络数据卷的基本操作(包括上传下载镜像,创建容器等操作).事件日志显示.容器控制台操作 ...
- 打印出三位数的水仙花数Python
水仙花数计算 ...
- 8、VUE自定义组件
1.为什么要使用自定义组件? 自定义组件是用来封装复杂的内容,提高可重用性,比如封装复杂的表格组件.日历组件.图片轮播组件等. 2.自定义组件 2.1. 全局组件 全局组件是每个Vue对象都能使用的组 ...
- SQL Server 连接字符串总结
这里记录的是c# 在vs中连接sql server数据库中的连接字符串的总结. 1.标准安全连接 Data Source = myServerAddress;Initial Catalog = myD ...