机器学习聚类算法之DBSCAN
一、概念
DBSCAN是一种基于密度的聚类算法,DBSCAN需要两个参数,一个是以P为中心的邻域半径;另一个是以P为中心的邻域内的最低门限点的数量,即密度。
优点:
1、不需要提前设定分类簇数量,分类结果更合理;
2、可以有效的过滤干扰。
缺点:
1、对高维数据处理效果较差;
2、算法复杂度较高,资源消耗大于K-means。
二、计算
1、默认使用第一个点作为初始中心;
2、通过计算点到中心的欧氏距离和领域半径对比,小于则是邻域点;
3、计算完所有点,统计邻域内点数量,小于于最低门限点数量则为噪声;
4、循环统计各个点的邻域点数,只要一直大于最低门限点数量,则一直向外扩展,直到不再大于。
5、一个簇扩展完成,会从剩下的点中重复上述操作,直到所有点都被遍历。
三、实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt cs = ['black', 'blue', 'brown', 'red', 'yellow', 'green'] class NpCluster(object):
def __init__(self):
self.key = []
self.value = [] def append(self, data):
if str(data) in self.key:
return
self.key.append(str(data))
self.value.append(data) def exist(self, data):
if str(data) in self.key:
return True
return False def __len__(self):
return len(self.value) def __iter__(self):
self.times = 0
return self def __next__(self):
try:
ret = self.value[self.times]
self.times += 1
return ret
except IndexError:
raise StopIteration() def create_sample():
np.random.seed(10) # 随机数种子,保证随机数生成的顺序一样
n_dim = 2
num = 100
a = 3 + 5 * np.random.randn(num, n_dim)
b = 30 + 5 * np.random.randn(num, n_dim)
c = 60 + 10 * np.random.randn(1, n_dim)
data_mat = np.concatenate((np.concatenate((a, b)), c))
ay = np.zeros(num)
by = np.ones(num)
label = np.concatenate((ay, by))
return {'data_mat': list(data_mat), 'label': label} def region_query(dataset, center_point, eps):
result = NpCluster()
for point in dataset:
if np.sqrt(sum(np.power(point - center_point, 2))) <= eps:
result.append(point)
return result def dbscan(dataset, eps, min_pts):
noise = NpCluster()
visited = NpCluster()
clusters = []
for point in dataset:
cluster = NpCluster()
if not visited.exist(point):
visited.append(point)
neighbors = region_query(dataset, point, eps)
if len(neighbors) < min_pts:
noise.append(point)
else:
cluster.append(point)
expand_cluster(visited, dataset, neighbors, cluster, eps, min_pts)
clusters.append(cluster)
for data in clusters:
print(data.value)
plot_data(np.mat(data.value), cs[clusters.index(data)])
if noise.value:
plot_data(np.mat(noise.value), 'green')
plt.show() def plot_data(samples, color, plot_type='o'):
plt.plot(samples[:, 0], samples[:, 1], plot_type, markerfacecolor=color, markersize=14) def expand_cluster(visited, dataset, neighbors, cluster, eps, min_pts):
for point in neighbors:
if not visited.exist(point):
visited.append(point)
point_neighbors = region_query(dataset, point, eps)
if len(point_neighbors) >= min_pts:
for expand_point in point_neighbors:
if not neighbors.exist(expand_point):
neighbors.append(expand_point)
if not cluster.exist(point):
cluster.append(point) init_data = create_sample()
dbscan(init_data['data_mat'], 10, 3)
聚类结果:
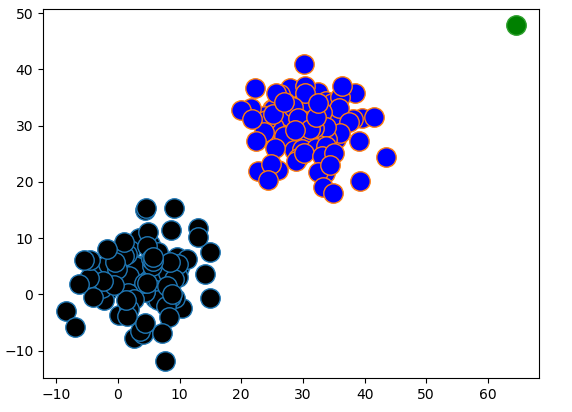
可以看到,点被很好的聚类为两个簇,右上角是噪声。
机器学习聚类算法之DBSCAN的更多相关文章
- 机器学习 - 算法 - 聚类算法 K-MEANS / DBSCAN算法
聚类算法 概述 无监督问题 手中无标签 聚类 将相似的东西分到一组 难点 如何 评估, 如何 调参 基本概念 要得到的簇的个数 - 需要指定 K 值 质心 - 均值, 即向量各维度取平均 距离的度量 ...
- 机器学习聚类算法之K-means
一.概念 K-means是一种典型的聚类算法,它是基于距离的,是一种无监督的机器学习算法. K-means需要提前设置聚类数量,我们称之为簇,还要为之设置初始质心. 缺点: 1.循环计算点到质心的距离 ...
- Standford机器学习 聚类算法(clustering)和非监督学习(unsupervised Learning)
聚类算法是一类非监督学习算法,在有监督学习中,学习的目标是要在两类样本中找出他们的分界,训练数据是给定标签的,要么属于正类要么属于负类.而非监督学习,它的目的是在一个没有标签的数据集中找出这个数据集的 ...
- 【Python机器学习实战】聚类算法(1)——K-Means聚类
实战部分主要针对某一具体算法对其原理进行较为详细的介绍,然后进行简单地实现(可能对算法性能考虑欠缺),这一部分主要介绍一些常见的一些聚类算法. K-means聚类算法 0.聚类算法算法简介 聚类算法算 ...
- 【转】常用聚类算法(一) DBSCAN算法
原文链接:http://www.cnblogs.com/chaosimple/p/3164775.html#undefined 1.DBSCAN简介 DBSCAN(Density-Based Spat ...
- 常用聚类算法(一) DBSCAN算法
1.DBSCAN简介 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度 ...
- 关于k-means聚类算法的matlab实现
在数据挖掘中聚类和分类的原理被广泛的应用. 聚类即无监督的学习. 分类即有监督的学习. 通俗一点的讲就是:聚类之前是未知样本的分类.而是根据样本本身的相似性进行划分为相似的类簇.而分类 是已知样本分类 ...
- 简单易学的机器学习算法—基于密度的聚类算法DBSCAN
简单易学的机器学习算法-基于密度的聚类算法DBSCAN 一.基于密度的聚类算法的概述 我想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别. ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
随机推荐
- kolla-ansible-----常用命令
常用命令 kolla-ansible prechecks -i multinode #部署前环境检测 kolla-genpwd #生成/etc/kolla/password.yml密码配置文件 kol ...
- Vimdiff 使用
what is vimdiff 在类nuix平台,我们希望对文件之间的差异之间快速定位,希望能够很容易的进行文件合并……. 可以使用Vim提供的diff模式,通常称作vimdiff,就是这样一个能满足 ...
- defineProperty
### Object.defineProperty() https://segmentfault.com/a/1190000007434923方法会直接在一个对象上定义一个新属性,或者修改一个已经存在 ...
- Emacs Python 自动补全之 jedi
jedi jedi 的安装配置并不是很友好.github 上也没有明确说明.查了很多资料, 最后才配置成功.可是效果却不是很理想.在补全的时候有明显的卡顿现象. 不知道网上这么多人对其推崇备至是因为什 ...
- iOS charts CombinedChartView First and last bars are shown half only
charts 使用CombinedChartView 绘图时,发现第一个和最后一个bar只能显示一半的问题,解决方法: ChartXAxis *xAxis = chartView.xAxis; xAx ...
- WPF Prism Request Navigate activation error
其他测试项目时没有问题,但是有些项目有时候导航一直报错误! Referring the StockTraderRI, I created a popup region in my shell infB ...
- 诺依/RuoYi开源系统搭建总结
问题一:从{码云}下载下来看,输入项目编码不过 解决方法: 加入下列依赖,版本要和下载下来的{spring-boot-dependencies}一致.不一致就会报问题2: <parent> ...
- unity shader 波动圈
c# //////////////////////////////////////////// // CameraFilterPack - by VETASOFT 2018 ///// /////// ...
- vue如何实现热更新
我们都知道,对于node来说,前端vue代码的迭代节奏是很快的,可能一周要迭代几次,但是node的迭代却没那么平凡,可能一周更新一次甚至更久,那么为了node服务的稳定,减少node服务的发布次数,是 ...
- AGC035 A - XOR Circle【分析】
题目传送门 题意简述: (就是连环的意思) 唔,这道题考场上写了个什么神仙做法,数据太水了居然过了: // #include<cstdio> #include<algorithm&g ...