机器学习聚类算法之K-means
一、概念
K-means是一种典型的聚类算法,它是基于距离的,是一种无监督的机器学习算法。
K-means需要提前设置聚类数量,我们称之为簇,还要为之设置初始质心。
缺点:
1、循环计算点到质心的距离,复杂度较高。
2、对噪声不敏感,即使是噪声也会被聚类。
3、质心数量及初始位置的选定对结果有一定的影响。
二、计算
K-means需要循环的计算点到质心的距离,有三种常用的方法:
1、欧式距离
欧式距离源自N维欧氏空间中两点x,y间的距离公式,在二维上(x1,y1)到(x2,y2)的距离体现为:

在三维上体现为:
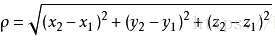
欧式距离是K-means最常用的计算距离的方法。
2、曼哈顿距离
在二维上(x1,y1)到(x2,y2)的距离体现为:

3、余弦夹角
余弦距离不是距离,而只是相似性,其他距离直接测量两个高维空间上的点的距离,如果距离为0则两个点“相同”;
余弦的结果为在[-1,1]之中,如果为 1,只能确定两者完全相关、完全相似。
在二维上(x1,y1)到(x2,y2)的距离体现为:
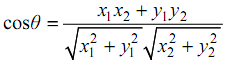
聚类的基本步骤:
1、设置质心个数,这代表最终聚类数;
2、根据质心个数随机生成初始质心点;
3、计算数据与质心距离,根据距离远近做第一次分类;
4、将聚类结果的中心点定义为新的质心,再进行3的计算;
5、循环迭代直到质心不再变化,此为最终结果。
3、实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt def create_sample():
np.random.seed(10) # 随机数种子,保证随机数生成的顺序一样
n_dim = 2
num = 100
a = 3 + 5 * np.random.randn(num, n_dim)
b = 18 + 4 * np.random.randn(num, n_dim)
data_mat = np.concatenate((a, b))
ay = np.zeros(num)
by = np.ones(num)
label = np.concatenate((ay, by))
return {'data_mat': data_mat, 'label': label} # arr[i, :] #取第i行数据
# arr[i:j, :] #取第i行到第j行的数据
# in:arr[:,0] # 取第0列的数据,以行的形式返回的
# in:arr[:,:1] # 取第0列的数据,以列的形式返回的 def k_mean(data_set, k):
m, n = np.shape(data_set) # 获取维度, 行数,列数
cluster_assignment = np.mat(np.zeros((m, 2))) # 转换为矩阵, zeros生成指定维数的全0数组,用来记录迭代结果
centroids = generate_centroids(k, n)
cluster_changed = True
while cluster_changed:
cluster_changed = False
for i in range(m):
min_distance = np.inf # 无限大的正数
min_index = -1
vec_b = np.array(data_set)[i, :] # i行数据,数据集内的点的位置
for j in range(k):
vec_a = np.array(centroids)[j, :] # j行数据, 中心点位置
distance = calculate_distance(vec_a, vec_b)
if distance < min_distance:
min_distance = distance
min_index = j
if cluster_assignment[i, 0] != min_index:
cluster_changed = True
cluster_assignment[i, :] = min_index, min_distance ** 2
update_centroids(data_set, cluster_assignment, centroids, k)
get_result(data_set, cluster_assignment, k) def generate_centroids(centroid_num, column_num):
centroids = np.mat(np.zeros((centroid_num, column_num))) # 生成中心点矩阵
for index in range(centroid_num):
# 随机生成中心点, np.random.rand(Random values in a given shape)
centroids[index, :] = np.mat(np.random.rand(1, column_num))
return centroids def calculate_distance(vec_a, vec_b):
distance = np.sqrt(sum(np.power(vec_a - vec_b, 2))) # power(x1, x2) 对x1中的每个元素求x2次方。不会改变x1上午shape。
return distance def update_centroids(data_set, cluster_assignment, centroids, k):
for cent in range(k):
# 取出对应簇
cluster = np.array(cluster_assignment)[:, 0] == cent
# np.nonzero取出矩阵中非0的元素坐标
pts_in_cluster = data_set[np.nonzero(cluster)]
# print(pts_in_cluster)
# mean() 函数功能:求取均值
# 经常操作的参数为axis,以m * n矩阵举例:
# axis : 不设置值, m * n 个数求均值,返回一个实数
# axis = 0:压缩行,对各列求均值,返回1 * n矩阵
# axis = 1 :压缩列,对各行求均值,返回m * 1矩阵
if len(pts_in_cluster) > 0:
centroids[cent, :] = np.mean(pts_in_cluster, axis=0) def get_result(data_set, cluster_assignment, k):
cs = ['r', 'g', 'b']
for cent in range(k):
ret_id = np.nonzero(np.array(cluster_assignment)[:, 0] == cent)
plot_data(data_set[ret_id], cs[cent])
plt.show() def plot_data(samples, color, plot_type='o'):
plt.plot(samples[:, 0], samples[:, 1], plot_type, markerfacecolor=color, markersize=14) data = create_sample()
k_mean(data['data_mat'], 2)
聚类结果:

机器学习聚类算法之K-means的更多相关文章
- Standford机器学习 聚类算法(clustering)和非监督学习(unsupervised Learning)
聚类算法是一类非监督学习算法,在有监督学习中,学习的目标是要在两类样本中找出他们的分界,训练数据是给定标签的,要么属于正类要么属于负类.而非监督学习,它的目的是在一个没有标签的数据集中找出这个数据集的 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 机器学习聚类算法之DBSCAN
一.概念 DBSCAN是一种基于密度的聚类算法,DBSCAN需要两个参数,一个是以P为中心的邻域半径:另一个是以P为中心的邻域内的最低门限点的数量,即密度. 优点: 1.不需要提前设定分类簇数量,分类 ...
- 机器学习分类算法之K近邻(K-Nearest Neighbor)
一.概念 KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确.而且KN ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 03-01 K-Means聚类算法
目录 K-Means聚类算法 一.K-Means聚类算法学习目标 二.K-Means聚类算法详解 2.1 K-Means聚类算法原理 2.2 K-Means聚类算法和KNN 三.传统的K-Means聚 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
随机推荐
- 百度地图api根据地址获取经纬度
package com.haiyisoft.cAssistant;import java.io.BufferedReader;import java.io.IOException; import ja ...
- Cannot find terminfo entry for 'linux'.
解决方案: 1. 查看 /usr/share/terminfo 目录下的内容,该目录的内容表示该主机支持哪些终端类型. 2. 通过修改系统变量TERM为vt100. 执行 export TERM=vt ...
- Python_序列对象内置方法详解_String
目录 目录 前言 软件环境 序列类型 序列的操作方法 索引调用 切片运算符 扩展切片运算符 序列元素的反转 连接操作符 重复运算符 成员关系符 序列内置方法 len 获取序列对象的长度 zip 混合两 ...
- 阶段3 2.Spring_04.Spring的常用注解_4 由Component衍生的注解
为什么要使用者三个注解 Controller:表现层 Service:业务层 Repository:持久层 在这里就是用Controller 运行也没问题 用Service Repository同样也 ...
- 使用Nginx做WebSockets代理教程
WebSocket 协议提供了一种创建支持客户端和服务端实时双向通信Web应用程序的方法.作为HTML5规范的一部分,WebSockets简化了开发Web实时通信程 序的难度.目前主流的浏览器都支持W ...
- 利用Python进行异常值分析实例代码
利用Python进行异常值分析实例代码 异常值是指样本中的个别值,也称为离群点,其数值明显偏离其余的观测值.常用检测方法3σ原则和箱型图.其中,3σ原则只适用服从正态分布的数据.在3σ原则下,异常值被 ...
- 【react】input输入框可输入的最好实现方式
使用的是refs.react中输入框不能直接定义value.输入框是可变的,react会提示报错.需要使用的inChange事件(输入框内容被改变时触发). 要定义输入框初始值,需要在componen ...
- 快速生成500W测试数据库
快速生成500W测试数据库: 创建测试表: DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id` int(10) NOT NULL AUTO_ ...
- String StringBuffer StringBuilder区别与联系
java.lang.String.java.lang.StringBuffer.java.lang.StringBuilder都是字符串类型,是Java中用于处理字符串常用的三个类.它们主要有以下区别 ...
- Neo4j下载与使用
Neo4j 官网 : https://neo4j.com/ Neo4j 国内: http://neo4j.com.cn/topic/5b003eae9662eee704f31cee http://we ...