java高并发核心要点|系列5|CPU内存伪共享
上节提到的:伪共享,今天我们来说说。
那什么是伪共享呢?
这得从CPU的缓存结构说起。以下如图,CPU一般来说是有三级缓存,1 级,2级,3级,越上面的,越靠近CPU的,速度越快,成本也越高。也就是说速度方面:1级>2级>3级。
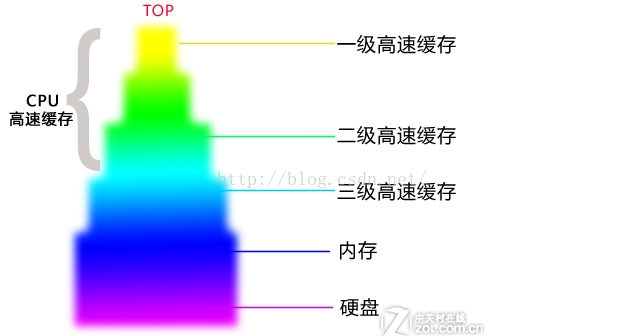
图1
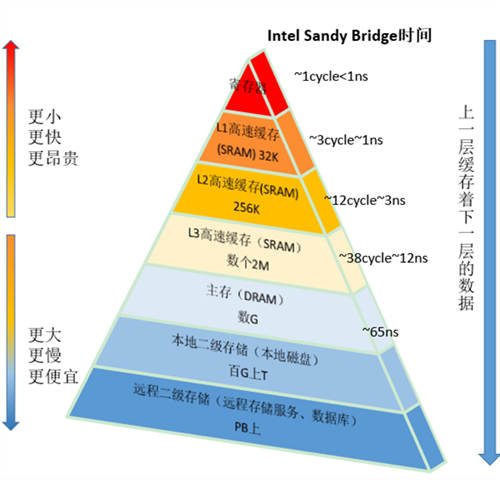
图2
如上图2我们来看看不同级别的缓存的时延:
| 到CPU的延迟 | CPU时钟 | 耗时 |
|---|---|---|
| 主内存 | 很多(Multiple) | ~60-80 ns |
| L3 缓存 | ~40-45 周期 | ~15 ns |
| L2 缓存 | ~10 周期 | ~3 ns |
| L1 缓存 | ~3-4 周期 | ~1 ns |
| 寄存器 | 一周期 | 小于1ns,飞快 |
更多CPU架构信息:https://blog.csdn.net/karamos/article/details/80126704
说到这里,我们要理解一个很重要的概念:缓存行。什么是缓存行?
首先我们来看这几级缓存,其中,1,2级缓存是CPU核心私有的,也就是说每个核,之间不会共享1,2级缓存,那它们之间怎么通信或共享数据呢?
答案是:3级缓存,如下图:
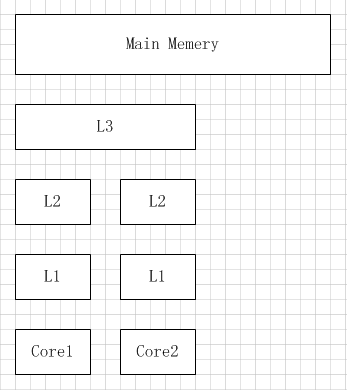
那core1,和core2之间,是通过什么方式共享缓存呢?
答案是:缓存行!
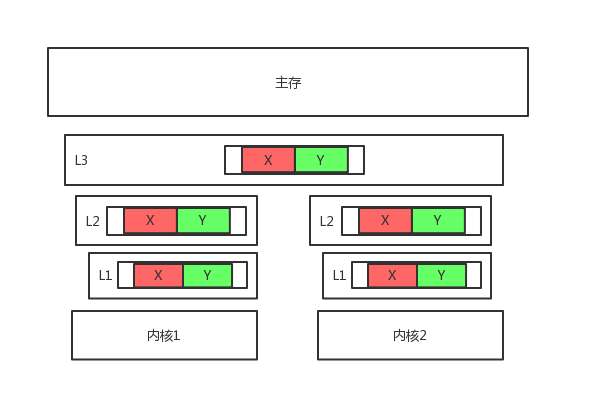
什么是缓存行?简单来说,就是CPU内核之间共享数据的最小单位。如下图:x,y是在同一个缓存行,那每次CPU内核之间通信时交换x,y值,可以同时共享两个值。是不是很高效?
是的,一般情况下,如果x,y是属于数组内的数据 ,是可以达到高效共享数据的功能,但问题又来了:如果,x,y并不属于同一数组,x属于core1,而y属于core2,这个时候,如果core1更新了x,会导致y值失效了。为什么失效了,因为他们在同一缓存行。这时,只有把缓存行 flush到主存后, 其他内核中的相应的缓存行才会被置为过期数据,而缓存行什么时候flush到memory, 这个是有一定延时的 ,在这个延时当中, 其他CPU core是无法得知你的更新的 。那么内核core2再去读取Y的值时,由于L1的缓存里的数据已失效,那么就需要从L3获取,然后放入L2,再放入L1。 这样核心2读取Y值就需要从L3级的缓存读了。但是明明是内核core1修改的X的值,却影响到内核2去读取Y值了。同理,如果是内核2去修改Y的值,也会影响内核1去读取X的值。
简单来说,x,y同放在缓存行,而且它们又属于不同CPU内核的数据值(事实上CPU内核也就是代码中的:线程)。那就会因为各自更新其中一个值,而导致缓存失效。
这就是著名的伪共享问题。
有没有什么解决方案呢?
有的。
方案是:缓存行填充。
还是回到上面的例子,如果x,y同放到同一个缓存行,会造成伪共享。很简单,那就不要放在一起好了!
比如:x有8byte(字节),而一般缓存行总共有64byte。那其他剩下的位置,我们就用预定的空变量填充就行了,代码如下 (java6版本):
public final static class VolatileLong {
public volatile long x= 0L;
public long p1, p2, p3, p4, p5, p6,p7; //缓存行填充
}
这个时候,core1更新x值,也就不会影响y值,从而造成伪共享问题。
上面的代码是java6的解决方案。
JAVA 8下的方案
在JAVA 8中,缓存行填充终于被JAVA原生支持了。JAVA 8中添加了一个@Contended的注解,添加这个的注解,将会在自动进行缓存行填充,如下代码:
import sun.misc.Contended;
@Contended
public class VolatileLong {
public volatile long value = 0L;
}
执行时,必须加上虚拟机参数-XX:-RestrictContended,@Contended注释才会生效。很多文章把这个漏掉了,那样的话实际上就没有起作用。
这就是伪共享的解决方案,多么简单!
本系列完毕!
如果各位读者,还有什么意见或建议,欢迎拍砖吐槽!
java高并发核心要点|系列5|CPU内存伪共享的更多相关文章
- java高并发核心要点|系列4|CPU内存指令重排序(Memory Reordering)
今天,我们来学习另一个重要的概念. CPU内存指令重排序(Memory Reordering) 什么叫重排序? 重排序的背景 我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多.当CP ...
- java高并发核心要点|系列文章
java高并发核心要点|系列1|开篇 java高并发核心要点|系列2|锁的底层实现原理 java高并发核心要点|系列3|锁的底层实现原理|ABA问题 java高并发核心要点|系列4|CPU内存指令重排 ...
- java高并发核心要点|系列1|开篇
在java高并发编程,有几个很重要的内容: 1.CAS算法 2.CPU重排序 3.缓存行伪共享 我们先来说说高并发世界中的主要关键问题是什么? 是数据共享. 因为多线程之间要共享数据,就会遇到各种问题 ...
- java高并发核心要点|系列2|锁的底层实现原理
上篇文章,我们主要讲了解决多线程之间共享数据的核心问题和解决方案,也讲了锁的简单分类. 那么,这把锁,我们应该怎么去实现呢?如果你是java语言设计者,你又会怎么去设计这个线程锁呢? 直觉告诉我们,我 ...
- java高并发核心要点|系列3|锁的底层实现原理|ABA问题
继续讲CAS算法,上篇文章我们知道,CAS算法底层实现,是通过CPU的原子指令来实现. 那么这里又有一个情景: 话说,有一个线程one从内存位置V中取出A,这时候另一个线程two也从内存中取出A,并且 ...
- 从菜鸟到大神:Java高并发核心编程(连载视频)
任何事情是有套路的,学习是如此, Java的学习,更是如此. 本文,为大家揭示 Java学习的套路 背景 Java高并发.分布式的中间件非常多,网上也有很多组件的源码视频.原理视频,汗牛塞屋了. 作为 ...
- java高并发核心类 AQS(Abstract Queued Synchronizer)抽象队列同步器
什么是AQS? 全称: Abstract Queued Synchronizer: 抽象队列同步器 是 java.util.concurrent.locks包下的一个抽象类 其编写者: Doug Le ...
- Java高并发和多线程系列 - 1. 线程基本概念
1. 什么是线程? 线程和进程的区别 在了解线程的概念前,我们应该先知道什么是进程? 进程是操作系统的基本概念之一, 它是正在执行的程序实例. * 下面的一些进程的基本概念你可以了解下 ------- ...
- 尼恩 Java高并发三部曲 [官方]
高并发 发烧友社群:疯狂创客圈(总入口) 奉上以下珍贵的学习资源: 疯狂创客圈 经典图书 : 极致经典 + 社群大片好评 < Java 高并发 三部曲 > 面试必备 + 大厂必备 + 涨薪 ...
随机推荐
- 关于Oracle报表
1.存储过程中的WHEN OTHERS THEN是什么意思. 异常分很多种类,如NO_FOUND.OTHERS处本应该写异常名称,如果不想把异常分得那么细,可以笼统一点用OTHERS来捕获,即所有异常 ...
- Fragment 的 replace 和 add 方法的区别?
Fragment 本身并没有 replace 和 add 方法,这里的理解应该为使用 FragmentManager 的 replace 和 add 两种方法切换 Fragment 时有什么不同.我们 ...
- python + 爬虫 + fiddler + 夜神模拟器 爬取app(1)
抓包 抓包是爬虫里面经常用到的一个词,完整的应该叫做抓取数据请求响应包 ,而Fiddler这款工具就是干这个的 普通https抓包设置 打开Fiddler ------> Options .然后 ...
- jquery 教程网
- 清除陷入CLOSE_WAIT的进程
netstat -nap |grep :8009|grep CLOSE_WAIT | awk '{print $7}'|awk -F"\/" '{print $1}' |awk ' ...
- java:JavaScript2:(setTimeout定时器,history.go()前进/后退,navigator.userAgent判断浏览器,location.href,五种方法获取标签属性,setAttribute,innerHTML,三种方法获取form表单信息,JS表单验证,DOM对象,form表单操作)
1.open,setTimeout,setInterval,clearInterval,clearTimeout <!DOCTYPE> <html> <head> ...
- 浏览器从输入URL到渲染出页面发生了什么
总体来说分为以下几个过程: 1. DNS解析 2. TCP连接 3. 发送HTTP请求 4. 服务器处理请求并返回HTTP报文 5. 浏览器解析渲染页面 6. 连接结束 参考资料:[https:// ...
- python学习之函数(二)
4.4.6 动态传参 动态传参是针对形参而言 1.动态位置参数 在静态位置参数时,我们知道,定义函数时有几个位置参数,调用时就必须给几个实参,不能多也不能少.有时候,实际应用过程中,参数往往不能固 ...
- 配置java开发环境,存在多个版本JDK时,怎样让所需版本生效
我本地有个1.7.0的java版本,后来我新装了一个13的版本,但是命令行查java版本的时候,生效的还是1.7.0的版本,经过资料查询以及自身亲测,现将过程记录如下: 1.电脑右键选择--属性--高 ...
- CentOS Linux修改默认Bash shell为Zsh shell
Shell是在程序员与服务器间建立一个桥梁,它对外提供一系列命令,让我们得以控制服务器.常用的Bash就是Shell的一种,也是Linux下默认Shell程序.这里介绍一种更强大的.更人性化的Shel ...