Task3.特征选择
参考:https://www.jianshu.com/p/f3b92124cd2b
互信息
衡量两个随机变量之间的相关性,两个随机变量相关信息的多少。
随机变量就是随机试验结果的量的表示,可以理解为按照某个概率分布进行取值的变量,比如袋子里随机抽取一个小球就是一个随机变量,互信息就是对x和y所有可能
的取值的点互信息的加权和。
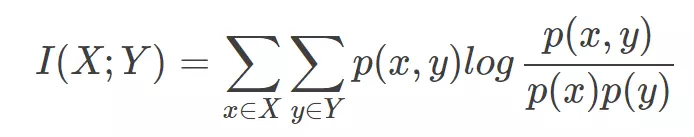
点的互信息PMI从互信息中衍生出来的
PMI用来衡量两个事物之间的相关性,公式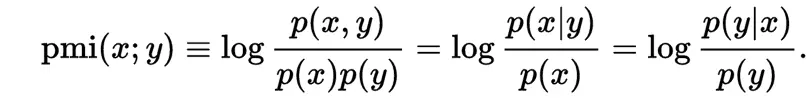
在概率论中,当p(x,y) = p(x) * p(y)我们说x于y相互独立。当概率加上log后,就变成了信息量。
例子:
衡量like这个词的极性(为正向情感还是负向情感),提前调一个正向情感的词如nice,算nice和like的PMI
PMI(like,nice) = log(p(like,nice)/p(like)p(nice))。PMI越大表示两个词的相关性就越大,nice的正向情感就越明显。
编程求解互信息:
from sklearn import metrics as mr
mr.mutual_info_score([1,2,3,4],[4,3,2,1])
tf-idf
tf:Term Frequency 词频
idf: Inverse Document Frequency逆文档频率
在开始,我们用词频来衡量一个词的重量程度,这一点是不科学的,如进行简历筛选时,大部分人都有的技能并不是HR想要寻找的,反而是那些出现频率低的。
所以就出现了idf。
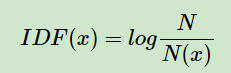
N代表语料库中文本的总数,N(x)代表语料库中包含x的文本数目。可见出现的频率越低,IDF值越大。
避免0概率事件,我们要进行平滑。

右边+1是为了避免该词在所有文本中都出现过,(N(x) = N ,log1=0)。
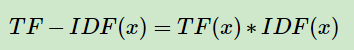
TF(x)指词在当前文本中的词频。
利用sklearn进行统计tfidf值
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'this is the first document',
'this is the second second document',
'and the third one',
'is this the first document'
]
tfidf = TfidfVectorizer()
res = tfidf.fit_transform(corpus)
print(res)
(0, 8) 0.4387767428592343
(0, 3) 0.4387767428592343
(0, 6) 0.35872873824808993
(0, 2) 0.5419765697264572
(0, 1) 0.4387767428592343
(1, 8) 0.27230146752334033
(1, 3) 0.27230146752334033
(1, 6) 0.2226242923251039
(1, 1) 0.27230146752334033
(1, 5) 0.8532257361452784
(2, 6) 0.2884767487500274
(2, 0) 0.5528053199908667
(2, 7) 0.5528053199908667
(2, 4) 0.5528053199908667
(3, 8) 0.4387767428592343
(3, 3) 0.4387767428592343
(3, 6) 0.35872873824808993
(3, 2) 0.5419765697264572
(3, 1) 0.4387767428592343
输出结果为:(文本id,词id)tfidf值
Task3.特征选择的更多相关文章
- 挑子学习笔记:特征选择——基于假设检验的Filter方法
转载请标明出处: http://www.cnblogs.com/tiaozistudy/p/hypothesis_testing_based_feature_selection.html Filter ...
- 用信息值进行特征选择(Information Value)
Posted by c cm on January 3, 2014 特征选择(feature selection)或者变量选择(variable selection)是在建模之前的重要一步.数据接口越 ...
- MIL 多示例学习 特征选择
一个主要的跟踪系统包含三个成分:1)外观模型,通过其可以估计目标的似然函数.2)运动模型,预测位置.3)搜索策略,寻找当前帧最有可能为目标的位置.MIL主要的贡献在第一条上. MIL与CT的不同在于后 ...
- 【转】[特征选择] An Introduction to Feature Selection 翻译
中文原文链接:http://www.cnblogs.com/AHappyCat/p/5318042.html 英文原文链接: An Introduction to Feature Selection ...
- 单因素特征选择--Univariate Feature Selection
An example showing univariate feature selection. Noisy (non informative) features are added to the i ...
- 主成分分析(PCA)特征选择算法详解
1. 问题 真实的训练数据总是存在各种各样的问题: 1. 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余. 2. 拿到 ...
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
原文 http://dataunion.org/14072.html 主题 特征选择 scikit-learn 作者: Edwin Jarvis 特征选择(排序)对于数据科学家.机器学习从业者来说非 ...
- 【Machine Learning】wekaの特征选择简介
看过这篇博客的都应该明白,特征选择代码实现应该包括3个部分: 搜索算法: 评估函数: 数据: 因此,代码的一般形式为: AttributeSelection attsel = new Attribut ...
- weka特征选择(IG、chi-square)
一.说明 IG是information gain 的缩写,中文名称是信息增益,是选择特征的一个很有效的方法(特别是在使用svm分类时).这里不做详细介绍,有兴趣的可以googling一下. chi-s ...
随机推荐
- leetcode-mid-array-31 three sum-NO
my code: time limited def threeSum(nums): """ :type nums: List[int] :rtype: List[L ...
- linux设置开机启动程序?
/etc/rc.d/init.d 是 /etc/init.d的目标链接. 如果/etc/rc.d下面没有 rc.local脚本文件, 则需要 手动创建: 而 /etc/bashrc 是在登陆bash ...
- django 给数据库批量添加数据
from .models import Book import random def index(request): book_list = [] for i in range(1, 101): bo ...
- mysql的小练习
建立如下表: 建表语句: class表创建语句 create table class(cid int not null auto_increment primary key, caption varc ...
- php-fpm启动不起来,php-fpm无法启动的一种情况
今天碰了一个很奇怪的问题,平时好好的php-fpm修改了一个参数后,突然启动不起来了,试着把参数还原.甚至用备份的配置文件还原都没办法启动php,而且不给任务启动错误的提示,纳闷!!!后来上网找了个资 ...
- Python笔记(二十二)_魔法方法_基本魔法方法
__init__(self[,...]) __init__和__new__组成python的构造器,但__init__更多的是负责初始化操作,相当于一个项目中的配置文件,__new__才是真正的构造函 ...
- 从新向你学习javase(第一天)
1:阐述JDK和JRE之间区别 jdk(工具)>jre(运行环境)>jvm(虚拟机) 2: 能够使用常见的DOS命令 d:(进入D盘下),cd +路径(进入到当前路径),cd..(返回上一 ...
- Java第三周总结&实验报告(1)
总结:不知不觉,到了第三周,回顾这一周,我更加深入了解了main方法,除此之外,学习了两个关键字,一个this,一个static,this在强调属性时,只能放在句首且不能循环调用,static声明用于 ...
- Docker实战部署应用——Redis
Redis 部署 拉取Redis镜像 docker pull redis 创建Redis容器 docker run -id --name=sun_redis -p 6379:6379 redis 客户 ...
- open, creat - 用来 打开和创建 一个 文件或设备
SYNOPSIS 总览 #includ e <sys/types.h> #include <sys/stat.h> #include <fcntl.h> int o ...