spark编译安装 spark 2.1.0 hadoop2.6.0-cdh5.7.0
1、准备:
centos 6.5
jdk 1.7
Java SE安装包下载地址:http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html
maven3.3.9
Maven3.3.9安装包下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache//maven/maven-3/3.3.9/binaries/
spark 2.1.0 下载
http://spark.apache.org/downloads.html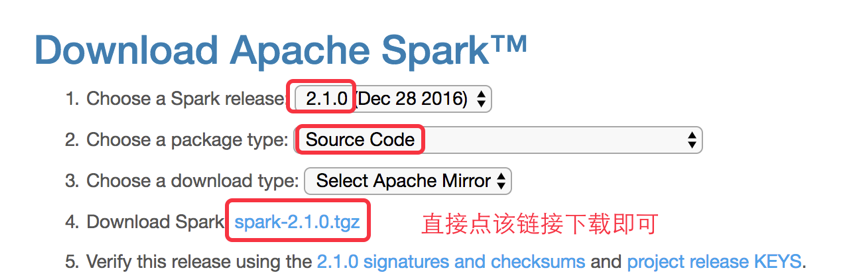
下载后文件名:

***************************************************分界线 编译开始*********************************************************************
上传到linux
安装maven,解压,配置环境变量
在此略掉...
mvn-v

说明mvn就已经没问题
*************************************************************分界线***********************************************************************************
我的hadoop版本是hadoop2.6.0-cdh5.7.0
解压spark源码包

得到源码包

忽略我这边已经编译好的spark安装包
先设置maven的内存,不然会有问题,直接设置临时的
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
[root@master109 opt]# echo $MAVEN_OPTS
-Xmx2g -XX:ReservedCodeCacheSize=512m
进入spark源码主目录

./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -Pyarn
结果:
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 9.810 s (Wall Clock)
[INFO] Finished at: 2017-10-13T15:52:09+08:00
[INFO] Final Memory: 67M/707M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project spark-launcher_2.11: Could not resolve dependencies for project org.apache.spark:spark-launcher_2.11:jar:2.1.0: Failure to find org.apache.hadoop:hadoop-client:jar:2.6.0-cdh5.7.0 in https://repo1.maven.org/maven2 was cached in the local repository, resolution will not be reattempted until the update interval of central has elapsed or updates are forced -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :spark-launcher_2.11
编译失败,显示没有找到一些包,这里是数据源不对,默认的是Apache的源,这里要改成cdh的源
编辑 pom.xml
[root@master109 spark-2.1.0]# ls
appveyor.yml bin common CONTRIBUTING.md data docs external launcher licenses mllib NOTICE project R repl scalastyle-config.xml streaming tools
assembly build conf core dev examples graphx LICENSE mesos mllib-local pom.xml python README.md sbin sql target yarn
[root@master109 spark-2.1.0]# vim pom.xml
在如下位置插入
#---------------------------------------------
中间的内容,改变数据源。记住,删掉上下的分隔符。
#---------------------------------------------
<repositories>
<repository>
<id>central</id>
<!-- This should be at top, it makes maven try the central repo first and then others and hence faster dep resolution -->
<name>Maven Repository</name>
<url>https://repo1.maven.org/maven2</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository> #---------------------------------------------
<repository>
<id>cloudera</id>
<name>cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>
#---------------------------------------------
</repositories>
重新编译开始:
[root@master109 spark-2.1.0]# ./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -Pyarn
等待几分钟:
[INFO] Reactor Summary:
[INFO]
[INFO] Spark Project Parent POM ........................... SUCCESS [ 3.997 s]
[INFO] Spark Project Tags ................................. SUCCESS [ 3.394 s]
[INFO] Spark Project Sketch ............................... SUCCESS [ 14.061 s]
[INFO] Spark Project Networking ........................... SUCCESS [ 37.680 s]
[INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 12.750 s]
[INFO] Spark Project Unsafe ............................... SUCCESS [ 33.158 s]
[INFO] Spark Project Launcher ............................. SUCCESS [ 50.148 s]
[INFO] Spark Project Core ................................. SUCCESS [04:16 min]
[INFO] Spark Project ML Local Library ..................... SUCCESS [ 45.832 s]
[INFO] Spark Project GraphX ............................... SUCCESS [ 26.712 s]
[INFO] Spark Project Streaming ............................ SUCCESS [ 58.080 s]
[INFO] Spark Project Catalyst ............................. SUCCESS [02:22 min]
[INFO] Spark Project SQL .................................. SUCCESS [03:02 min]
[INFO] Spark Project ML Library ........................... SUCCESS [02:16 min]
[INFO] Spark Project Tools ................................ SUCCESS [ 2.588 s]
[INFO] Spark Project Hive ................................. SUCCESS [01:19 min]
[INFO] Spark Project REPL ................................. SUCCESS [ 6.337 s]
[INFO] Spark Project YARN Shuffle Service ................. SUCCESS [ 13.252 s]
[INFO] Spark Project YARN ................................. SUCCESS [ 57.556 s]
[INFO] Spark Project Hive Thrift Server ................... SUCCESS [ 45.074 s]
[INFO] Spark Project Assembly ............................. SUCCESS [ 7.410 s]
[INFO] Spark Project External Flume Sink .................. SUCCESS [ 30.214 s]
[INFO] Spark Project External Flume ....................... SUCCESS [ 19.359 s]
[INFO] Spark Project External Flume Assembly .............. SUCCESS [ 6.082 s]
[INFO] Spark Integration for Kafka 0.8 .................... SUCCESS [ 30.266 s]
[INFO] Spark Project Examples ............................. SUCCESS [ 28.668 s]
[INFO] Spark Project External Kafka Assembly .............. SUCCESS [ 6.919 s]
[INFO] Spark Integration for Kafka 0.10 ................... SUCCESS [ 30.811 s]
[INFO] Spark Integration for Kafka 0.10 Assembly .......... SUCCESS [ 6.551 s]
[INFO] Kafka 0.10 Source for Structured Streaming ......... SUCCESS [ 17.707 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 13:25 min (Wall Clock)
[INFO] Finished at: 2017-10-13T16:35:47+08:00
[INFO] Final Memory: 90M/979M
[INFO] ------------------------------------------------------------------------
完事!
2017-10-13 16:55:55
作者by :山高似水深(http://www.cnblogs.com/tnsay/)转载注明出处。
spark编译安装 spark 2.1.0 hadoop2.6.0-cdh5.7.0的更多相关文章
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- 编译安装spark 1.5.x(Building Spark)
原文连接:http://spark.apache.org/docs/1.5.0/building-spark.html · Building with build/mvn · Building a R ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark编译安装和运行
一.环境说明 Mac OSX Java 1.7.0_71 Spark 二.编译安装 tar -zxvf spark-.tgz cd spark- ./sbt/sbt assembly ps:如果之前执 ...
- Spark编译及spark开发环境搭建
最近需要将生产环境的spark1.3版本升级到spark1.6(尽管spark2.0已经发布一段时间了,稳定可靠起见,还是选择了spark1.6),同时需要基于spark开发一些中间件,因此需要搭建一 ...
- Cenos7 编译安装 Mariadb Nginx PHP Memcache ZendOpcache (实测 笔记 Centos 7.0 + Mariadb 10.0.15 + Nginx 1.6.2 + PHP 5.5.19)
环境: 系统硬件:vmware vsphere (CPU:2*4核,内存2G,双网卡) 系统版本:CentOS-7.0-1406-x86_64-DVD.iso 安装步骤: 1.准备 1.1 显示系统版 ...
- hadoop2.3.0cdh5.0.2 升级到cdh5.7.0
后儿就放假了,上班这心真心收不住,为了能充实的度过这难熬的两天,我决定搞个大工程.....ps:我为啥这么期待放假呢,在沙发上像死人一样躺一天真的有意义嘛....... 当然版本:hadoop2.3. ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark编译与部署
Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建 [注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.S ...
随机推荐
- python基础之模块一
一 time模块 时间表示形式 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的时间字符串:(1)时间戳(timestamp) :通常来说,时间戳表示的是 ...
- 点击bindingNavigatorAddNewItem 关联的dataGridView不会新增一行
方法一. 在设计界面,修改bindingNavigator1的属性AddNewItem 为“(无)”: 方法二. 在设计器自动生成的代码中找到这一行: // bindingNa ...
- PostgreSQL流复制记录
参考了别人的部分,添加了自己在实践中的内容,仅做记录. 1.同步流复制中 主机操作 1.1postgresql.conf wal_level = hot_standby # 这个是设置主为wal的主机 ...
- git合并分支与解决冲突
前提: 当前开发的分支为feature/20161129_317606_algoplatform_1,由于feature/20161130_322574_tmstools_1分支有新内容,所以准备将f ...
- Kali Linux破解wifi密码(WEP)
WEP是无线路由器最初广泛使用的一种加密方式,这种加密方式非常容易被破解. 目前很少有人使用wep加密方式,但是还是会有. 建议:使用WPA/WPA2做为加密方式. 抓包和"破解wpa/wp ...
- Java Web 高性能开发,前端的高性能
Java Web 高性能开发,第 2 部分: 前端的高性能 Web 发展的速度让许多人叹为观止,层出不穷的组件.技术,只需要合理的组合.恰当的设置,就可以让 Web 程序性能不断飞跃.Web 的思想是 ...
- 完整的验证码识别流程基于svm(若是想提升,可优化)
字符型图片验证码识别完整过程及Python实现 首先很感觉这篇文章的作者,将这篇文章写的这么好.我呢,也是拿来学习,觉得太好,所以忍不住就进行了转载. 因为我个人现在手上也有个验证码识别的项目,只是难 ...
- SqlServer 数据库读写分离【转】
1. 实现原理:读写分离简单的说是把对数据库读和写的操作分开对应不同的数据库服务器,这样能有效地减轻数据库压力,也能减轻io压力.主数据库提供写操作,从数据库提供读操作,其实在很多系统中,主要是读的操 ...
- eclipse配置storm1.1.0开发环境并本地跑起来
storm的开发环境搭建比hadoop(参见前文http://www.cnblogs.com/wuxun1997/p/6849878.html)简单,无需安装插件,只需新建一个java项目并配置好li ...
- Erlang基础 -- 介绍 -- 历史及Erlang并发
前言 最近在总结一些Erlang编程语言的基础知识,拟系统的介绍Erlang编程语言,从基础到进阶,然后再做Erlang编程语言有意思的库的分析. 其实,还是希望越来越多的人关注Erlang,使用Er ...