R语言学习3:数据框处理(1)
本系列是一个新的系列,在此系列中,我将和大家共同学习R语言。由于我对R语言的了解也甚少,所以本系列更多以一个学习者的视角来完成。
参考教材:《R语言实战》第二版(Robert I.Kabacoff),书中所提到的John Cook的优秀博文,关于代码规范的《来自Google的R语言编码风格指南》。
Part 1:变量管理
Section 1:创建变量——transform()
为数据框创建新变量,可以使用数据框的$运算符,如果df$variable中variable不属于原数据框,则会创建一个新的数据框。
mydata <- data.frame(
x1 = c(2, 2, 6, 4),
x2 = c(3, 4, 2, 8)
)
mydata$sumx <- mydata$x1 + mydata$x2
mydata$meanx <- mydata$sumx / 2
使用transform()函数,能更方便地创建新变量,其用法是:
mydata <- data.frame(
x1 = c(2, 2, 6, 4),
x2 = c(3, 4, 2, 8)
)
mydata <- transform(mydata,
sumx = x1 + x2,
meanx = (x1 + x2)/2)
除此外,transform()函数也能方便地对数据框执行修改,生成一个修改后的映像。
Section 2:变量的重编码——within()
变量的重编码,指的是根据变量的现有值创建新值的过程,如分箱、纠正错误值等。
为方便以下内容的示范,使用书中给出的原始数据框:
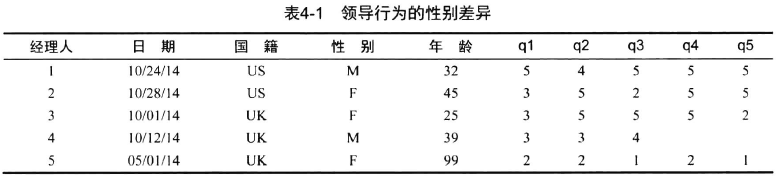
manager <- c(1, 2, 3, 4, 5)
date <- c("10/24/14", "10/28/14", "10/01/14", "10/12/14", "05/01/14")
country <- c("US", "US", "UK", "UK", "UK")
gender <- c("M", "F", "F", "M", "F")
age <- c(32, 45, 25, 39, 99)
q1 <- c(5, 3, 3, 3, 2)
q2 <- c(4, 5, 5, 3, 2)
q3 <- c(5, 2, 5, 4, 1)
q4 <- c(5, 5, 5, NA, 2)
q5 <- c(5, 5, 2, NA, 1)
leadership <- data.frame(manager, date, country, gender, age,
q1, q2, q3, q4, q5, stringsAsFactors = F)
条件赋值语句可以在条件为TRUE时,为向量的相应位置执行赋值,其用法为
variable[condition] <- expression # 这里condition是一个条件向量
结合within()函数,可以方便地为数据框执行重编码,within()函数的语法与with()类似,但with()只允许方便地调用数据框中的变量,而within()还允许修改数据框。如,为leadership数据框中的agecat执行重编码:
leadership$age[leadership$age == 99] <- NA # 将异常值编码为NA
leadership <- within(leadership,{
agecat <- NA
agecat[age > 75] <- "Elder"
agecat[age <= 75 & age >= 55] <- "Middle Aged"
agecat[age < 55] <- "Young"
})
Section 3:变量重命名——names()
对变量名称不满意,可以使用fix(df)函数,交互式地更改变量名称,也可以使用names()函数。如
names(leadership)[2] <- "testDate"
names(leadership)[6:10] <- c("item1", "item2", "item3", "item4", "item5")
或使用plyr包中的rename函数修改变量名。
leadership <- rename(leadership, c(manager="managerID"))
Part 2:值处理
Section 1:缺失值
缺失值以符号NA表示,意为Not Available,它是不可比较的(即使是x == NA也不行,只能用is.na(x))。在R语言中,缺失值与Inf(正无穷)、-Inf(负无穷)、NaN(不是一个数,Not a Number)不同,以上是它们的符号。
需要注意,含有缺失值的算术表达式和函数的计算结果也是缺失值。多值函数一般拥有na.rm参数,如果想要在计算时免除缺失值的影响,需要指定na.rm=T。
> x <- c(1, 2, NA, 3)
> sum(x)
[1] NA
> sum(x, na.rm=T)
[1] 6
对于数据框,如果缺失值只集中于一小部分观测,可以使用行删除手段,具体地,可以使用na.omit()函数,对所有含缺失值的观测进行删除。
newdata <- na.omit(leadership) # 函数生成的是一个映像,不会对原数据框产生影响
newdata
Section 2:日期值——as.Date()
要获得当前的日期,可以使用Sys.Date()函数;要获得当前的日期与时间,可以使用date()函数。
> date()
[1] "Fri Feb 19 13:56:35 2021"
> Sys.Date()
[1] "2021-02-19"
在R语言中,日期值常常是以字符串的形式输入的,然后需要使用as.Date()函数转化成数值形式存储的日期,其语法为
as.Date(x, "input_format")
这里,input_format是用于读入日期的适当格式,默认为yyyy-mm-dd(年月日),其他格式化符号如下表。

对于本例,时间格式mm/dd/yy,所以应当使用如下的修改编码:
myformat <- "%m/%d/%y" # 编码以字符串形式存储
leadership$date <- as.Date(leadership$date, myformat)
要改变日期的格式以输出,可以使用format()函数,其使用格式是
format(x, format="output_format")
---
> m <- Sys.Date()
> format(m, format="%Y/%m/%d")
[1] "2021/02/19"
计算日期之间的差值,可以使用difftime()函数,其使用格式是
difftime(date1, date2, units)
这里units是时间单位,可以使用"auto", "secs", "mins", "days", "weeks"等。
with(leadership, {
difftime(date[2], date[1], units = "days")
})
Time difference of 4 days
最后,要将日期转化为字符串,使用as.character()函数。
Section 3:类型转换
要判断某个值是否是某个类型,使用is.datatype()函数;将数值转换为某个类型,使用as.datatype()函数。

其中,is.datatype()返回一个TRUE或FALSE,可以用于控制流。
Part 3:数据框处理
Section 1:排序
使用order()函数可以对向量进行排序,order()会对向量重新编码,接受若干个等长向量分别作为排序的有序关键字。
> x <- c("a", "e", "d", "d", "c", "b")
> y <- c(6, 5, 4, 3, 2, 1)
> order(x)
[1] 1 6 5 3 4 2
> order(x, y) # y作为第二排序标准
[1] 1 6 5 4 3 2
对数据框,也可以使用order()函数作为条件排序,其原理是数据框可以按照一个有序向量进行排序。
with(leadership, {
newdata2 <<- leadership[order(gender, -age), 1:5]
})
> newdata2
managerID date country gender age
2 2 2014-10-28 US F 45
3 3 2014-10-01 UK F 25
5 5 2014-05-01 UK F NA
4 4 2014-10-12 UK M 39
1 1 2014-10-24 US M 32
注意,如果想要呈现完整的数据框,[contidion, ]中逗号是不能省略的。
Section 2:数据框合并
横向合并:即实现两个数据框的内连接,通过一个或多个共有变量,可以使用merge()函数,其用法为
total <- merge(dataframeA, dataframeB, by="ID") # by指定共有字段
如果不需要考虑外键,只是简单地横向合并,可以使用cbind()函数,这要求每个对象拥有相同的行数,以相同的顺序排序。
纵向合并:即向数据框中增加观测值,可以使用rbind()函数,这要求两个数据框拥有相同的变量个数(对顺序没有要求)。
total <- rbind(dataframeA, dataframeB)
如果两个数据框中变量不同,需要进行预处理:要么删除dataframeA中的多余变量,要么在dataframeB中创建追加的变量,并将其值设为NA。
Section 3:数据框取子集
选入变量:使用dataframe[, colindex]即可,这里colindex是变量的索引。事实上,如果需要保留全部观测值,可以直接使用dataframe[colindex]而并不需要逗号。另外,列索引也可以用变量名,如
myvars <- c("q1", "q2", "q3", "q4", "q5")
newdata <- leadership[myvars]
> newdata
q1 q2 q3 q4 q5
1 5 4 5 5 5
2 3 5 2 5 5
3 3 5 5 5 2
4 3 3 4 NA NA
5 2 2 1 2 1
删除变量:可以使用如下的语句来删除q4,q5两个变量。
myvars <- names(leadership) %in% c("q4", "q5")
newdata <- leadership[!myvars]
这里,myvars是一个逻辑变量,除了q4和q5是T以外其他地方都是F,因此取反,表示除了q4和q5是F外其他都是T(需要保留)。
另外,如果知道q4和q5是第9、第10个变量,可以简单使用
newdata <- leadership[c(-9, -10)]
进行删除。
选入观测:选入观测也可以使用逻辑变量。现在,选入观测时间在2009-01-01到2014-10-20之间的观测值,这里which。
startdate <- as.Date("2009-01-01")
enddate <- as.Date("2014-10-20")
newdata <- leadership[leadership$date >= startdate & leadership$date <= enddate, ] # 逗号必须保留
选择数据框的子集,最简单的方法是使用subset()函数,它可以一次性完成以上的功能,其使用格式如下:
subset(x, subset, select)
这里,x是要传入的数据框,subset是要保留观测的逻辑向量,select是要保留变量的向量。
newdata <- subset(
leadership, gender == "M" & age > 25,
select = gender:q4
)
> newdata
gender age q1 q2 q3 q4
1 M 32 5 4 5 5
4 M 39 3 3 4 NA
可以看到,保留变量的向量可以直接用from:to表达式,且from和to可以不必是数值。
如要随机抽取观测,可以使用sample()函数,其用法是
sample(x, size, replace=FALSE)
这里,x表示抽样元素组成的向量,size表示要抽取的元素数量,replace表示是否是有放回抽样。要是从数据集中抽样,可以如此使用:
newsample <- leadership[sample(1:nrow(leadership), 3, replace=F), ]
Section 4:使用SQL查询
如果是较大的数据集,可以使用SQL语句进行查找,这依赖于sqldf库中的sqldf函数。
library(sqldf)
attach(mtcars)
search <- "SELECT * FROM mtcars WHERE carb=1 ORDER BY mpg"
newdf <- sqldf(search, row.names=T)
sqldf中还有许多可选择的参数,如stringsAsFactors、row.names等。
R语言学习3:数据框处理(1)的更多相关文章
- R语言Data Frame数据框常用操作
Data Frame一般被翻译为数据框,感觉就像是R中的表,由行和列组成,与Matrix不同的是,每个列可以是不同的数据类型,而Matrix是必须相同的. Data Frame每一列有列名,每一行也可 ...
- 转载:R语言Data Frame数据框常用操作
Data Frame一般被翻译为数据框,感觉就像是R中的表,由行和列组成,与Matrix不同的是,每个列可以是不同的数据类型,而Matrix是必须相同的. Data Frame每一列有列名,每一行也可 ...
- R语言学习——处理数据对象的实用函数
length(object) # 显示对象中元素/成分的数量 dim(boject) # 显示某个对象的维度 str(object) # 显示某个对象的结构 class(object) # 显示某个对 ...
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- [译]用R语言做挖掘数据《二》
数据探索 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到程序: ...
- R语言分析朝阳医院数据
R语言分析朝阳医院数据 本次实践通过分析朝阳医院2016年销售数据,得出“月均消费次数”.“月均消费金额”.“客单价”.“消费趋势”等结果,并据此作出可视化图形. 一.读取数据: library(op ...
- R语言学习 第十篇:操作符
运算符是R语言中最基础的存在,熟悉运算符的使用,是熟练使用R处理数据的基础,操作符,顾名思义,是对数据进行运算的符号,R有自己的一套操作符,实现变量的赋值,引用,运算等功能. 一,赋值符号 为变量赋值 ...
- R语言学习——图形初阶之散点图
使用R内置的数据框mtcars,绘制车身重量与每加仑汽油行驶的英里数的散点图,要求横轴为车身重量(wt),纵轴为每加仑汽油行驶的英里数(mpg),并添加最优拟合曲线.标题,输出为pdf文件.代码实现如 ...
- R语言实现金融数据的时间序列分析及建模
R语言实现金融数据的时间序列分析及建模 一 移动平均 移动平均能消除数据中的季节变动和不规则变动.若序列中存在周期变动,则通常以周期为移动平均项数.移动平均法可以通过数据显示出数据长期趋势的变动 ...
- R语言处理Web数据
R语言处理Web数据 许多网站提供的数据,以供其用户的消费.例如,世界卫生组织(WHO)提供的CSV,TXT和XML文件的形式的健康和医疗信息报告.基于R程序,我们可以通过编程提取这些网站的具体数据. ...
随机推荐
- Centos8上安装Redis5.X
一.下载Redis 下载地址:wget http://download.redis.io/releases/redis-5.0.7.tar.gz 解压:tar -xzvf redis-5.0.7.ta ...
- [golang] 概念: struct vs interface
struct vs interface go语言的简化哲学: class = struct + receiver method set 注意: go 语言的struct,在参数传递中,是值拷贝. st ...
- MacOS安装多个jdk
环境 Mac os 为Yosemite 10.10.5版本,想要同时使用jdk7和jdk8. 下载jdk:http://www.Oracle.com/technetwork/Java/javase/d ...
- DataGear 制作支持表单交互和多图表联动的数据可视化看板
对于数据可视化,有时需要根据用户输入的查询条件展示限定范围的数据图表,DataGear的看板表单功能可以快速方便地实现此类需求. 下面的看板示例,包含一个柱状图.一个饼图和一个地图,用户可以通过看板表 ...
- 【Azure 应用服务】如何禁止chinacloudsites.cn 访问?
问题描述 Azure App Service创建后,默认会有一个 Azure App Service创建后,默认会有一个 https://xxxxxxxxxxxxx.chinacloudsites. ...
- mvc-mvp-mvvm架构调研及实现--分布式课程思考题--zzb
目录 I. 引言 2 研究背景和动机 2 问题陈述和研究目标 2 II. 相关工作 3 研究现状和相关技术 3 MVC模式的研究现状和相关技术: 3 MVP模式的研究现状和相关技术: 4 MVVM ...
- Glide源码解析四(解码和转码)
本文基于Glide 4.11.0 Glide加载过程有一个解码过程,比如将url加载为inputStream后,要将inputStream解码为Bitmap. 从Glide源码解析一我们大致知道了Gl ...
- 理解LLMOps: Large Language Model Operations
理解LLMOps: Large Language Model Operations 对于像我一样的小白来说,本文是一篇非常不错的LLMs入门介绍文档.来自:Understanding LLMOps: ...
- Java 常用类 String类与其他结构之间的转换-----String 与 byte[]之间的转换
1 /** 2 * 3 * String 与 byte[]之间的转换 4 * 编码:String ---> byte[]:调用String的getBytes() 5 * 解码:byte[]--- ...
- Java 常用类 String的常用方法(3)
1 /** 2 * String常用方法3 3 * 替换: 4 * String replace(char oldChar,char newChar): 返回一个新的字符串,它是通过 5 * 用new ...