分组聚合不再难:Pandas groupby使用指南
处理大量数据时,经常需要对数据进行分组和汇总,groupby为我们提供了一种简洁、高效的方式来实现这些操作,从而简化了数据分析的流程。
1. 分组聚合是什么
分组是指根据一个或多个列的值将数据分成多个组,每个组包含具有相同键值(这里的键值即用来分组的列值)的数据行。
聚合或者汇总则是指,在分组后,可以对每个组应用聚合函数(如求和、平均值、计数等),从而得到每个组的汇总信息。
2. 准备数据
下面的示例中使用的数据采集自A股2024年1月和2月的真实交易数据。
数据下载地址:https://databook.top/。
导入数据:
import pandas as pd
fp = r'D:\data\2024\历史行情数据-不复权-2024.csv'
df = pd.read_csv(fp)
df = df.loc[:, ["股票代码", "日期", "开盘", "收盘", "最高", "最低", "成交量"]]
df

3. groupby 使用示例
下面通过具体的示例演示groupby常用的使用方法。
3.1. 单列分组再聚合
单列聚合是指针对某一列汇总计算,比如:
针对“股票代码”聚合,看看不同股票的开盘价和收盘价的平均值。
# 只保留需要的列
data = df.loc[:, ["股票代码", "开盘", "收盘"]]
# 根据股票代码聚合平均值
data.groupby(by=["股票代码"]).mean()
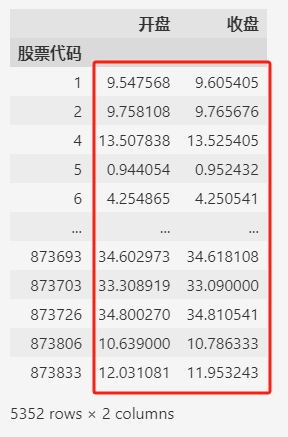
一共5352支股票,聚合之后,红色框内的是每支股票开盘价和收盘价的平均值。
3.2. 多列分组再聚合
多列分组聚合时,按照groupby中by参数的顺序,依次进行分组,然后再聚合。
本次的使用的数据包含2024年1月和2月的数据,
我们先按照“股票代码”分组,再按“月份”分组,最后汇总信息。
聚合之前,先把日期的格式转换成月的形式:
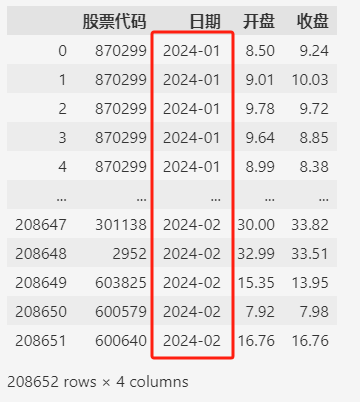
data = df.loc[:, ["股票代码", "日期", "开盘", "收盘"]]
data["日期"] = data["日期"].str.slice(0, 7)
data
根据“股票代码”和“日期”来聚合每支股票每个月的开盘价和收盘价的最大值:
data.groupby(by=["股票代码", "日期"]).max()
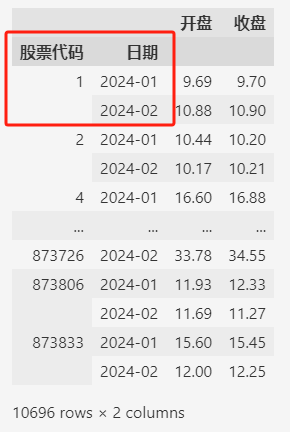
聚合之后的DataFrame,有2个Index(索引)。
3.3. 一次分组多次聚合
聚合汇总信息时,可以一次汇总多个信息,这样分组一次就可以了,不用每次聚合都重复调用groupby去分组。
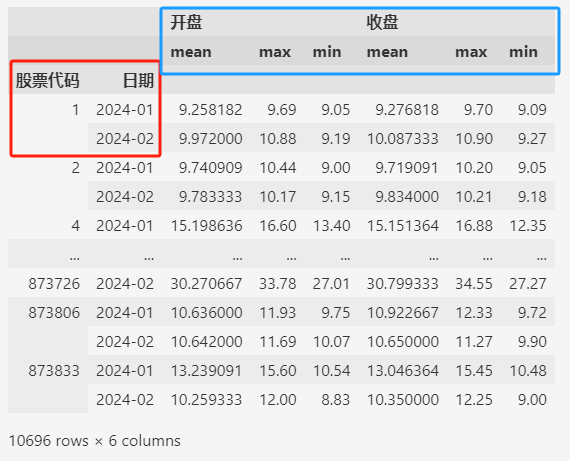
比如,下面的示例一次汇总出每支股票每个月开盘价和收盘价的最大值,最小值,平均值:
data.groupby(by=["股票代码", "日期"]).agg(["mean", "max", "min"])
3.4. 定制分组的聚合方式
更进一步,我们还可以针对不同的列采用不同的聚合方式。
比如,对开盘价汇总最大值和平均值,对收盘价汇总最小值和平均值:
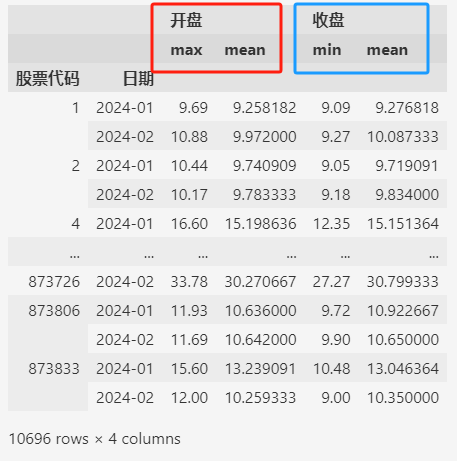
data.groupby(by=["股票代码", "日期"]).agg(
{
"开盘": ["max", "mean"],
"收盘": ["min", "mean"],
}
)
3.5. 聚合后重置索引
从上面聚合后数据的截图中,可以发现,聚合之后,分组用的列(比如 ["股票代码", "日期"])变为索引。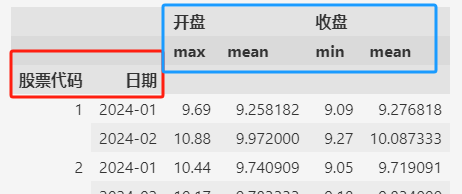
如上所示,聚合之后返回的DataFrame,红色框内的是索引(index),蓝色框内的是列(columns)。
如果,我们希望分组聚合统计之后,分组的列(比如 ["股票代码", "日期"])仍然作为DataFrame的列,
可以在groupby分组时使用as_index=False参数。
data.groupby(by=["股票代码", "日期"], as_index=False).agg(
{
"开盘": ["max", "mean"],
"收盘": ["min", "mean"],
}
)
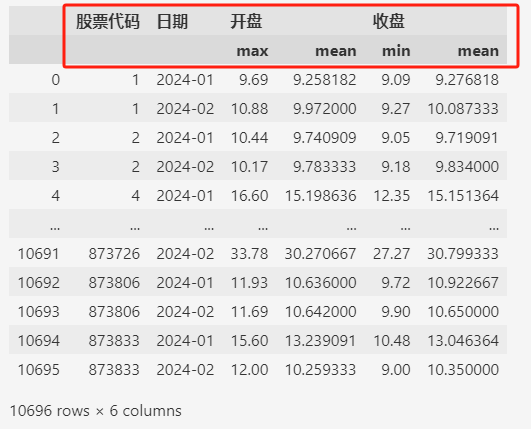
这样的话,分组的列(比如 ["股票代码", "日期"])就不会成为索引。
4. 总结
总的来说,groupby 函数是 pandas 库中一个非常常用的工具,它大大简化了数据处理和分析的过程,
使得用户能够更高效地洞察和理解数据。
分组聚合不再难:Pandas groupby使用指南的更多相关文章
- Pandas系列(九)-分组聚合详解
目录 1. 将对象分割成组 1.1 关闭排序 1.2 选择列 1.3 遍历分组 1.4 选择一个组 2. 聚合 2.1 一次应用多个聚合操作 2.2 对DataFrame列应用不同的聚合操作 3. t ...
- Pandas 分组聚合
# 导入相关库 import numpy as np import pandas as pd 创建数据 index = pd.Index(data=["Tom", "Bo ...
- Pandas | GroupBy 分组
任何分组(groupby)操作都涉及原始对象的以下操作之一: 分割对象 应用一个函数 结合的结果 在许多情况下,我们将数据分成多个集合,并在每个子集上应用一些函数.在应用函数中,可以执行以下操作: 聚 ...
- Pandas时间序列和分组聚合
#时间序列import pandas as pd import numpy as np # 生成一段时间范围 ''' 该函数主要用于生成一个固定频率的时间索引,在调用构造方法时,必须指定start.e ...
- Pandas 分组聚合 :分组、分组对象操作
1.概述 1.1 group语法 df.groupby(self, by=None, axis=0, level=None, as_index: bool=True, sort: bool=True, ...
- Atitit 数据存储的分组聚合 groupby的实现attilax总结
Atitit 数据存储的分组聚合 groupby的实现attilax总结 1. 聚合操作1 1.1. a.标量聚合 流聚合1 1.2. b.哈希聚合2 1.3. 所有的最优计划的选择都是基于现有统计 ...
- python pandas groupby
转自 : https://blog.csdn.net/Leonis_v/article/details/51832916 pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对 ...
- DataAnalysis-Pandas分组聚合
title: Pandas分组聚合 tags: 数据分析 python categories: DataAnalysis toc: true date: 2020-02-10 16:28:49 Des ...
- 数据分析04-pandas(apply函数、排序、数据合、分组聚合、透视表、交叉表及项目分析)
数据分析-04 排序 按标签(行)排序 按标签(列)排序 按某列值排序 数据合并 concat merge & join 分组聚合 分组 聚合 透视表与交叉表 透视表 交叉表 项目:分析影响学 ...
- crm使用FetchXml分组聚合查询
/* 创建者:菜刀居士的博客 * 创建日期:2014年07月09号 */ namespace Net.CRM.FetchXml { using System; using Micr ...
随机推荐
- MySQL 之高级命令(精简笔记)
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RD ...
- Linux 系统Apache配置SSL证书
在Centos7系列系统下,配置Apache服务器,给服务器增加SSL证书功能,让页面访问是不再提示不安全,具体操作流程如下. 1.第一步首先需要安装mod_ssl模块,执行yum install - ...
- Libevent [补档-2023-08-29]
libevent的使用 8-1 安装 自己百度一下,安装它不是特别难,加油!!! 8-2 libevent介绍 它是一个开源库,用于处理网络和定时器等等事件.它提供了跨平台的API,能够在不同 ...
- Windows系统phpstudy+PbootCMS搭建网站记录
环境 Windows 10 phpstudy v8.1 下载地址:https://www.xp.cn/download.html PbootCMS v3.2.4 下载地址:htt ...
- PyTorch中实现Transformer模型
前言 关于Transformer原理与论文的介绍:详细了解Transformer:Attention Is All You Need 对于论文给出的模型架构,使用 PyTorch 分别实现各个部分. ...
- docker容器-乌班图安装vim
apt-get update && apt-get install -y vim
- DBSAT脚本快速收集方法
DBSAT是Oracle官方提供的脚本,用于数据库的安全评估检查,用户可以放心下载使用. 下载链接具体参见MOS: Oracle Database Security Assessment Tool ( ...
- go中的 位预算,反码、补码、原码
https://baike.baidu.com/item/%E4%BD%8D%E8%BF%90%E7%AE%97/6888804 首先关于"位运算",看下百度百科就行了. 总结:在 ...
- .NET Core开发实战(第16课:选项数据热更新:让服务感知配置的变化)--学习笔记
16 | 选项数据热更新:让服务感知配置的变化 选项框架还有两个关键类型: 1.IOptionsMonitor 2.IOptionsSnapshot 场景: 1.范围作用域类型使用 IOptinsSn ...
- Windows-Xshell对多个终端同时执行命令(发送命令到多个会话)
方法1:使用查看中的撰(zhuàn)写栏 (1).查看→撰写→撰写栏. (2).底部可以看到"撰写栏",选择全部会话. (3).在撰写栏输入命令,回车后就会发送到所有会话窗口. 方 ...