Llama2-Chinese项目:4-量化模型
一.量化模型调用方式
下面是一个调用FlagAlpha/Llama2-Chinese-13b-Chat[1]的4bit压缩版本FlagAlpha/Llama2-Chinese-13b-Chat-4bit[2]的例子:
from transformers import AutoTokenizer
from auto_gptq import AutoGPTQForCausalLM
model = AutoGPTQForCausalLM.from_quantized('FlagAlpha/Llama2-Chinese-13b-Chat-4bit', device="cuda:0")
tokenizer = AutoTokenizer.from_pretrained('FlagAlpha/Llama2-Chinese-13b-Chat-4bit',use_fast=False)
input_ids = tokenizer(['<s>Human: 怎么登上火星\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
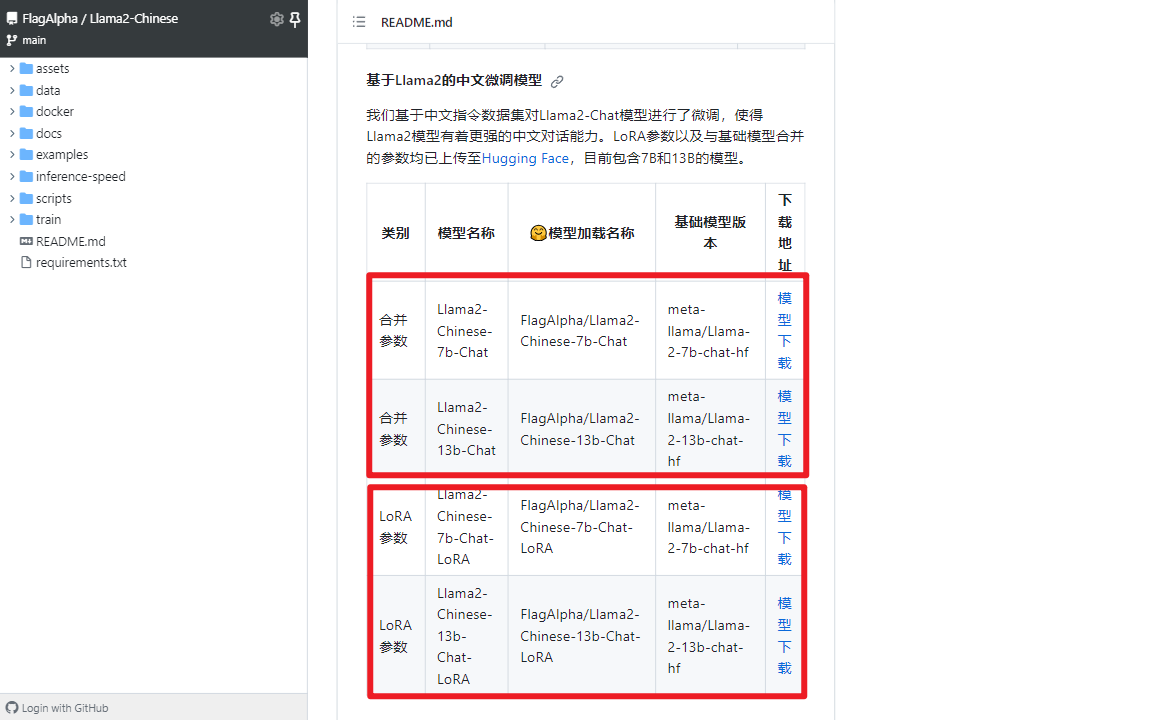
这里面有个问题就是由Llama2-Chinese-13b-Chat如何得到Llama2-Chinese-13b-Chat-4bit?这涉及另外一个AutoGPTQ库(一个基于GPTQ算法,简单易用且拥有用户友好型接口的大语言模型量化工具包)[3]。先梳理下思路,由于meta-llama/Llama-2-13b-chat-hf对中文支持较差,所以采用中文指令集在此基础上进行LoRA微调得到了FlagAlpha/Llama2-Chinese-13b-Chat-LoRA,而FlagAlpha/Llama2-Chinese-13b-Chat=FlagAlpha/Llama2-Chinese-13b-Chat-LoRA+meta-llama/Llama-2-13b-chat-hf,即将两者参数合并后的版本。FlagAlpha/Llama2-Chinese-13b-Chat-4bit就是对FlagAlpha/Llama2-Chinese-13b-Chat进行4bit量化后的版本。总结起来就是如何合并,如何量化这2个问题。官方提供的一些合并参数后的模型[4],如下所示:
二.如何合并LoRA Model和Base Model
网上合并LoRA参数和原始模型的脚本很多,参考文献[6]亲测可用。合并后的模型格式包括pth和huggingface两种。如下所示:
1.LoRA Model文件列表
对于LLama2-7B-hf进行LoRA微调生成文件如下所示:
adapter_config.json
adapter_model.bin
optimizer.pt
README.md
rng_state.pth
scheduler.pt
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
trainer_state.json
training_args.bin
2.Base Model文件列表
LLama2-7B-hf文件列表,如下所示:
config.json
generation_config.json
gitattributes.txt
LICENSE.txt
model-00001-of-00002.safetensors
model-00002-of-00002.safetensors
model.safetensors.index.json
pytorch_model-00001-of-00002.bin
pytorch_model-00002-of-00002.bin
pytorch_model.bin.index.json
README.md
Responsible-Use-Guide.pdf
special_tokens_map.json
tokenizer.json
tokenizer.model
tokenizer_config.json
USE_POLICY.md
3.合并后huggingface文件列表
合并LoRA Model和Base Model后,生成huggingface格式文件列表,如下所示:
config.json
generation_config.json
pytorch_model-00001-of-00007.bin
pytorch_model-00002-of-00007.bin
pytorch_model-00003-of-00007.bin
pytorch_model-00004-of-00007.bin
pytorch_model-00005-of-00007.bin
pytorch_model-00006-of-00007.bin
pytorch_model-00007-of-00007.bin
pytorch_model.bin.index.json
special_tokens_map.json
tokenizer.model
tokenizer_config.json
4.合并后pth文件列表
合并LoRA Model和Base Model后,生成pth格式文件列表,如下所示:
consolidated.00.pth
params.json
special_tokens_map.json
tokenizer.model
tokenizer_config.json
5.合并脚本[6]思路
以合并后生成huggingface模型格式为例,介绍合并脚本的思路,如下所示:
# 步骤1:加载base model
base_model = LlamaForCausalLM.from_pretrained(
base_model_path, # 基础模型路径
load_in_8bit=False, # 加载8位
torch_dtype=torch.float16, # float16
device_map={"": "cpu"}, # cpu
)
# 步骤2:遍历LoRA模型
for lora_index, lora_model_path in enumerate(lora_model_paths):
# 步骤3:根据base model和lora model来初始化PEFT模型
lora_model = PeftModel.from_pretrained(
base_model, # 基础模型
lora_model_path, # LoRA模型路径
device_map={"": "cpu"}, # cpu
torch_dtype=torch.float16, # float16
)
# 步骤4:将lora model和base model合并为一个独立的model
base_model = lora_model.merge_and_unload()
......
# 步骤5:保存tokenizer
tokenizer.save_pretrained(output_dir)
# 步骤6:保存合并后的独立model
LlamaForCausalLM.save_pretrained(base_model, output_dir, save_function=torch.save, max_shard_size="2GB")
合并LoRA Model和Base Model过程中输出日志可参考huggingface[7]和pth[8]。
三.如何量化4bit模型
如果得到了一个训练好的模型,比如LLama2-7B,如何得到LLama2-7B-4bit呢?因为模型参数越来越多,多参数模型的量化还是会比少参数模型的非量化效果要好。量化的方案非常的多[9][12],比如AutoGPTQ、GPTQ-for-LLaMa、exllama、llama.cpp等。下面重点介绍下AutoGPTQ的基础实践过程[10],AutoGPTQ进阶教程参考文献[11]。
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig # 量化配置
from transformers import AutoTokenizer
# 第1部分:量化一个预训练模型
pretrained_model_name = r"L:/20230713_HuggingFaceModel/20230903_Llama2/Llama-2-7b-hf" # 预训练模型路径
quantize_config = BaseQuantizeConfig(bits=4, group_size=128) # 量化配置,bits表示量化后的位数,group_size表示分组大小
model = AutoGPTQForCausalLM.from_pretrained(pretrained_model_name, quantize_config) # 加载预训练模型
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name) # 加载tokenizer
examples = [ # 量化样本
tokenizer(
"auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."
)
]
# 翻译:准备examples(一个只有两个键'input_ids'和'attention_mask'的字典列表)来指导量化。这里只使用一个文本来简化代码,但是应该注意,使用的examples越多,量化后的模型就越好(很可能)。
model.quantize(examples) # 执行量化操作,examples提供量化过程所需的示例数据
quantized_model_dir = "./llama2_quantize_AutoGPTQ" # 保存量化后的模型
model.save_quantized(quantized_model_dir) # 保存量化后的模型
# 第2部分:加载量化模型和推理
from transformers import TextGenerationPipeline # 生成文本
device = "cuda:0"
model = AutoGPTQForCausalLM.from_quantized(quantized_model_dir, device=device) # 加载量化模型
pipeline = TextGenerationPipeline(model=model, tokenizer=tokenizer, device=device) # 得到pipeline管道
print(pipeline("auto-gptq is")[0]["generated_text"]) # 生成文本
参考文献:
[1]https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat
[2]https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat-4bit
[3]https://github.com/PanQiWei/AutoGPTQ/blob/main/README_zh.md
[4]https://github.com/FlagAlpha/Llama2-Chinese#基于Llama2的中文微调模型
[5]CPU中合并权重(合并思路仅供参考):https://github.com/yangjianxin1/Firefly/blob/master/script/merge_lora.py
[6]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora.py
[7]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora_log/merge_llama_with_lora_hf_log
[8]https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/merge_llama_with_lora_log/merge_llama_with_lora_pt_log
[9]LLaMa量化部署:https://zhuanlan.zhihu.com/p/641641929
[10]AutoGPTQ基础教程:https://github.com/PanQiWei/AutoGPTQ/blob/main/docs/tutorial/01-Quick-Start.md
[11]AutoGPTQ进阶教程:https://github.com/PanQiWei/AutoGPTQ/blob/main/docs/tutorial/02-Advanced-Model-Loading-and-Best-Practice.md
[12]Inference Experiments with LLaMA v2 7b:https://github.com/djliden/inference-experiments/blob/main/llama2/README.md
[13]llama2_quantize_AutoGPTQ:https://github.com/ai408/nlp-engineering/blob/main/20230916_Llama2-Chinese/tools/llama2_quantize_AutoGPTQ.py
Llama2-Chinese项目:4-量化模型的更多相关文章
- CNN结构演变总结(二)轻量化模型
CNN结构演变总结(一)经典模型 导言: 上一篇介绍了经典模型中的结构演变,介绍了设计原理,作用,效果等.在本文,将对轻量化模型进行总结分析. 轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间 ...
- 使用F#开发量化模型都缺什么?
量化模型多数是基于统计的,因此,统计运算库应该是必备的.在Matlab.R中包含了大量的统计和概率运算,可以说拿来就用,非常方便,相比之下,F#的资源就很少了,这里给大家提供几个链接,可以解决一部分问 ...
- Atitit 项目管理 提升开发效率的项目流程方法模型 哑铃型 橄榄型 直板型
Atitit 项目管理 提升开发效率的项目流程方法模型 哑铃型 橄榄型 直板型 项目主体三个部分 ui界面,中间层,数据库 按照不同的比重可以分为一下三个模型 哑铃型 橄榄型 直板型 哑铃型 开 ...
- Atitit. 如何判断软件工程师 能力模型 程序员能力模型 项目经理能力模型
Atitit. 如何判断软件工程师 能力模型 程序员能力模型 项目经理能力模型 这里能力模型的标准化是对工具的使用为基本 工具(ide,语言,类库,框架,软件) 第一步 ::可使用api 类库 框架 ...
- 轻量化模型之MobileNet系列
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 轻量化模型之SqueezeNet
自 2012 年 AlexNet 以来,卷积神经网络在图像分类.目标检测.语义分割等领域获得广泛应用.随着性能要求越来越高,AlexNet 已经无法满足大家的需求,于是乎各路大牛纷纷提出性能更优越的 ...
- 后盾网lavarel视频项目---lavarel使用模型进行增删改查操作
后盾网lavarel视频项目---lavarel使用模型进行增删改查操作 一.总结 一句话总结: 使用模型操作常用方法 查一条:$model=Tag::find($id); 删一条:Tag::dest ...
- 轻量化模型:MobileNet v2
MobileNet v2 论文链接:https://arxiv.org/abs/1801.04381 MobileNet v2是对MobileNet v1的改进,也是一个轻量化模型. 关于Mobile ...
- 轻量化模型训练加速的思考(Pytorch实现)
0. 引子 在训练轻量化模型时,经常发生的情况就是,明明 GPU 很闲,可速度就是上不去,用了多张卡并行也没有太大改善. 如果什么优化都不做,仅仅是使用nn.DataParallel这个模块,那么实测 ...
- 轻量化模型系列--GhostNet:廉价操作生成更多特征
前言 由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络 (CNN) 很困难.特征图中的冗余是那些成功的 CNN 的一个重要特征,但在神经架构设计中很少被研究. 论文提出了一种新颖的 Gh ...
随机推荐
- Go应用性能优化的8个最佳实践,快速提升资源利用效率!
作者|Ifedayo Adesiyan 翻译|Seal软件 链接|https://earthly.dev/blog/optimize-golang-for-kubernetes/ 优化服务器负载对于确 ...
- FPGA加速技术:如何提高系统的可编程性和灵活性
目录 <23. FPGA加速技术:如何提高系统的可编程性和灵活性> 一.引言 随着人工智能.物联网等新技术的快速发展,对计算资源和处理能力的需求不断增加.为了加速计算流程和提高系统的性能, ...
- MySQL数据库的集群方案
读写分离结构(主从) 读多写少,也就是对数据库读取数据的压力比较大. 其中一个是主库,负责写入数据,成为写库:其他都是从库,负责读取数据,成为读库. 对我们的要求: 读库和写库的数据一致: 写数据必须 ...
- 如何给Github上的开源项目提交PR?
前言 对于一个热爱开源的程序员而言,学会给GitHub上的开源项目提交PR这是迈出开源的第一步.今天我们就来说说如何向GitHub的开源项目提交PR,当然你提交的PR可以是一个项目的需求迭代.也可以是 ...
- 基于ClickHouse解决活动海量数据问题
1.背景 魔笛活动平台要记录每个活动的用户行为数据,帮助客服.运营.产品.研发等快速处理客诉.解决线上问题并进行相关数据分析和报警.可以预见到需要存储和分析海量数据,预估至少几十亿甚至上百亿的数据量, ...
- 利用Anaconda3安装tensorflow/keras,并迁移虚拟环境至不能上网的电脑
利用Anaconda3安装tensorflow/keras,并迁移虚拟环境至不能上网的电脑 下面记录下利用Anaconda安装tensorflow和keras,前前后后也踩了不少坑.并分别在windo ...
- debezium同步postgresql数据至kafka笔记
实验环境 全部部署于本地虚拟机 debezium docker部署 postgresql.kafka本机部署 1 postgresql 1.1 配置 设置postgres密码为123 仿照exampl ...
- QPushButton按钮的使用
1 import sys 2 from PyQt5.QtCore import * 3 from PyQt5.QtGui import * 4 from PyQt5.QtWidgets import ...
- vxe-table中文文档
https://xuliangzhan_admin.gitee.io/vxe-table/#/table/grid/fullEdit
- [db2]缓冲池管理
简介 缓冲池指的是从硬盘读取表和索引数据时,数据库管理器分配的用于高速缓存这些表和索引数据的内存区域.每个数据库都必须具有至少一个缓冲池,创建数据库时会自动创建一个名为IBMDEFAULTBP的缓冲池 ...