3 分钟了解 NVIDIA 新出的 H200
英伟达在 2023 年全球超算大会上发布了备受瞩目的新一代 AI 芯片——H200 Tensor Core GPU。相较于上一代产品 H100,H200 在性能上实现了近一倍的提升,内存容量翻倍,带宽也显著增加。
据英伟达称,H200 被冠以当世之最的芯片的称号。不过,根据发布的信息来看,H200 Tensor Core GPU 并没有让人感到意外。在 2023 年 8 月 30 日,英伟达就发布了搭载 HBM3e 技术的 GH200 Grace Hopper 的消息,而 HBM3e 也是 H200 芯片的升级重点。
HBM3E——H200升级重点
NVIDIA H200 是首款提供 HBM3e 的 GPU,HBM3e 是更快、更大的内存,可加速生成式 AI 和大型语言模型,同时推进 HPC 工作负载的科学计算。借助 HBM3e,NVIDIA H200 的显存带宽可以达到 4.8TB/秒,并提供 141GB 的内存。相较于 H100,H200 在吞吐量、能效比和内存带宽等方面均有所提升。

HBM3E 到底是什么技术,让 H200 有了如此大的提升?接下来我们就来详细了解下 HBM3E。
HBM3E(High Bandwidth Memory 3E)是最新一代的高带宽内存技术,它是 HBM(High Bandwidth Memory)系列的进一步改进和升级版本。HBM3E 在速度和容量方面都有显著提升,旨在满足处理大规模数据和高性能计算的需求。
相较于 HBM,HBM3E 内存具有更快的数据传输速度,可实现更高的带宽。同时,HBM3E 可以提供更高密度的内存芯片,从而使系统能够拥有更大的内存容量。这非常有利于大型数据集和复杂计算任务。
在架构上,HBM3E 继续采用了堆叠式设计,将多个存储层叠加在一起,以实现更高的带宽和更低的能耗。相较于传统的内存技术,HBM3E 在给定带宽的情况下能够提供更高的能效。HBM3E 内存芯片的堆叠层数更多,从而实现更高的存储密度。这使得在相对较小的物理空间内实现更大的内存容量成为可能。
HBM3E 的引入旨在满足处理大规模数据和高性能计算的需求,尤其适用于人工智能、机器学习、深度学习等领域。它提供了更高的带宽、更大的容量和更高的能效,能够加速数据处理和计算任务,推动各种应用的发展。
HBM3E 不仅满足了用于 AI 的存储器所需的速度规格,而且在发热控制和客户使用便利性等各个方面达到了全球最高水平。在速度方面,它能够每秒处理 1.15TB 的数据,相当于在 1 秒内可以处理 230 部全高清(FHD)级别的电影(每部 5GB)。通过使用即将推出的 HBM3E 内存,NVIDIA 将能够提供在内存带宽受限的工作负载中具有更好实际性能的加速器,同时也能够处理更大的工作负载。在2023 年 8 月份,我们就看到 NVIDIA 计划发布配备 HBM3 的 Grace Hopper GH200 超级芯片版本。这次 NVIDIA 宣布的 H200,其实就是配备 HBM3E 内存的独立 H100 加速器的更新版本。
H200 VS H100
接下来我们就来具体看看,相较于 H100,H200 的性能提升到底体现在哪些地方。
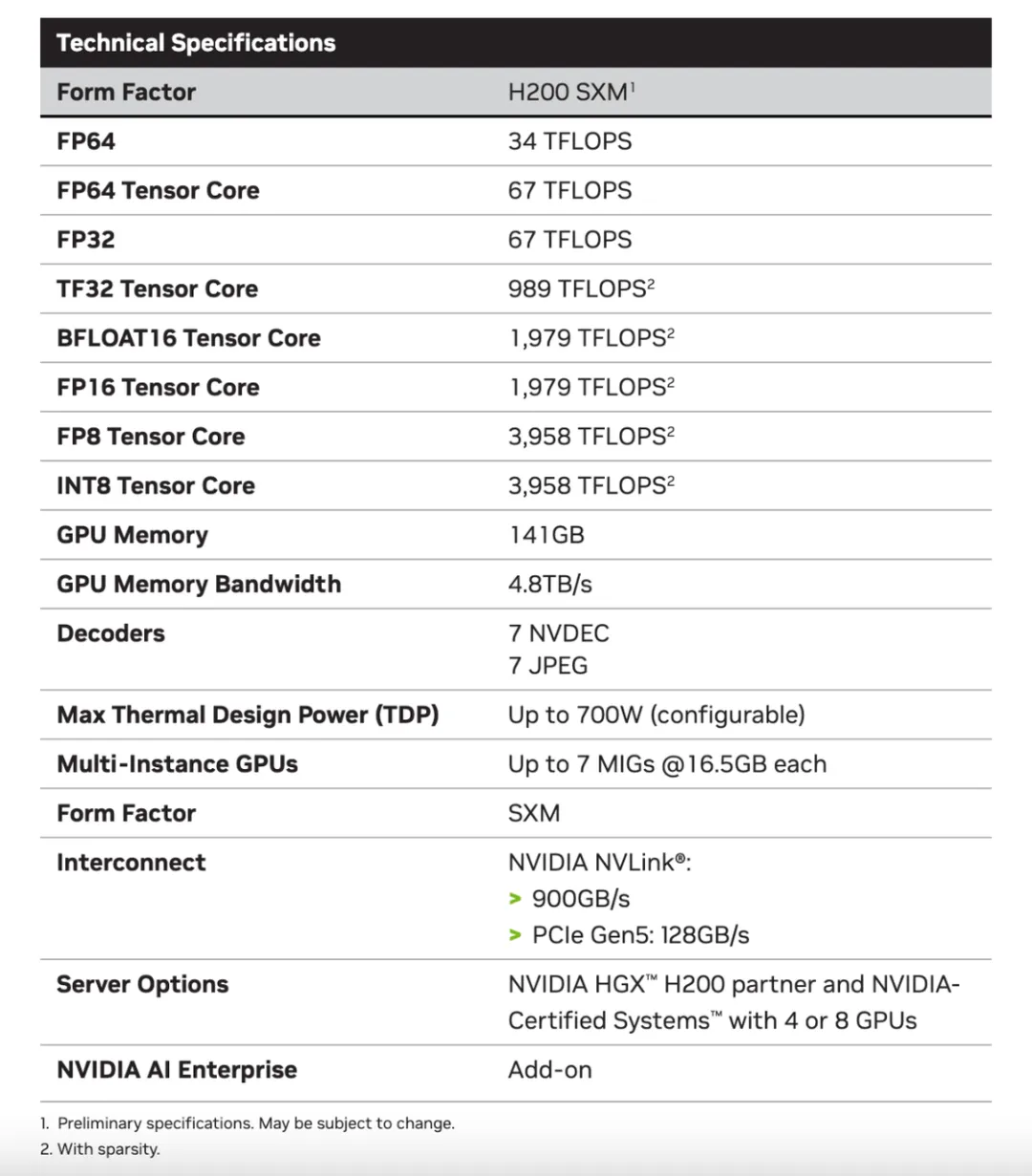
△ H200的相关参数
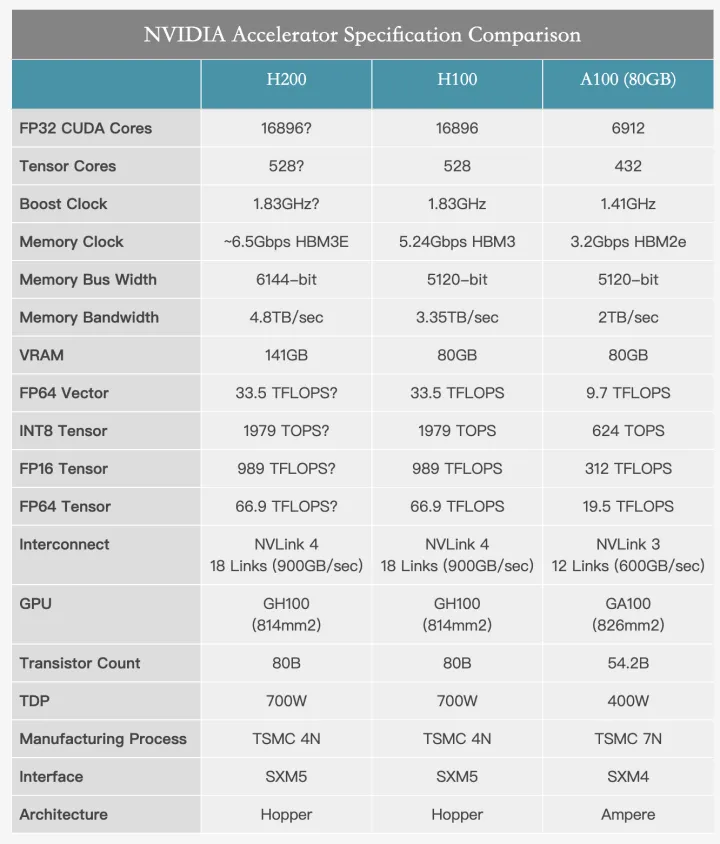
性能计算
H200 具备超过 460 万亿次的浮点运算能力,可支持大规模的AI模型训练和复杂计算任务。HGX H200采用了NVIDIA NVLink 和 NVSwitch 高速互连技术,为各种应用工作负载提供最高性能,包括对超过 1750 亿个参数的最大模型进行的 LLM 训练和推理。借助 HBM3e 技术的支持,H200 能够显著提升性能。
在 HBM3e 的加持下,H200 能够将 Llama-70B 推理性能提升近两倍,并将运行 GPT3-175B 模型的性能提高了60%。对于具有 700 亿参数的 Llama 2 大模型,H200 的推理速度比 H100 快一倍,并且推理能耗降低了一半。此外,H200 在 Llama 2 和 GPT-3.5 大模型上的输出速度分别是 H100 的 1.9 倍和 1.6 倍。
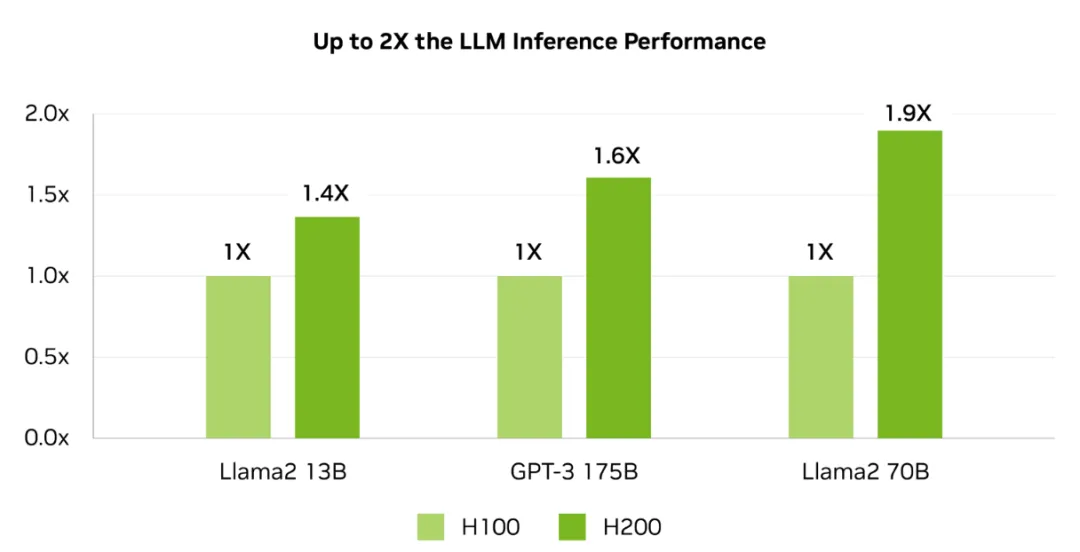
高速内存
NVIDIA 的 H200 芯片支持高达 48GB 的 GDDR6X 内存,其内存带宽可达 936GB/s,有效提高了数据传输速度并降低了延迟。同时,借助 HBM3e技术,NVIDIA H200 每秒可以提供 4.8TB 的内存容量和 141GB的内存带宽。对比 H100 的 SXM 版本,显存从 80GB 提升 76%,带宽从每秒 3.35TB 提升了 43%。
内存带宽对于高性能计算(HPC)应用程序非常重要,因为它可以实现更快的数据传输,减少复杂处理过程中的瓶颈。对于模拟、科学研究和人工智能等内存密集型HPC应用,H200的更高内存带宽可以确保高效地访问和操作数据。与传统的CPU相比,使用 H200 芯片可以将获取结果的时间加速多达 110 倍。
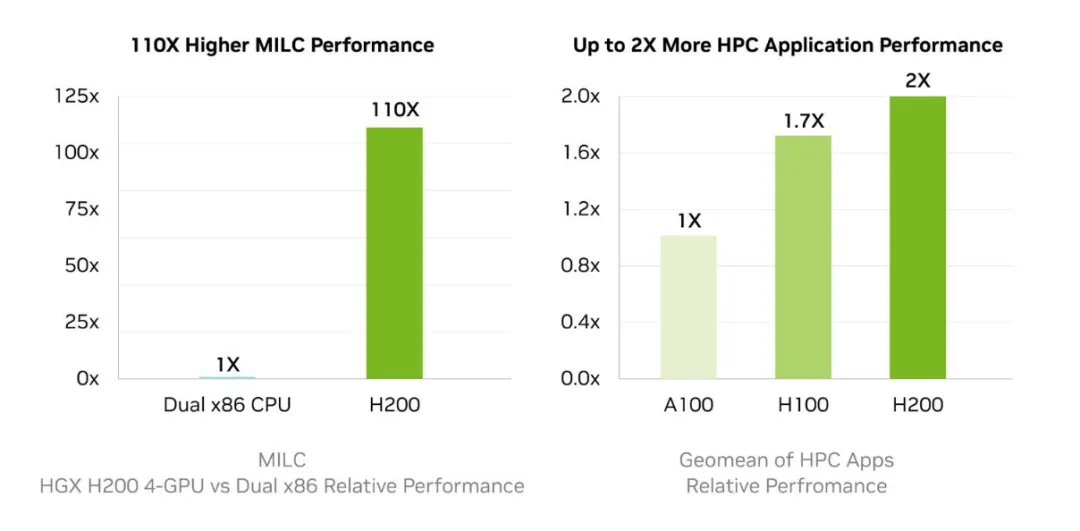
硬件加速
H200 是一款内置了强大的 AI 加速器的芯片,它能显著提高神经网络的训练和推理速度。该芯片采用了先进的 7 纳米制程工艺,拥有超过 1000 亿个晶体管,整个芯片的面积达到 1526 平方毫米。
NVIDIA H200 芯片将应用于具有四路和八路配置的 NVIDIA HGX H200 服务器主板,这些主板与 HGX H100 系统的硬件和软件兼容。H200 芯片还可用于采用 HBM3e 内存的 NVIDIA GH200 Grace Hopper 超级芯片。八路配置的 HGX H200 主板提供超过 32 petaflops 的 FP8 深度学习计算能力和 1.1TB 的聚合高带宽内存。

能源效率
H200 芯片采用先进的散热技术,以确保在高性能计算的同时保持较低的功耗。这使得 H200 在功耗配置与 H100 相当。
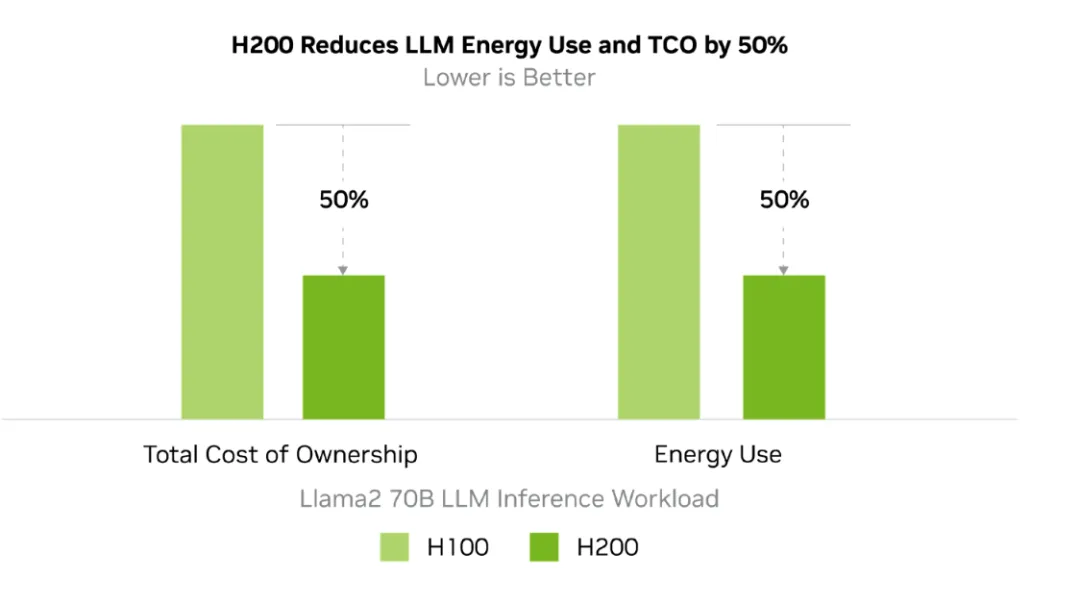
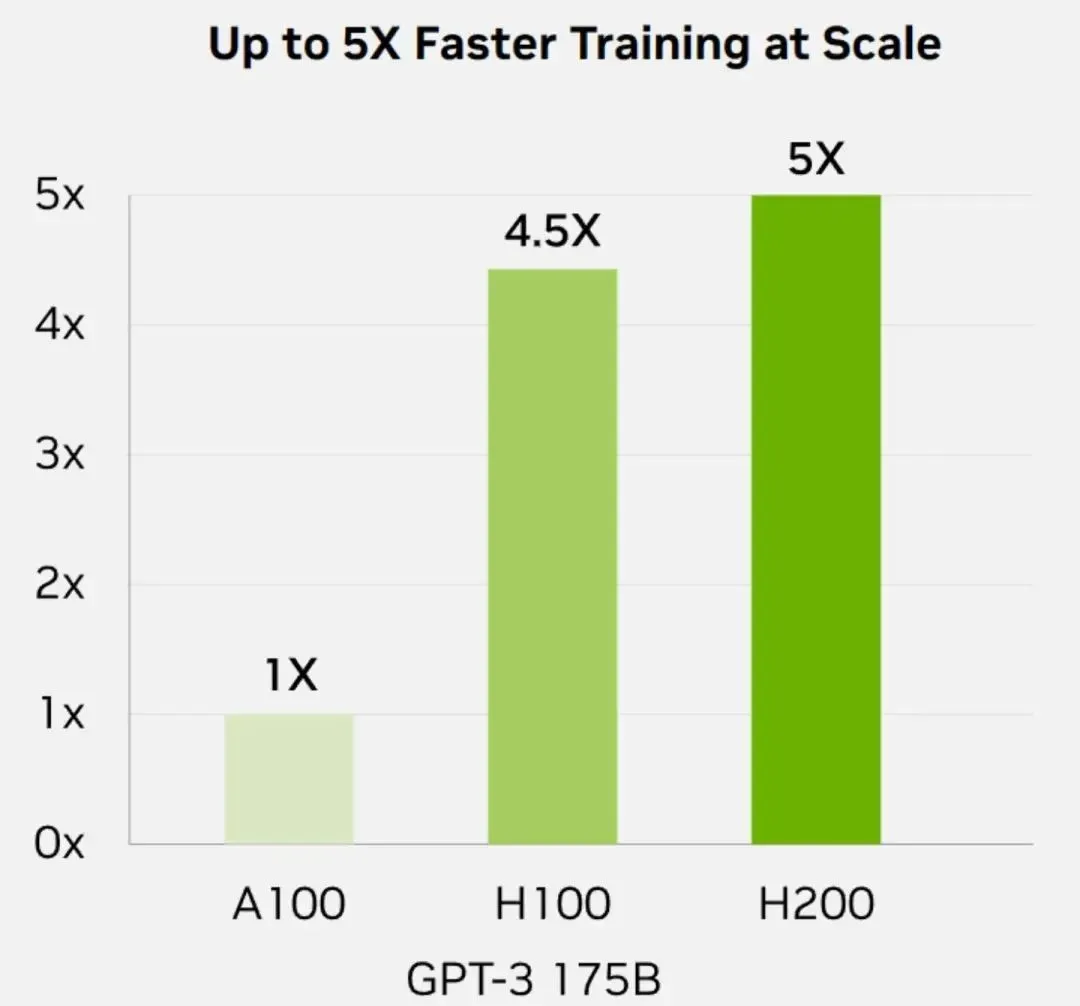
训练能力
在之前用于评估 AI 芯片性能的一个重要指标——训练能力方面,H200 并没有明显的提升。根据英伟达提供的数据,对于 GPT-3 175B 大模型的训练任务而言,H200 只比 H100 强 10%。
H200 和 H100 芯片都基于英伟达的 Hopper 架构开发,因此这两款芯片是相互兼容的。对于已经使用 H100 的企业来说,无需进行任何调整,可以直接进行更换。此外,就峰值算力而言,H100 和 H200 实际上是相同的,它们的 FP64 矢量计算能力为 33.5TFlops,FP64 张量计算能力为 66.9TFlops,提升的参数主要是显存容量和内存带宽。
聊了这么多,相信大家对英伟达新推出的 H200 有了一定了解。近期,又拍云与厚德云联合推出了全新的 GPU 产品,新用户注册即可免费体验 RTX4090 GPU。您可以通过一键搭建 CUDA、Stable Diffusion 等开发环境,轻松快捷地体验强大的 GPU 算力,有兴趣的同学赶紧来体验下吧。
3 分钟了解 NVIDIA 新出的 H200的更多相关文章
- anki_vector SDK源码解析(教程)
一:最近anki vector robot开放了Python SDK,我听到的第一时间就赶快上网查了查,先抛几个官网重要链接吧: Python编程API手册及环境搭建等: https://sdk-re ...
- 回击MLAA:NVIDIA FXAA抗锯齿性能实測、画质对照
PC游戏玩家肯定会对各式各样的AA抗锯齿技术很熟悉,而今天本文的主角就是NVIDIA今年才推出的新型抗锯齿技术"FXAA". FXAA在某种程度上有些类似于AMD之前宣传的MLAA ...
- caffe+NVIDIA安装+CUDA-7.5+ubuntu14.04(显卡GTX1080)
首先强调,我们实验室的机器是3.3w的机器,老板专门买来给我们搞深度学习,其中显卡是NVIDIA GeForce GTX1080(最近新出的,装了两块),cpu是intel i7处理器3.3Ghz, ...
- Ubuntu18.04LTS安装Nvidia显卡
笔者在为Ubuntu18.04LTS安装Nvidia显卡驱动之前,早就听说了一系列关于由于Nvidia驱动引起的疑难杂症.选择高质量的教程并保持足够的耐心,就能解 决这些问题.很重要的一点,不要怕把电 ...
- 安装Ubuntu 16.04双系统详解(Nvidia显卡)
Ubuntu16.04双系统安装 一.准备工作 设备:惠普台式机,i5-7400.8G内存.1T机械硬盘.NVIDIA GTX1050显卡.预装系统:Win10. 1.下载ubuntu镜像文件,本人使 ...
- nvidia tx1使用记录--基本环境搭建
前言 之前有专门写过一篇nvidia tk1使用记录--基本环境搭建,本以为自己有过tk1的经验后,在tx1上搭建和它一样的环境会轻车熟路,结果却是在nvidia tx1上花的时间居然比tk1还多.我 ...
- 显示器驱动程序 NVIDIA Windows Kernel Mode Driver Version 已停止响应 并且己成功恢复 解决方法
原文:http://news.160.com/?p=1890 在玩游戏中 经常 出现显示器驱动程序 NVIDIA Windows Kernel Mode Driver Version 已停止响应 并且 ...
- ubuntu 16.04 +anaconda3.6 +Nvidia DRIVER 390.77 +CUDA9.0 +cudnn7.0.4+tensorflow1.5.0+neural-style
这是我第一个人工智能实验.虽然原理不是很懂,但是觉得深度学习真的很有趣.教程如下. Table of Contents 配置 时间轴 前期准备工作 anaconda3 安装 bug 1:conda:未 ...
- ubuntu安装nvidia驱动以及cuda教程
最近尝试在ubuntu中安装nvidia的显卡驱动以及cuda.花了近三天时间,真的如网上所说错误百出,期间甚至重装了一次ubuntu系统,搞到怀疑人生,整个都是泪- -.最终经过百般“磨难”总算安装 ...
- nvidia jetson tx2 刷机遇到的问题解决
一.主要信息 使用的开发板:nvidia jetson tx2(内存8g有wifi的版本) 使用的JetPack版本: 4.2.2 二.遇到的问题及解决 1. 刷好jetson os 后,开发板一直在 ...
随机推荐
- 模拟QQ登陆
public class QQLogin { public static void main(String[] args) { int id1 = 123456; String pwd1 = &quo ...
- Vulkan学习笔记之开发环境搭建
一.概述 最近因为工作需要开始学习Vulkan的相关知识,作为初学者,发现相对较好的学习资料莫过于vulkan-tutorial,在自己学习Vulkan的过程中,决定将自己的理解记录下来,一是为了加深 ...
- 别再傻傻地用 ifconfig 查地址了!这条命令足以让你摘掉小白工程师的帽子
大家好,我是民工哥. 众所周知,在 Linux 系统中,ip 和 ifconfig 这个两命令的功能十分相似,ifconfig 是 net-tools 中已被弃用的一个命令,很多年前就已经没有维护了. ...
- 在终端输入EOF
在终端输入EOF 问题 如下是一个计算校验和的程序,其中使用了while循环,需要在标准输入中读取到EOF才能跳出循环. #include <stdio.h> int main(){ in ...
- 解决QObject::moveToThread: Current thread (0x56059f9b0f70) is not the object's t
对 opencv 降级 pip install opencv-python==4.1.2.30
- windows环境下如何优雅搭建ftp服务?
目录 0. 前言 1.ftp简介 2.下载Apache FTPServer 3.下载并解压压缩包 4.修改配置文件 4.1 修改users.properties配置文件 4.2 修改ftpd-typi ...
- Golang代码测试:一点到面用测试驱动开发
摘要:TDD(Test Driven Development),测试驱动开发.期望局部最优到全局最优,这个是一种非常不错的好习惯. 了解Golang的测试之前,我们先了解一下go语言自带的测试工具. ...
- 既快又稳还方便,火山引擎 VeDI 的这款产品解了分析师的愁
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 "数据加载速度变快了."这是小吴在使用 DataWind 后的第一感受. 目前就职于国内一家手 ...
- Solon2 之基础:四、应用启动过程与完整生命周期
串行的处理过程(含六个事件扩展点 + 两个函数扩展点),代码直接.没有什么模式.易明 提醒: 启动过程完成后,项目才能正常运行(启动过程中,不能把线程卡死了) AppBeanLoadEndEvent ...
- Nginx log 日志文件较大,按日期生成 实现日志的切割
Nginx日志不处理的话,会一直追加,文件会变得很大,所以理想做法是按天对 Nginx日志进行分割 方法1:给日志文件名加上日期 推荐 log_format access-upstream '$tim ...