基于Flume做FTP文件实时同步的windows服务。
需求:做一个windows服务,实现从ftp服务器实时下载或者更新文件到本地磁盘。
功能挺简单的。直接写个ftp工具类用定时器跑就能搞定,那我为什么不用呢?
别问,问就是我无聊啊,然后研究一下Flume打发时间。哈哈~
一、Flume部分
Source组件和Sink组件用的都是第三方。
source组件:https://github.com/keedio/flume-ftp-source
Sink组件用的谁的目前已经找不到了,网上搜到了一个升级版的。
File sink组件:https://github.com/huyanping/flume-sinks-safe-roll-file-sink
因为一些个性化的需求,所以我对他们源代码做了些变动。
2019/02/15: 新增了采集至HDFS的sink.因为flume自带的hdfs sink不支持高可用环境。所以依然对源代码做了些改动
具体修改:
HDFSEventSink.java
public void configurateHA(Context context) {
String nns = Preconditions.checkNotNull(
context.getString("nameNodeServer"), "nameNodeServer is required");
hdfsEnv.set("fs.defaultFS", "hdfs://" + nns);
hdfsEnv.set("dfs.nameservices", nns);
hdfsEnv.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
Map<String, String> servers = context.getSubProperties("server.");
List<String> serverNames = Lists.newArrayListWithExpectedSize(servers.size());
servers.forEach((key, value) -> {
String name = Preconditions.checkNotNull(
key, "server.name is required");
String[] hostAndPort = value.split(":");
Preconditions.checkArgument(2 == hostAndPort.length, "hdfs.server is error.");
hdfsEnv.set(String.format("dfs.namenode.rpc-address.%s.%s", nns, name), value);
serverNames.add(name);
});
hdfsEnv.set(String.format("dfs.ha.namenodes.%s", nns), Joiner.on(",").join(serverNames));
hdfsEnv.set(String.format("dfs.client.failover.proxy.provider.%s", nns),
"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
hdfsEnv.setBoolean("fs.automatic.close", false);
}
Flume伪集群配置
# Describe the sink
a1.sinks.k1.type = com.syher.flume.sink.hdfs.HDFSEventSink
# 目标路径
a1.sinks.k1.hdfs.path = hdfs://bigData:8020/flume-wrapper/pdf-201901301740
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#a1.sinks.k1.hdfs.batchSize = 3000
#a1.sinks.k1.hdfs.rollSize = 1024000000
#a1.sinks.k1.hdfs.rollCount = 0
Flume高可用配置文件
# Describe the sink
a1.sinks.k1.type = com.syher.flume.sink.hdfs.HDFSEventSink
# hdfs服务器是否高可用
a1.sink.k1.hdfs.HA = true
# 目标路径
a1.sinks.k1.hdfs.path = hdfs://bigData/flume-wrapper/pdf-201901301805
a1.sinks.k1.hdfs.nameNodeServer = bigData
a1.sink.k1.hdfs.server.nn1 = master:9000
a1.sink.k1.hdfs.server.nn2 = slave1:9000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#a1.sinks.k1.hdfs.batchSize = 3000
#a1.sinks.k1.hdfs.rollSize = 0
#a1.sinks.k1.hdfs.rollInterval = 60
#a1.sinks.k1.hdfs.rollCount = 0
具体代码参考:https://github.com/rxiu/study-on-road/tree/master/trickle-flume
Ftp-Source组件的关键技术是Apache FtpClient,而TailDir-sink则用的RandomAccessFile。
Junit测试类我已经写好了,如果不想安装服务又有兴趣了解的朋友,可以自己改下配置跑一下看看。
二、JSW服务部分
用的java service wrapper把java程序做成了windows服务。
JSW工具包地址:https://pan.baidu.com/s/1Mg483tA0USYqFZ_bNV30tg 提取码:ejda
解压后在conf目录可以看到两个配置文件。一个是flume的,一个是jsw的。
bin目录里面是一些装卸启停的批命令。
lib目录里面有项目运行依赖的jar包。
lib.d目录没啥用,是我备份了从flume拷出来的一些无用的jar包。可删。
具体的配置和用法可以看压缩包里的使用说明文档。
注意,jsw的logfile的日志级别最好指定ERROR级别的,不然听说、可能会造成内存不足。
三、采集结果
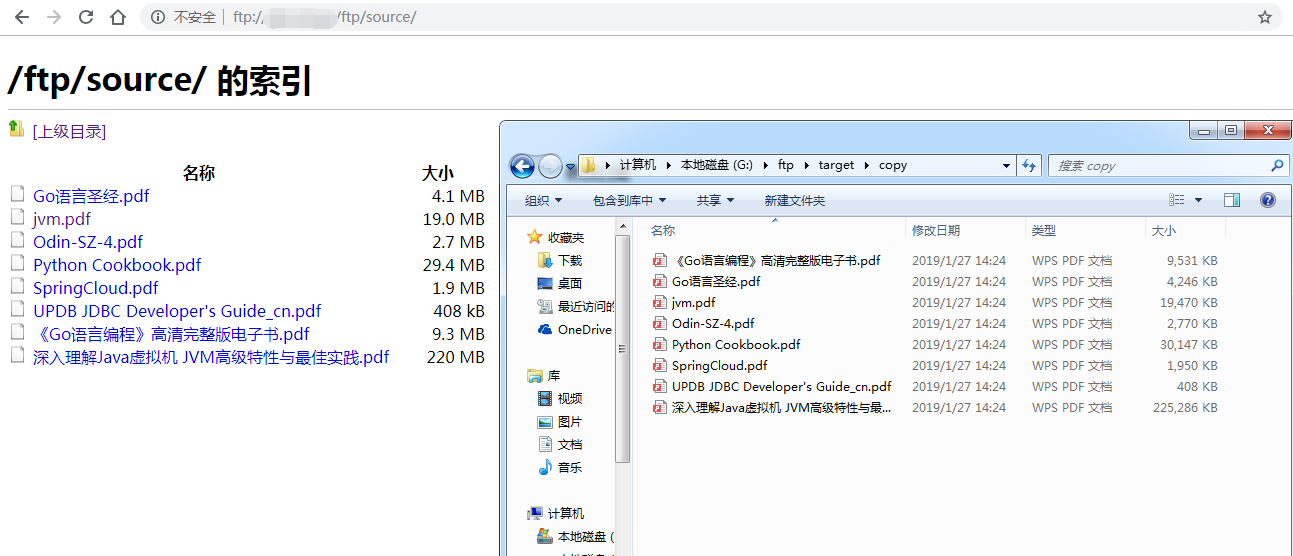
可以看到,文件采集效率还是很稳的。一分钟不到就搞定了。
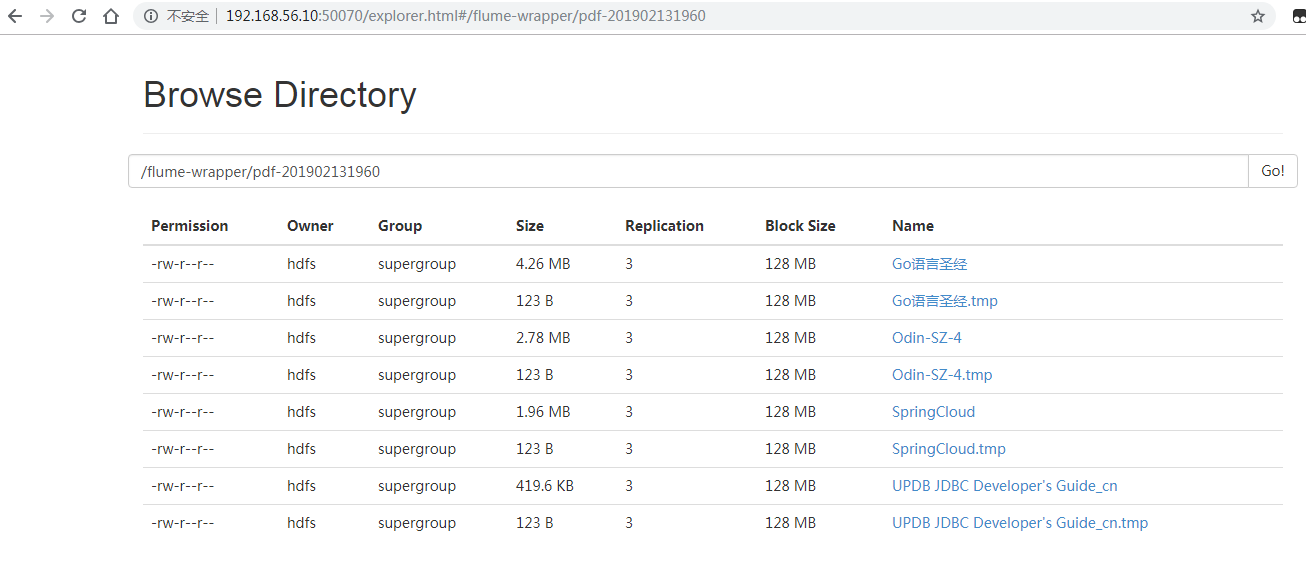
hdfs采集结果:
四、问题记录
hdfs采集时,用junit测试没有问题,用jsw测试一直没动静,也不报错。然后开了远程调试。调试方法:
在wrapper.conf中加入如下代码:
# remote debug
#wrapper.java.additional.1=-Xdebug
#wrapper.java.additional.2=-Xnoagent
#wrapper.java.additional.3=-Djava.compiler=NONE #wrapper.java.additional.4=-Xrunjdwp:transport=dt_socket,server=y,address=5005,suspend=y
远程联调以后,终于有抛异常了
java.lang.NoClassDefFoundError: Could not initialize class org.apache.commons.lang.SystemUtils
找了下lib文件夹,里面确实有这个包,也没冲突。不得已在SystemUtils类里面打了个断电一步一步调试。最后发现是java.version的问题。
jdk10版本在下面代码的第5行报错了。因为JAVA_VERSION_TRIMMED值是10长度只有两位导致了越界。
private static float getJavaVersionAsFloat() {
if (JAVA_VERSION_TRIMMED == null) {
return 0f;
}
String str = JAVA_VERSION_TRIMMED.substring(0, 3);
if (JAVA_VERSION_TRIMMED.length() >= 5) {
str = str + JAVA_VERSION_TRIMMED.substring(4, 5);
}
try {
return Float.parseFloat(str);
} catch (Exception ex) {
return 0;
}
}
由于之前为了学习jdk10新特性,搞了个jdk8,jdk10双环境,然后换回jdk8的时候是直接改的JAVA_HOME。
所以在dos窗口敲了下java -version 输出的是1.8_xxxxx。
但是不知道为啥java的System.getProperties("java.version")获取的依旧是10。
然后重新检查了JDK的J三个环境变量。
最后发现把PATH中的一个C:\ProgramData\Oracle\Java\javapath;路径去掉就没问题了。
C:\ProgramData\Oracle\Java\javapath;G:\syhenian\oracle_11_21;E:\Program Files\Python36\Scripts\;E:\Program Files\Python36\;%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\;%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;%M2_HOME%\bin;C:\Program Files (x86)\Intel\OpenCL SDK\2.0\bin\x86;C:\Program Files (x86)\Intel\OpenCL SDK\2.0\bin\x64;%CURL_HOME%\bin;E:\Program Files\scala\bin;%SCALA_HOME%\bin;%SCALA_HOME%\jre\bin;E:\Program Files\Python36;C:\Program Files (x86)\Git\cmd;%GRADLE_HOME%\bin;%ANDROID_HOME%\tools;
%ANDROID_HOME%\platform-tools;%ANDROID_HOME%\build-tools\27.0.3;E:\Program Files\7-Zip;F:\Program Files\nodejs\;%HADOOP_HOME%\bin;
总结:common-lang包不知道升级管不管用,反正flume自带的这个包暂时是不支持jdk10的。有需要的可以自己改源码。
基于Flume做FTP文件实时同步的windows服务。的更多相关文章
- rsync+inotify 实现服务器之间目录文件实时同步(转)
软件简介: 1.rsync 与传统的 cp. tar 备份方式相比,rsync 具有安全性高.备份迅速.支持增量备份等优点,通过 rsync 可 以解决对实时性要求不高的数据备份需求,例如定期的备份文 ...
- Centos 6.5 rsync+inotify 两台服务器文件实时同步
rsync和inotify是什么我这里就不在介绍了,有专门的文章介绍这两个工具. 1.两台服务器IP地址分别为: 源服务器:192.168.1.2 目标服务器:192.168.1.3 @todo:从源 ...
- sersync基于rsync+inotify实现数据实时同步
一.环境描述 需求:服务器A与服务器B为主备服务模式,需要保持文件一致性,现采用sersync基于rsync+inotify实现数据实时同步 主服务器A:192.168.1.23 从服务器B:192. ...
- (转)Linux下通过rsync与inotify(异步文件系统事件监控机制)实现文件实时同步
Linux下通过rsync与inotify(异步文件系统事件监控机制)实现文件实时同步原文:http://www.summerspacestation.com/linux%E4%B8%8B%E9%80 ...
- centos文件实时同步inotify+rsync
我的应用场景是重要文件备份 端口:873,备份端打开即可 下载地址:https://rsync.samba.org/ftp/rsync/src/ 服务端和客户端要保持版本一致 网盘链接:https:/ ...
- rsync+inotify-tools文件实时同步
rsync+inotify-tools文件实时同步案例 全量备份 Linux下Rsync+sersync实现数据实时同步完成. 增量备份 纯粹的使用rsync做单向同步时,rsync的守护进程是运行在 ...
- rsync+sersync实现数据文件实时同步
一.简介 sersync是基于Inotify开发的,类似于Inotify-tools的工具: sersync可以记录下被监听目录中发生变化的(包括增加.删除.修改)具体某一个文件或某一个目录的名字: ...
- sersync+rsync实现服务器文件实时同步
sersync+rsync实现服务器文件实时同步 一.为什么要用rsync+sersync架构? 1.sersync是基于inotify开发的,类似于inotify-tools的工具 2.sersyn ...
- inotify用法简介及结合rsync实现主机间的文件实时同步
一.inotify简介 inotify是Linux内核2.6.13 (June 18, 2005)版本新增的一个子系统(API),它提供了一种监控文件系统(基于inode的)事件的机制,可以监控文件系 ...
随机推荐
- 将Socket应用程序从Unix向Windows移植中应注意的几点问题
套接字(socket)当今已成为最流行的网络通信应用程序接口.套接字最初是由加利福尼亚大学Berkeley分校为Unix操作系统开发的网络通信接口,后来它又被移植到DOS与Windows系统,特别是近 ...
- MySQL 笔记整理(20) --幻读是什么,幻读有什么问题?
笔记记录自林晓斌(丁奇)老师的<MySQL实战45讲> (本篇内图片均来自丁奇老师的讲解,如有侵权,请联系我删除) 20) --幻读是什么,幻读有什么问题? 我们先来看看表结构和初始化数据 ...
- C#语言各个版本特性(二)
二.排序Product 1.按名称对产品进行排序,以特定顺序显示一个列表的最简单方式就是先将列表排序,再遍历并显示其中的项. C#1.1 使用IComparer对ArrayList进行排序 produ ...
- Sql语法高级应用之四:使用视图实现多表联合数据明细
之前章节我们讲到:如果某个表的数据是多个表的联合,并且存在列与列的合并组成新列,用视图是最好的方案. 下面我分享两个个真实的SQL语句案例 USE Wot_Inventory GO FROM sys. ...
- JS判断时特殊值与boolean类型的转换
扒开JQuery以及其他一些JS框架源码,常常能看到下面这样的判断,写惯了C#高级语言语法的我,一直以来没能系统的理解透这段代码. var test; //do something... if(tes ...
- JAVA基本数据类型所占字节数是多少?
byte 1字节 short 2字节 int 4字节 long 8字节 ...
- scrapy 资料整合
先看看scrapy的框架流程, 1,安装 scrapy 链接 查看即可. 2,新建scrapy项目 scrapy startproject 项目名 目录结构图 3,cd到项目名下,创建任务. scra ...
- python 取出字典的键或者值/如何删除一个字典的键值对/如何遍历字典
先定义一个字典并直接进行初始化赋值 my_dict = dict(name="lowman", age=45, money=998, hourse=None) 1.取出该字典所有的 ...
- 挂载U盘到linux中
一. 挂载U盘到linux中,也可以是虚拟机中的linux 1. 首先插上U盘 2. fdisk -l 找到自己的U盘设备,并且记住文件系统类型,主要看空间大小来判断,比如是/dev/sdc ...
- 安装openssl-devel
安装openssl-devel 0.操作系统为 RHEL6.7 1.描述:当开发人员需要调用openssl的库文件时,需要安装openssl-devel包 2.当根目录(即挂载点为 )的利用率为10 ...