hadoop之 Hadoop 2.x HA 、Federation
HDFS2.0之HA
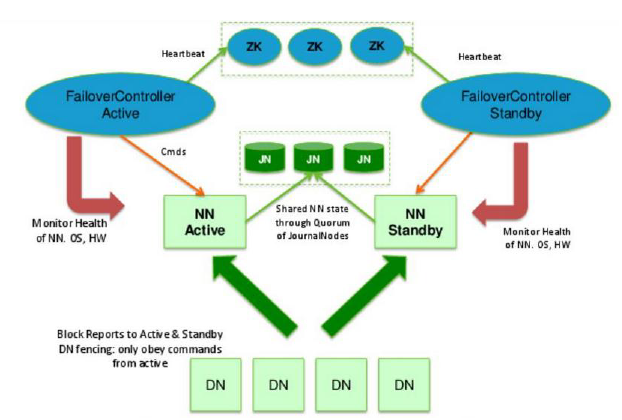
主备NameNode:
1、主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换;
2、主NameNode的信息发生变化后,会将信息写到共享数据存储系统中让备NameNode合并到自己的内存中;
3、所有DataNode同时向两个NameNode发送心跳信息(块信息);
两种切换方式:
1、手动切换:通过命令实现主备之间的切换,可以用于HDFS升级等场合;
2、自动切换:基于Zookeeper实现;
Zookeeper Failover Controller:向Zookeeper注册NameNode并监控NameNode健康状态,当NM挂掉后,ZKFC为NameNode竞争锁,获得锁的NameNode变成active;
多种共享数据存储系统可供选择
1、NFS
2、多个Journal Node构成集群(推荐)
基本原理,数据同时写入所有的JN,多数写入成功,则认为写成功;
一般配置奇数个JN,JN越多,容错性越好;比如有3个JN,只要两个写成功,则数据写成功,最多允许一个JN挂掉;
3、Bookeeper
相对于hadoop1.x中多了备NameNode,JournalNode(存储共享数据),ZKFC&ZK(主备NN切换)
HDFS2.0之Federation
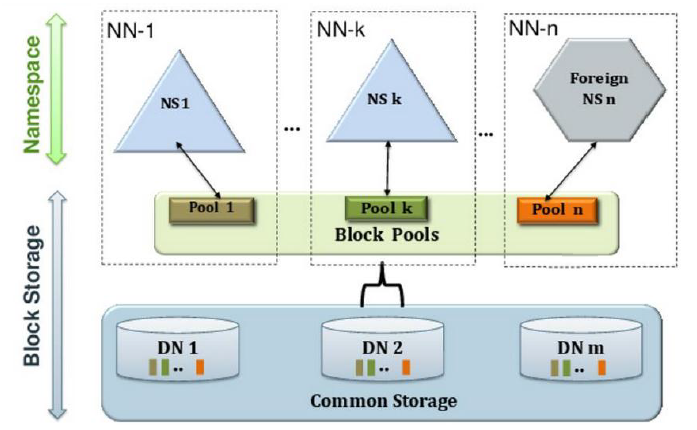
多个NN同时对外提供服务,每个NN分管一部分目录,多个NN共享底层DN存储;
此时每个NN都还是存在单点故障问题的,故还需要给Federation节点配置一个备用NN;
所有整个HADOOP2集群中可能存在的NN有:多个NN以及每个NN对应的备NN
带来的好处:单个NN内存和并发压力减小,NN彼此隔离,互不影响;
常见应用方法:
为不同业务创建不同NN,防止相互影响;(一个NN给开发用,一个NN测试用)
为不同需求创建不同NN,比如测试用的NN,生产用的NN;
HDFS2.0之其他实现机制(与1.0版本基本一致)
1、文件放置策略
文件被切成若干个block,存放在不同节点上;
切分过程对用户透明;
2、文件容错策略
基于副本的容错机制;
流水线复制;
3、副本放置策略
一个节点(1个rack)+ 两个节点(另1个rack)
4、......
hadoop之 Hadoop 2.x HA 、Federation的更多相关文章
- hadoop HA+Federation(高可用联邦)搭建配置(二)
hadoop HA+Federation(高可用联邦)搭建配置(二) 标签(空格分隔): hadoop core-site.xml <?xml version="1.0" e ...
- hadoop HA+Federation(高可用联邦)搭建配置(一)
hadoop HA+Federation(高可用联邦)搭建配置(一) 标签(空格分隔): 未分类 介绍 hadoop 集群一共有4种部署模式,详见<hadoop 生态圈介绍>. HA联邦模 ...
- Hadoop 学习笔记 (十) hadoop2.2.0 生产环境部署 HDFS HA Federation 含Yarn部署
其他的配置跟HDFS-HA部署方式完全一样.但JournalNOde的配置不一样>hadoop-cluster1中的nn1和nn2和hadoop-cluster2中的nn3和nn4可以公用同样的 ...
- Cloudera Hadoop 5& Hadoop高阶管理及调优课程(CDH5,Hadoop2.0,HA,安全,管理,调优)
1.课程环境 本课程涉及的技术产品及相关版本: 技术 版本 Linux CentOS 6.5 Java 1.7 Hadoop2.0 2.6.0 Hadoop1.0 1.2.1 Zookeeper 3. ...
- Hadoop 2、配置HDFS HA (高可用)
前提条件 先搭建 http://www.cnblogs.com/raphael5200/p/5152004.html 的环境,然后在其基础上进行修改 一.安装Zookeeper 由于环境有限,所以在仅 ...
- 国内第一篇详细讲解hadoop2的automatic HA+Federation+Yarn配置的教程
前言 hadoop是分布式系统,运行在linux之上,配置起来相对复杂.对于hadoop1,很多同学就因为不能搭建正确的运行环境,导致学习兴趣锐减.不过,我有免费的学习视频下载,请点击这里. hado ...
- hadoop2的automatic HA+Federation+Yarn配置的教程
前言 hadoop是分布式系统,运行在linux之上,配置起来相对复杂.对于hadoop1,很多同学就因为不能搭建正确的运行环境,导致学习兴趣锐减.不过,我有免费的学习视频下载,请点击这里. hado ...
- 【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型
忘的差不多了, 先补概念, 然后开始搭建集群实战 ... . 一 Hadoop版本 和 生态圈 1. Hadoop版本 (1) Apache Hadoop版本介绍 Apache的开源项目开发流程 : ...
- hadoop记录-hadoop集群日常运维命令
hadoop集群日常运维命令 #1.namenode hadoop namenode -format #格式化,慎用 su hdfs hadoop-daemon.sh start namenode h ...
- HA&Federation【转】
转自:http://blog.csdn.net/tutucute0000/article/details/39756123 从nameNode1.namenode2克隆出namenode3.namen ...
随机推荐
- mongo增删改查封装(C#)
Framework版本:.Net Framework 4 ConnectionUtil源码参见:https://www.cnblogs.com/threadj/p/10536273.html usin ...
- springcloud20---Config加入eureka
Config server也可以加用户名和密码.Config client通过用户名和密码访问. Config server也可以做成高可用集群. Config与eureka配置使用.把Config ...
- Qt信号和槽连接方式的选择
看了下Qt的帮助文档,发现connect函数最后还有一个缺省参数. connect函数原型是这样的: QMetaObject::Connection QObject::connect(const QO ...
- 【知识总结】Activiti工作流学习入门
1. 我理解的工作流: 在工作中慢慢接触的业务流程,就向流程控制语言一样,一步一步都对应的不同的业务,但整体串联起来就是一个完整的业务.而且实际工作中尤其是在企业内部系统的研发中,确实需要对应许多审批 ...
- 能否通过六面照片构建3D模型?比如人脸,全身的多角度照片,生成3D模型。?
https://www.zhihu.com/question/36412840 9023 添加评论 分享 邀请回答举报 收起 已关注写回答 9 个回答 默认排序 叛逆者 计算机图形学 ...
- SQL学习笔记之SQL查询练习题1
(网络搜集) 0x00 表名和字段 –1.学生表 Student(s_id,s_name,s_birth,s_sex) –学生编号,学生姓名, 出生年月,学生性别 –2.课程表 Course(c_id ...
- maven nexus私服搭建
1. 下载 wget http://download.sonatype.com/nexus/oss/nexus-2.12.0-01-bundle.tar.gz 2. 解压 tar zxvf nexus ...
- 百度语音识别vs科大讯飞语音识别
一.结果 从笔者试验的结果来看,科大讯飞的语音识别技术远超百度语音识别 二.横向对比 科大讯飞语音识别 百度语音识别 费用 各功能的前5小时免费 全程免费 转换精准率 非常高 比较低 linux ...
- ExtJS清除表格缓存
背景 在使用ExtJS时遇到不少坑,如果不影响使用也无所谓,但是有些不能忍的,比如表格数据缓存问题.如果第一次打开页面查询出一些数据展示在表格中:第二次打开,即使不查询也会有数据,这是缓存的数据. 我 ...
- devdocs
https://devdocs.io/ docker run --rm -d --name devdocs -p 9292:9292 devdocs/devdocs