掌握Spark机器学习库-08.7-决策树算法实现分类
数据集
iris.data
数据集概览

代码
package org.apache.spark.examples.examplesforml import org.apache.spark.SparkConf
import org.apache.spark.ml.classification.{DecisionTreeClassifier, NaiveBayes}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.sql.SparkSession import scala.util.Random object DeTree {
def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("iris")
val spark = SparkSession.builder().config(conf).getOrCreate()
spark.sparkContext.setLogLevel("WARN") ///日志级别 val file = spark.read.format("csv").load("D:\\8-6决策树\\iris.data")
//file.show() import spark.implicits._
val random = new Random()
val data = file.map(row =>{
val label = row.getString(4) match {
case "Iris-setosa" => 0
case "Iris-versicolor" => 1
case "Iris-virginica" => 2
} (row.getString(0).toDouble,
row.getString(1).toDouble,
row.getString(2).toDouble,
row.getString(3).toDouble,
label,
random.nextDouble())
}).toDF("_c0","_c1","_c2","_c3","label","rand").sort("rand")//.where("label = 1 or label = 0") val assembler = new VectorAssembler().setInputCols(Array("_c0","_c1","_c2","_c3")).setOutputCol("features") val dataset = assembler.transform(data)
val Array(train,test) = dataset.randomSplit(Array(0.8,0.2)) val dt = new DecisionTreeClassifier().setFeaturesCol("features").setLabelCol("label")
val model = dt.fit(train)
val result = model.transform(test)
result.show() val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(result)
println(s"""accuracy is $accuracy""")
}
}
输出结果:
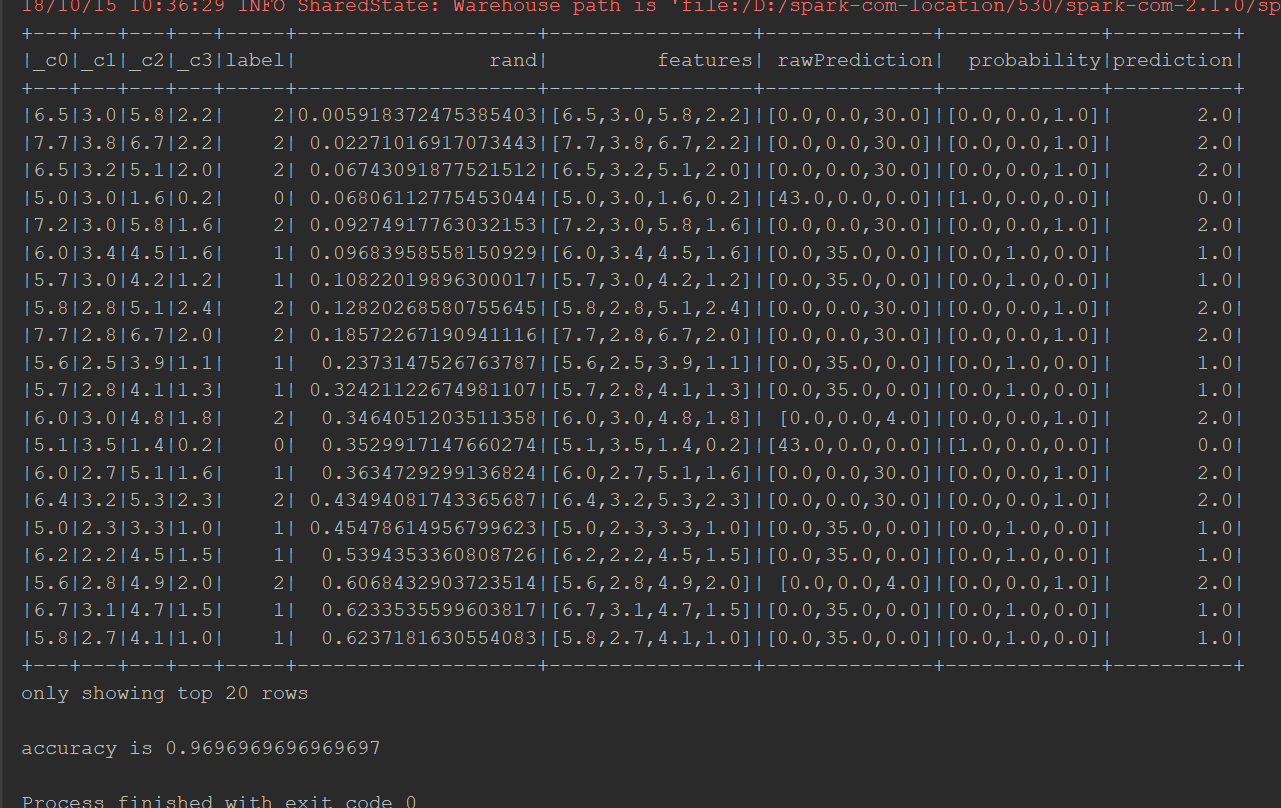
掌握Spark机器学习库-08.7-决策树算法实现分类的更多相关文章
- 掌握Spark机器学习库-08.2-朴素贝叶斯算法
数据集 iris.data 数据集概览 代码 import org.apache.spark.SparkConf import org.apache.spark.ml.classification.{ ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
- day-8 python自带库实现ID3决策树算法
前一天,我们基于sklearn科学库实现了ID3的决策树程序,本文将基于python自带库实现ID3决策树算法. 一.代码涉及基本知识 1. 为了绘图方便,引入了一个第三方treePlotter模块进 ...
- Spark机器学习库(MLlib)官方指南手册中文版
中文https://blog.csdn.net/liulingyuan6/article/details/53582300 https://yq.aliyun.com/articles/608083 ...
- 掌握Spark机器学习库-07.6-线性回归实现房价预测
数据集 house.csv 数据概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.fea ...
- 掌握Spark机器学习库-09.6-LDA算法
数据集 iris.data 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- 掌握Spark机器学习库-09.3-kmeans算法实现分类
数据集 iris.data 数据集概览 代码 package org.apache.spark.examples.hust.hml.examplesforml import org.apache.s ...
- 掌握Spark机器学习库-07.14-保序回归算法实现房价预测
数据集 house.csv 数据集概览 代码 package org.apache.spark.examples.examplesforml import org.apache.spark.ml.cl ...
- 掌握Spark机器学习库-07-回归算法原理
1)机器学习模型理解 统计学习,神经网络 2)预测结果的衡量 代价函数(cost function).损失函数(loss function) 3)线性回归是监督学习
随机推荐
- ios archives 出现的是other items而不是iOS Apps的解决方案
ios archives 出现的是other items而不是iOS Apps的解决方案 项目打包时出现的是不是出现在iOS Apps栏目下面,而是Other Items而且右边对应的Upload t ...
- 如何快速定位JVM中消耗CPU最多的线程? Java 性能调优
https://mp.weixin.qq.com/s/ZqlhPC06_KW6a9OSgEuIVw 上面的线程栈我们注意到 nid 的值其实就是线程 ID,它是十六进制的,我们将消耗 CPU 最高的线 ...
- MVC框架显示层——Velocity技术
Velocity,名称字面翻译为:速度.速率.迅速,用在Web开发里,用过的人可能不多,大都基本知道和在使用Struts,到底Velocity和Struts(Taglib和Tiles)是如何联系?在技 ...
- POJ3020 Antenna Placement —— 最大匹配 or 最小边覆盖
题目链接:https://vjudge.net/problem/POJ-3020 Antenna Placement Time Limit: 1000MS Memory Limit: 65536K ...
- (转)JFreeChart教程
JFreeChart教程 一.jFreeChart产生图形的流程 创建一个数据源(dataset)来包含将要在图形中显示的数据>>创建一个 JFreeChart 对象来代表要显示的图形&g ...
- HDU - 1255 覆盖的面积(线段树求矩形面积交 扫描线+离散化)
链接:线段树求矩形面积并 扫描线+离散化 1.给定平面上若干矩形,求出被这些矩形覆盖过至少两次的区域的面积. 2.看完线段树求矩形面积并 的方法后,再看这题,求的是矩形面积交,类同. 求面积时,用被覆 ...
- Morris Traversal方法遍历二叉树(非递归,不用栈,O(1)空间)——无非是在传统遍历过程中修改叶子结点加入后继结点信息(传统是stack记录),然后再删除恢复
先看看线索二叉树 n个结点的二叉链表中含有n+1(2n-(n-1)=n+1)个空指针域.利用二叉链表中的空指针域,存放指向结点在某种遍历次序下的前驱和后继结点的指针(这种附加的指针称为"线索 ...
- python名片管理系统
1.代码: (1)主程序 #!/usr/bin/env python # -*- coding: UTF-8 -*- import cards_tools # 无限循环,由用户主动决定什么时候退出循环 ...
- .NETFramework-Drawing:Font
ylbtech-.NETFramework-Drawing:Font 1.返回顶部 1. #region 程序集 System.Drawing, Version=4.0.0.0, Culture=ne ...
- Vijos P1782 借教室 ( 前缀和&&差分序列)
题目链接:借教室 题意:给出n天得教室数目,m个借教室得单子,按顺序借教室,问哪个单子不满足并输出 分析:可以用线段树做,会T,常数比较大,选择用差分序列维护前缀和,二分答案即可 #include&l ...