GEE&Python-demo1:利用Sentinel-2监测北京奥林匹克森林公园2024年NDVI变化(附Python版)
01 说明
1.1 逻辑和流程
简要流程:
- 获取指定区域指定时间范围的Sentinel-2影像并进行预处理
- 绘制并构建训练样本
- 训练随机森林分类器并分类
- 计算总体分类精度和混淆矩阵
ps: 提供JS版本和Python版本,但注意,无论是JS还是Python版本除了JS提供了GEE的Script 链接,直接给定的代码都是无法直接运行的,因为存在自定义创建的训练样本(需要自己手动在GEE的MAP上创建).同时geemap有创建训练样本的工具但是可能存在异常无法正常创建所有的训练样本或者零星地创建单一类样本(具体见: https://github.com/gee-community/geemap/issues/467)
1.2 数据集说明
使用的数据集为: Harmonized Sentinel-2 MSl:MultiSpectral Instrument, Level-2A (SR)(SR表示表面反射率即地表反射率, TOA版本为大气层顶反射率<包含大气层的影响>).
主要使用到的相关波段信息如下:
| 波段名称 | 描述 | 分辨率 | 比例系数 |
|---|---|---|---|
| B2 | Blue | 10 meters | 0.0001 |
| B3 | Green | 10 meters | 0.0001 |
| B4 | Red | 10 meters | 0.0001 |
其中,比例系数0.0001与像元DN值相乘即可得到真正的Sentinel-2表面反射率(原始值通过整数存储节省存储,通过0.0001缩放回来)
Sentinel-2中存在属性CLOUDY_PIXEL_PERCENTAGE表示影像的云覆盖率(单位为%)。
02 步骤和代码说明
2.1 创建训练样本
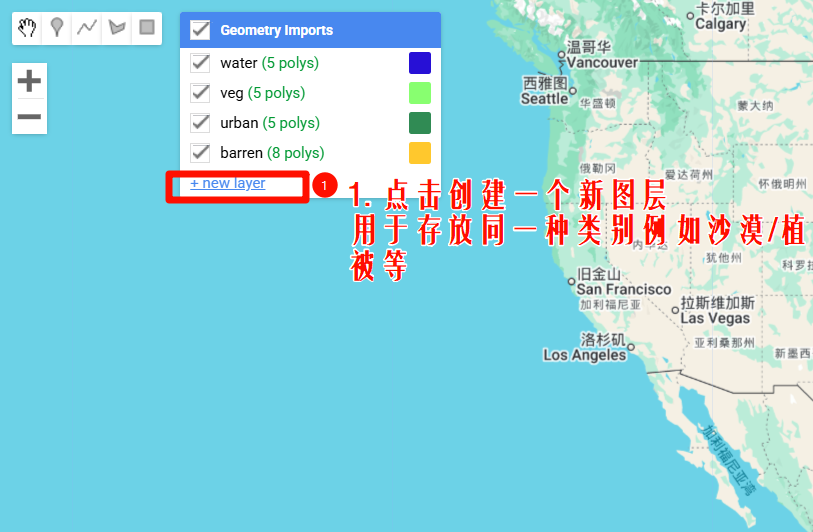
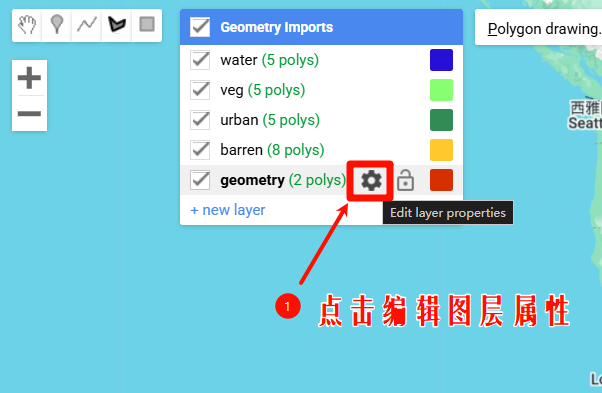
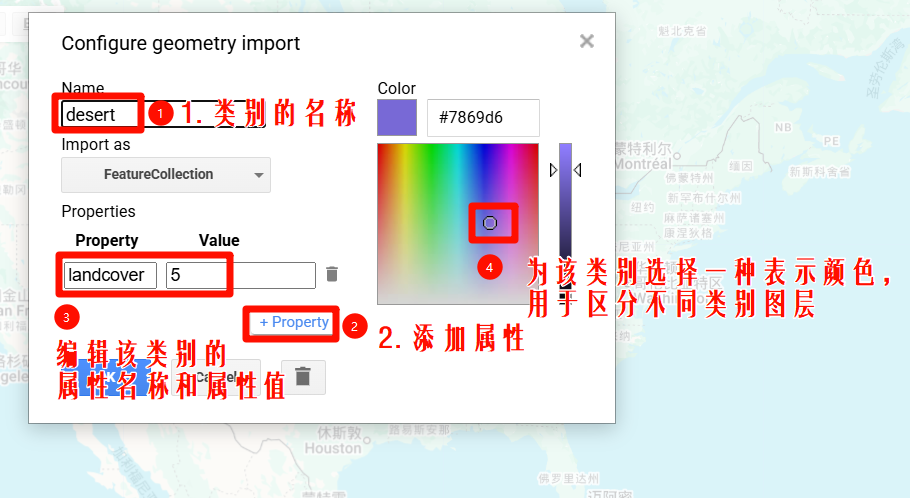
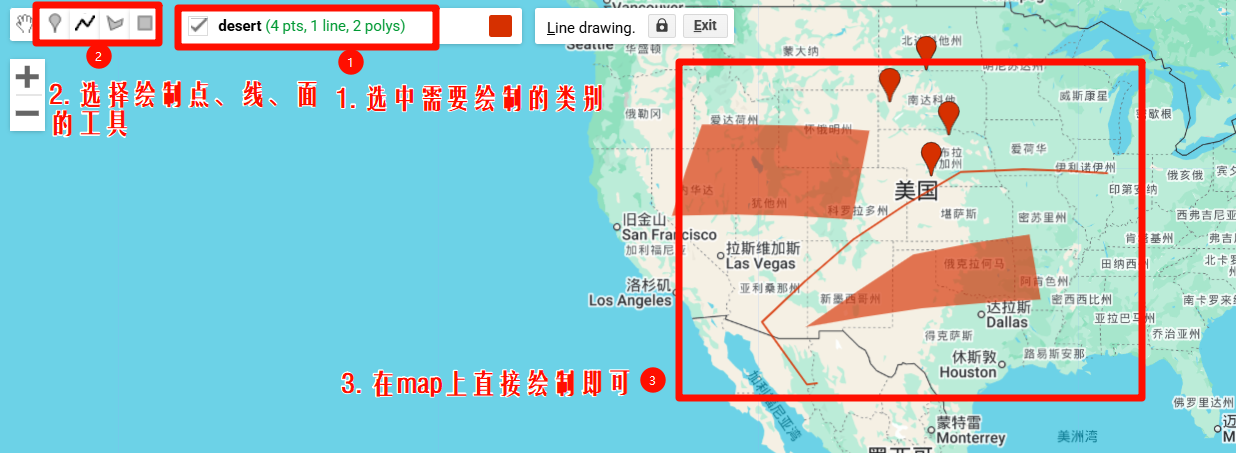
我们需要修改创建图层的数据类型,可创建的数据类型包括:
- Geometry
- Feature
- FeatureCollection
这里我们需要使用Feature和FeatureCollection数据类型存储你的训练样本.因为只有这两种数据类型才可以存储属性信息,而Geometry只能存储地理位置信息而没有办法存储属性信息(但是我们进行随机森林分类时是需要区分不同的类型,因此需要属性信息)。
对于大批量样本的创建,更推荐使用FeatureCollection数据类型.
2.2 JS代码
JS链接: https://code.earthengine.google.com/06958df4e6a89f3c78d2e3af18133e14
// // 用于检索(Inspector工具)北京市所在要素的属性
// var dataset = ee.FeatureCollection('FAO/GAUL_SIMPLIFIED_500m/2015/level2');
// Map.setCenter(116.5, 39.9, 8);
// Map.addLayer(dataset, {}, 'boundary');
// 准备
var start_date = '2024-06-01'
var end_date = '2024-08-31'
var bands = ['B2', 'B3', 'B4', 'B8']
var roi = ee.FeatureCollection('FAO/GAUL_SIMPLIFIED_500m/2015/level2') // 获取北京边界
.filter(ee.Filter.eq('ADM1_NAME', 'Beijing Shi'))
.first().geometry();
print('北京: ', roi);
var vis_param_s2 = {
'bands': ['B4', 'B3', 'B2'],
'min': 0,
'max': 1,
'gamma': 1.4
};
var vis_param_class = {
'min': 1,
'max': 4,
'palette': ['blue', 'green', 'gray', 'orange']
};
// 获取Sentinel-2 2024年夏季的影像
var img = ee.ImageCollection("COPERNICUS/S2_SR_HARMONIZED")
.filterBounds(roi)
.filterDate(start_date, end_date)
.filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE', 10))
.median() // 中值合成
.select(bands) // 红绿蓝+近红外波段
.clip(roi) // 裁剪
.multiply(0.0001); // 比例缩放 --> SR
print('Sentinel-2', img);
// 显示预处理好的影像
Map.addLayer(img, vis_param_s2, 'Sentinel-2 true color');
// 构建训练样本
var samples = water.merge(veg).merge(urban).merge(barren);
Export.table.toAsset(
samples,
'classification_samples',
'projects/ee-chaoqiezione1/assets/MyTemp/classification_samples'
);
samples = img.sampleRegions({
collection: samples,
properties: ['landcover'], // samples种保留的属性(默认所有非系统属性)
scale: 10 // Sentinel-2的空间分辨率是10m
})
print('样本', samples.size()); // 不要尝试打印样本, 样本量巨大会超出限制
// 基于随机森林训练
var classifier = ee.Classifier.smileRandomForest(50).train({
features: samples,
classProperty: 'landcover',
inputProperties: bands
}); // 训练好分类器
// 分类
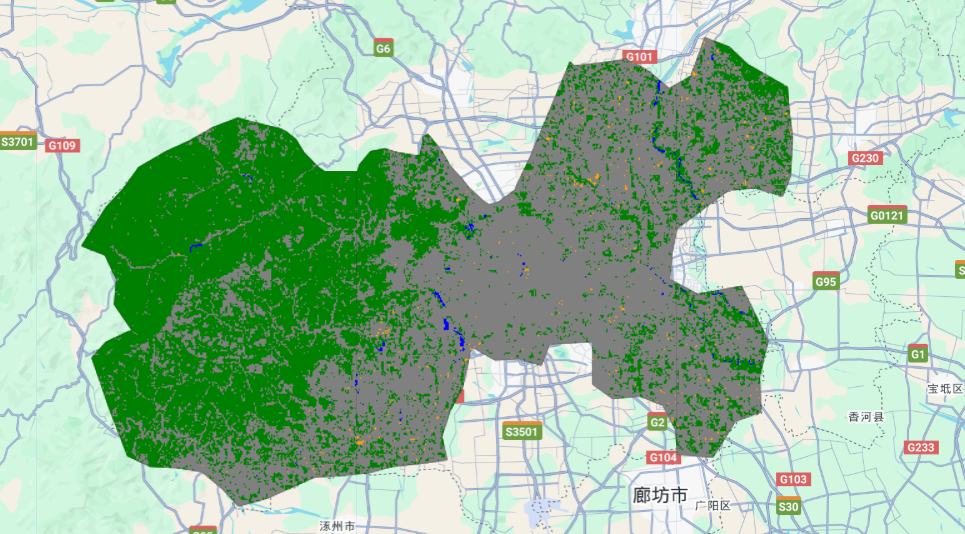
var class_img = img.classify(classifier);
print(class_img)
// 显示分类结果
Map.addLayer(class_img, vis_param_class, 'Classification')
Map.centerObject(roi, 8)
// 精度评估
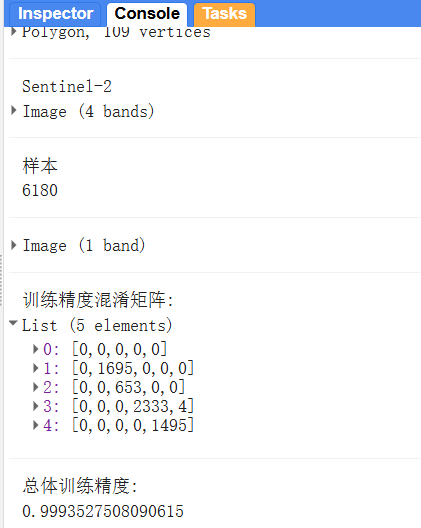
var train_accuracy = classifier.confusionMatrix() // 混淆矩阵
print('训练精度混淆矩阵: ', train_accuracy)
print('总体训练精度: ', train_accuracy.accuracy())
对于输出的混淆矩阵, 输出见:
Computes a 2D confusion matrix for a classifier based on its training data (e.g., resubstitution error). Axis 0 of the matrix corresponds to the input classes and axis 1 corresponds to the output classes. The rows and columns start at class 0 and increase sequentially up to the maximum class value, so some rows or columns might be empty if the input classes aren't 0-based or sequential.
说明行表示实际的类别(真实的),列表示预测的类别。
输出结果:
2.3 Python代码
#%% md
# 基于Sentinel-2影像的北京市监督分类与土地覆盖制图
#%%
import ee
import geemap
ee.Initialize()
Map = geemap.Map()
Map
#%%
# 准备
start_date = '2024-06-01'
end_date = '2024-08-31'
bands = ['B8', 'B4', 'B3', 'B2']
roi = (ee.FeatureCollection('FAO/GAUL_SIMPLIFIED_500m/2015/level2') # 获取北京市边界
.filter(ee.Filter.eq('ADM1_NAME', 'Beijing Shi'))
.first().geometry())
vis_param_s2 = {
'bands': ['B4', 'B3', 'B2'],
'min': 0,
'max': 1,
'gamma': 1.4
}
vis_param_class = {
'min': 1,
'max': 4,
'palette': ['blue', 'green', 'gray', 'orange']
}
#%%
# 预处理sentinel-2影像
img = (ee.ImageCollection("COPERNICUS/S2_SR_HARMONIZED")
.filterBounds(roi) # 只提取过境Sentinel-2的影像
.filterDate(start_date, end_date) # 只提取2024年夏季的Sentinel-2影像
.filter(ee.Filter.lt('CLOUDY_PIXEL_PERCENTAGE', 10)) # 只提取云覆盖率小于10%的影像
.select(['B8', 'B5', 'B4', 'B3', 'B2'])
.median() # 中位数合成
.clip(roi) # 裁剪掩膜
.multiply(0.0001)) # 比例缩放回地表反射率
Map.addLayer(img, vis_param_s2, 'Sentinel-2')
Map
#%%
# 构建训练样本(由于geemap创建训练样本存在问题: 创建的样本可能存在不全,因此这里直接调用gee上创建好的训练样本<存在放在Asset上>)
samples = ee.FeatureCollection('projects/ee-chaoqiezione1/assets/MyTemp/classification_samples')
samples = img.sampleRegions(collection=samples, properties=['landcover'], scale=10)
#%%
# 创建随机森立训练器
classifier = ee.Classifier.smileRandomForest(50).train(
features=samples, # 训练样本
classProperty='landcover', # 分类的属性
inputProperties=bands # 输入给分类器训练的特征属性
)
#%%
# 分类
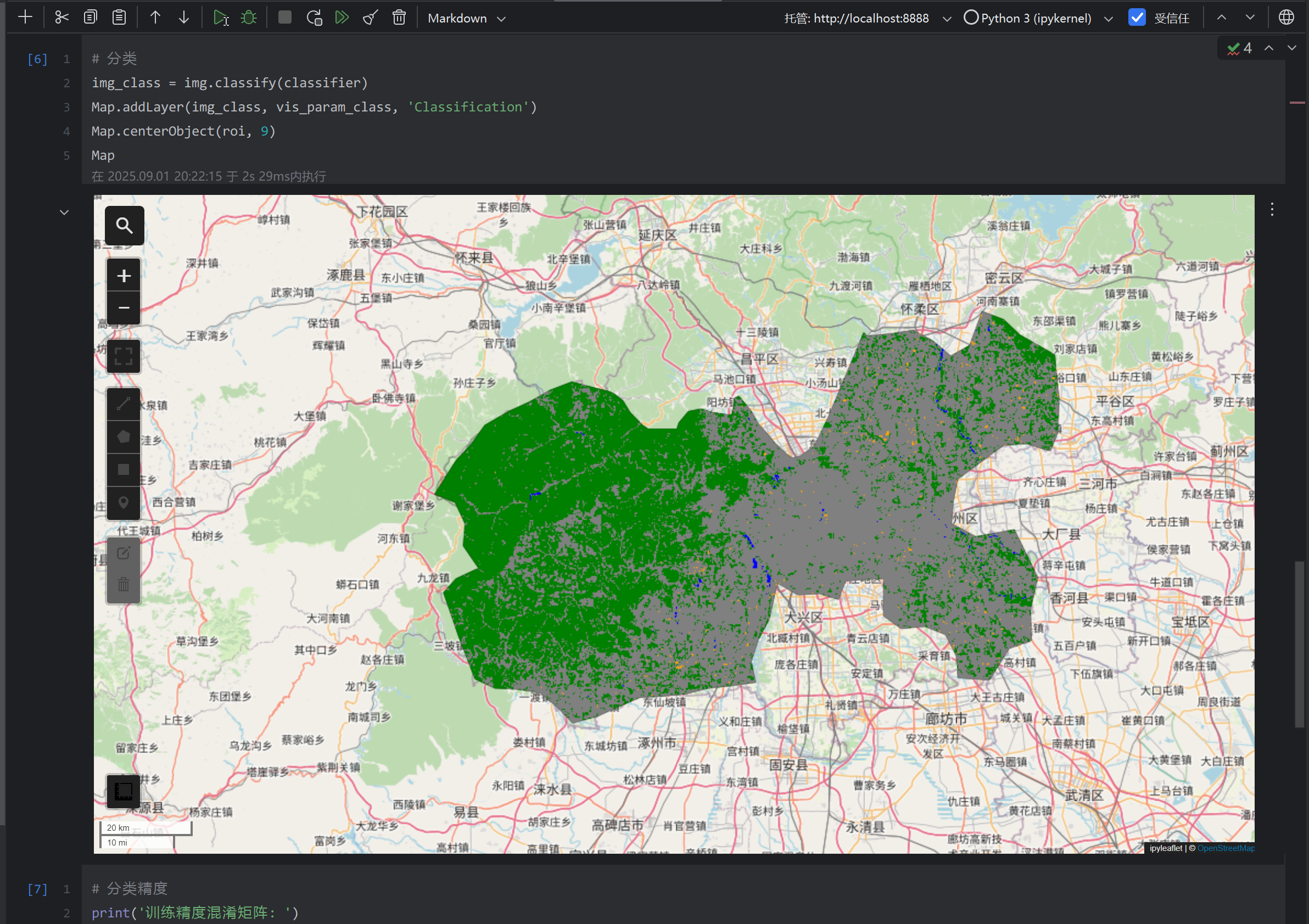
img_class = img.classify(classifier)
Map.addLayer(img_class, vis_param_class, 'Classification')
Map.centerObject(roi, 9)
Map
#%%
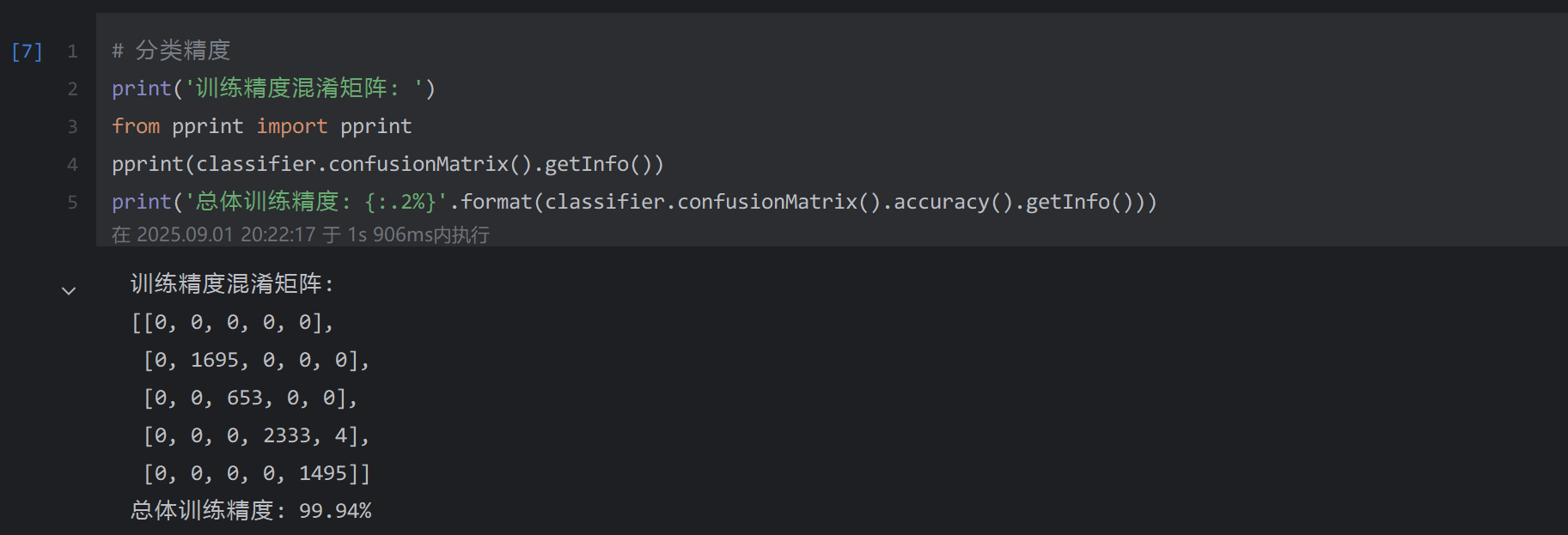
# 分类精度
print('训练精度混淆矩阵: ')
from pprint import pprint
pprint(classifier.confusionMatrix().getInfo())
print('总体训练精度: {:.2%}'.format(classifier.confusionMatrix().accuracy().getInfo()))
输出结果:
GEE&Python-demo1:利用Sentinel-2监测北京奥林匹克森林公园2024年NDVI变化(附Python版)的更多相关文章
- 全网最详细中英文ChatGPT-GPT-4示例文档-从0到1快速入门python代码解释应用——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)
目录 Introduce 简介 setting 设置 Prompt 提示 Sample response 回复样本 API request 接口请求 python接口请求示例 node.js接口请求示 ...
- (转)利用Auto ARIMA构建高性能时间序列模型(附Python和R代码)
转自: 原文标题:Build High Performance Time Series Models using Auto ARIMA in Python and R 作者:AISHWARYA SI ...
- Python中利用函数装饰器实现备忘功能
Python中利用函数装饰器实现备忘功能 这篇文章主要介绍了Python中利用函数装饰器实现备忘功能,同时还降到了利用装饰器来检查函数的递归.确保参数传递的正确,需要的朋友可以参考下 " ...
- Python 3 利用 Dlib 19.7 实现人脸识别和剪切
0.引言 利用python开发,借助Dlib库进行人脸识别,然后将检测到的人脸剪切下来,依次排序显示在新的图像上: 实现的效果如下图所示,将图1原图中的6张人脸检测出来,然后剪切下来,在图像窗口中依次 ...
- Python开发——利用正则表达式实现计算器算法
Python开发--利用正则表达式实现计算器算法 (1)不使用eval()等系统自带的计算方法 (2)实现四则混合运算.括号优先级解析 思路: 1.字符串预处理,将所有空格去除 2.判断是否存在括号运 ...
- Python 3 利用 Dlib 19.7 实现摄像头人脸识别
0.引言 利用python开发,借助Dlib库捕获摄像头中的人脸,提取人脸特征,通过计算欧氏距离来和预存的人脸特征进行对比,达到人脸识别的目的: 可以自动从摄像头中抠取人脸图片存储到本地: 根据抠取的 ...
- python中利用matplotlib绘图可视化知识归纳
python中利用matplotlib绘图可视化知识归纳: (1)matplotlib图标正常显示中文 import matplotlib.pyplot as plt plt.rcParams['fo ...
- python:利用xlrd模块操作excel
在自动化测试过程中,对测试数据的管理和维护是一个不可忽视的点.一般来说,如果测试用例数据不是太多的话,使用excel管理测试数据是个相对来说不错的选择. 这篇博客,介绍下如何利用python的xlrd ...
- python:利用configparser模块读写配置文件
在自动化测试过程中,为了提高脚本的可读性和降低维护成本,将一些通用信息写入配置文件,将重复使用的方法写成公共模块进行封装,使用时候直接调用即可. 这篇博客,介绍下python中利用configpars ...
- [python]操作redis sentinel以及cluster
先了解清楚sentinel和cluster的差别,再学习使用python操作redis的API,感觉会更加清晰明白. 1.redis sentinel和cluster的区别 sentinel遵循主从结 ...
随机推荐
- [arc133e]Cyclic Medians
E - Cyclic Medians 看到中位数,就是经典套路:将\(\geq\)中位数的都赋值为\(1\),\(<\)的赋值为\(0\) 那么对于数\(A\),就等于\(\sum_{i=1}^ ...
- 以接口肢解bean factory,源码没那么神秘
本来昨天在看 spring frame的八股, 看到了IOC部分,但是实在看不懂是什么东西,讲是讲源码部分,但又不完全讲,我想着那我要不自己看一下源码 这是我画的Bean Factory的大致关系图 ...
- pdfjs-dist v2.11.338写个react demo
app.jsx import './App.css' import * as pdfjs from "pdfjs-dist"; import "pdfjs-dist/we ...
- windows failed to start
现象 今天启动我的window11的时候,突然进不去系统了 解决办法 找一个winPe的u盘,进入. 然后找到Windows引导修复工具,这个是在winPe里都会内置的工具(比如老毛桃.大白菜.微PE ...
- 智力大冲浪 C++
题目描述 小伟报名参加中央电视台的智力大冲浪节目.本次挑战赛吸引了众多参赛者,主持人为了表彰大家的勇气,先奖励每个参赛者 m 元.先不要太高兴!因为这些钱还不一定都是你的?!接下来主持人宣布了比赛规则 ...
- deque STL 深入剖析 TODO
简介 deque 对于插入和删除的性能代价远小于 vector 但是这是存在一定代价的. 参考链接 https://blog.csdn.net/wk_bjut_edu_cn/article/detai ...
- jz2440 环境搭建
2.搭建三者互通 1.搭建TFTP服务 这两点搞定基本可以飞奔了 记录一下 配置 板子的ip ifconfig eth3 IP地址 不用重启network服务因为也没有这个服务 当然虚拟机里面的一样 ...
- 739 每日温度 && 单调栈算法的思路
简介 如果用暴力岂不是太不优雅了. 有些问题可以使用单调栈来进行计算. 简单思想 构建一个栈, 栈是一个有顺序的, 里面有一个while循环,然后 如果满足一定的条件, 将会一直弹出. code cl ...
- ETL的全量和增量模式
在当今信息爆炸的时代,数据管理已经成为各行各业必不可少的一环.而在数据管理中,全量与增量模式作为两种主要的策略,各自具有独特的优势和适用场景,巧妙地灵活运用二者不仅能提升数据处理效率,更能保障数据的准 ...
- lim x→c f(x) = L数学语言:∀ ϵ>0, ∃ δ>0 S.T. for all x≠c, if |x-c|<δ, then |f(x)-L|<ϵ 常用记号: “∃ ”:“存在”或“可以找到”,“∀ ”: “对于任意的”或“对于每一个”, maxS:数集S极大值, minS:数集S极小值, supS:上确界(上界最小值), infS下确界(下界最大值)
实数集Completeness Axiom(连续性公理) Q: 谬论: "实数集上, 怎么求出点A"相邻"的那一点, 或A点的"下一点"? 或 &qu ...