spark (一) 入门 & 安装
基本概念
spark主要是计算框架
spark 核心模块
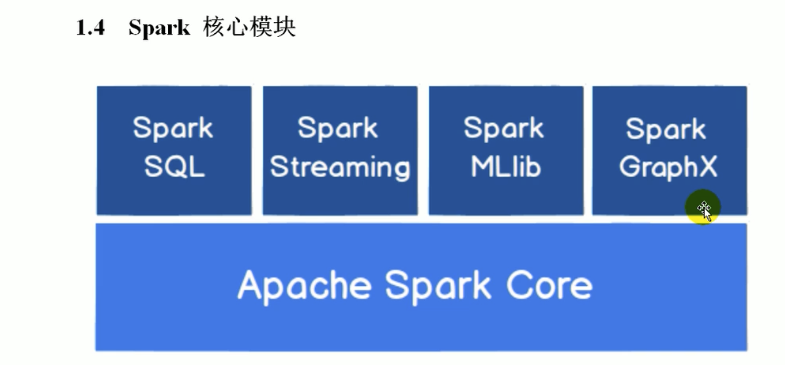
spark core (核心)
spark core 提供了最基础最核心的功能,其他的功能比如 spark sql, spark streaming, graphx, MLlib 都是在此基础上扩展的
spark sql (结构化数据操作)
spark sql是用来操作结构化数据的组件。通过spark sql可以使用 sql 或者hive版本的sql方言(hql) 来查询数据
spark streaming (流式数据操作)
spark streaming 是针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API
部署模式
local(本地模式)
常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
standalone(集群模式)
典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark支持ZooKeeper来实现 HA.
此处spark即负责计算也负责资源管理
on yarn(集群模式)
运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算
on mesos(集群模式)
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算
on cloud(集群模式)
比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3;Spark 支持多种分布式存储系统:HDFS 和 S3
docker-compose安装spark集群
参考: https://blog.csdn.net/weixin_42688573/article/details/127130863
执行docker-compose安装
- docker-compose.yml
version: "3.3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
ports:
- 9870:9870
- 9000:9000
volumes:
- ./hadoop_volumn/dfs/name:/hadoop/dfs/name
- ./input_files:/input_files
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
ports:
- 9064:9064
depends_on:
- namenode
volumes:
- ./hadoop_volumn/dfs/data:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
depends_on:
- namenode
- datanode
ports:
- 8088:8088
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager
ports:
- 8042:8042
depends_on:
- namenode
- datanode
- resourcemanager
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
ports:
- 8188:8188
depends_on:
- namenode
- datanode
- resourcemanager
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- ./hadoop_volumn/yarn/timeline:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
master:
image: bitnami/spark:3.2.1
container_name: master
hostname: master
user: root
environment:
- SPARK_MODE=master
- SPARK_MASTER_URL=spark://master:7077
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
ports:
- '8080:8080'
- '7077:7077'
- '4040:4040'
volumes:
- ./spark_volumn/python:/python
- ./spark_volumn/jars:/jars
worker1:
image: bitnami/spark:3.2.1
container_name: worker1
hostname: worker1
user: root
depends_on:
- master
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
worker2:
image: bitnami/spark:3.2.1
container_name: worker2
hostname: worker2
user: root
depends_on:
- master
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- hadoop.env
CORE_CONF_fs_defaultFS=hdfs://namenode:9000
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
CORE_CONF_io_compression_codecs=org.apache.hadoop.io.compress.SnappyCodec
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
HDFS_CONF_dfs_namenode_datanode_registration_ip___hostname___check=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_scheduler_class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___mb=8192
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___vcores=4
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource__tracker_address=resourcemanager:8031
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_mapreduce_map_output_compress=true
YARN_CONF_mapred_map_output_compress_codec=org.apache.hadoop.io.compress.SnappyCodec
YARN_CONF_yarn_nodemanager_resource_memory___mb=16384
YARN_CONF_yarn_nodemanager_resource_cpu___vcores=8
YARN_CONF_yarn_nodemanager_disk___health___checker_max___disk___utilization___per___disk___percentage=98.5
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_nodemanager_aux___services=mapreduce_shuffle
MAPRED_CONF_mapreduce_framework_name=yarn
MAPRED_CONF_mapred_child_java_opts=-Xmx4096m
MAPRED_CONF_mapreduce_map_memory_mb=4096
MAPRED_CONF_mapreduce_reduce_memory_mb=8192
MAPRED_CONF_mapreduce_map_java_opts=-Xmx3072m
MAPRED_CONF_mapreduce_reduce_java_opts=-Xmx6144m
MAPRED_CONF_yarn_app_mapreduce_am_env=HADOOP_MAPRED_HOME=/data/docker-compose/hadoop-3.2.1/
MAPRED_CONF_mapreduce_map_env=HADOOP_MAPRED_HOME=/data/docker-compose/hadoop-3.2.1/
MAPRED_CONF_mapreduce_reduce_env=HADOOP_MAPRED_HOME=/data/docker-compose/hadoop-3.2.1/
等待安装完成
检验安装完成
常见问题:ResourceManager启动错误,日志看namenode处于safemode
# 退出安全模式
docker exec namenode hadoop dfsadmin -safemode leave
# 重新启动resourcemanager
docker start resourcemanager
- docker ps

一共起了如下几个容器
spark (一) 入门 & 安装的更多相关文章
- [转] Spark快速入门指南 – Spark安装与基础使用
[From] https://blog.csdn.net/w405722907/article/details/77943331 Spark快速入门指南 – Spark安装与基础使用 2017年09月 ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- Spark快速入门 - Spark 1.6.0
Spark快速入门 - Spark 1.6.0 转载请注明出处:http://www.cnblogs.com/BYRans/ 快速入门(Quick Start) 本文简单介绍了Spark的使用方式.首 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Spark学习笔记——安装和WordCount
1.去清华的镜像站点下载文件spark-2.1.0-bin-without-hadoop.tgz,不要下spark-2.1.0-bin-hadoop2.7.tgz 2.把文件解压到/usr/local ...
- spark一些入门资料
spark一些入门资料 A Scala Tutorial for Java Programmers http://docs.scala-lang.org/tutorials/scala-for-jav ...
- [bigdata] spark集群安装及测试
在spark安装之前,应该已经安装了hadoop原生版或者cdh,因为spark基本要基于hdfs来进行计算. 1. 下载 spark: http://mirrors.cnnic.cn/apache ...
- Win7 单机Spark和PySpark安装
欢呼一下先.软件环境菜鸟的我终于把单机Spark 和 Pyspark 安装成功了.加油加油!!! 1. 安装方法参考: 已安装Pycharm 和 Intellij IDEA. win7 PySpark ...
- Debian 入门安装与配置2
Debian 入门安装与配置2 1. C/C++开发必装软件 atp-get install gcc 这个不用说,用来编译C程序 apt-get install g++ 用来编译C++程序 ap ...
随机推荐
- HDFS 重要机制之 checkpoint
核心概念 hdfs checkpoint 机制对于 namenode 元数据的保护至关重要, 是否正常完成检查点是评估 hdfs 集群健康度和风险的重要指标 editslog : 对 hdfs 操作的 ...
- 一文彻底弄懂MySQL的优化
在企业级 Web 开发中,MySQL 优化是至关重要的,它直接影响系统的响应速度.可扩展性和整体性能.下面从不同角度,列出详细的 MySQL 优化技巧,涵盖查询优化.索引设计.表结构设计.配置调整等方 ...
- 微信H5分享外部链接,缩略图不显示
可关注微信公众号酒酒酒酒查看原文: 前言:最近做了一款推广茶的APP软件,展厅.产品需要分享功能:从APP内分享到H5网页:微信内打开H5网页,点击微信内右上角三个点,可再次分享: 注意:大多数情况下 ...
- Go语言学习 _基础04 _Map&Set
Go语言学习 _基础04 _Map&Set 1.map package map_test import ( "fmt" "testing" ) func ...
- 看图对比Pytest、Unittest
- 如何在离线的Linux服务器上部署 Ollama,并使用 Ollama 管理运行 Qwen 大模型
手动安装 Ollama 根据Linux的版本下载对应版本的 Ollama, 查看Linux CPU型号,使用下面的命令 #查看Linux版本号 cat /proc/version #查看cpu架构 l ...
- iconfont图标库的使用
https://www.iconfont.cn/ -- 点击链接进入官网 择自己需要的图标加购物车 点击资源管理->我的项目 选择你需要的项目->下载到本地 将下载的压缩包进行解压,解压后 ...
- Flink CDC 实时同步 MySQL
Flink CDC 系列文章 Flink CDC 实时同步 MySQL Flink CDC 实时同步 Oracle 准备工作 MySQL 数据库(version: 5.7.25),注意,MySQL 数 ...
- Mac之终端工具iterm2
1. 安装 iTerm2 下载地址:https://www.iterm2.com/downloads.html 下载的是压缩文件,解压后是执行程序文件,你可以直接双击,或者直接将它拖到 Applica ...
- 重磅推出 Sdcb Chats:一个全新的开源大语言模型前端
重磅推出 Sdcb Chats:一个全新的开源大语言模型前端 在当前大语言模型(LLM)蓬勃发展的时代,各类 LLM 前端层出不穷.那么,为什么我们还需要另一个 LLM 前端呢? 最初的原因在于质感的 ...