论文解读《LightRAG: Simple and Fast Retrieval-Augmented Generation》
博客:https://learnopencv.com/lightrag
视频:https://www.youtube.com/watch?v=oageL-1I0GE
代码:https://github.com/HKUDS/LightRAG
论文:https://arxiv.org/abs/2410.05779
- 时间:2024.10
- 单位:University of Hong Kong、Beijing University of Posts and Telecommunications
RAG基本
好文:https://zhuanlan.zhihu.com/p/675509396
数据准备阶段:数据提取——>文本分块(Chunking)——>向量化(embedding)——>数据入库
应用阶段:用户提问——>数据检索(召回)——>重排/过滤——>注入Prompt——>LLM生成答案
RAG发展
传统RAG:
(1)痛点:- 它们无法捕捉分散在多个文档中的碎片信息之间的相互联系,这使得概括全面的见解变得具有挑战性。
- 有限的上下文理解源于缺乏对检索到的块的整体概述。
- 当数据量不断增长时,就会出现可扩展性效率低下的问题,从而导致检索质量不佳。
GraphRAG:
好文:GraphRAG学习小结(2)_graphrag local-CSDN博客
论文:https://arxiv.org/pdf/2404.16130
- 时间:2024.4
- 单位:Microsoft
(1)创新:- 为了构建结构化索引知识图谱KG,GraphRAG 使用 LLM 从源文档中提取实体和关系。KG有什么好处呢?
而传统 RAG 主要依赖于文本块的相似匹配,如果查询问题与存储文本不完全匹配或不在同一个文本块中,就可能无法返回最相关的结果,导致生成结果不够精准。GraphRAG可以有效地连接和聚合多个相关特性,即使它们在不同的节点中表达,也能通过图谱中的关系找到最佳检索结果。因此,它能更精确地满足复杂、多维的用户查询。
传统RAG的一大痛点是它虽然能够较好的回答一些事实性问题,但是在面对一些统计性、总结性、概要性的QFS问题(Query-Focused Summarization)时却无能为力,或需要采用更复杂的技术手段来解决。GraphRAG的一个主要出发点也是能够更好的回答基于高层语义理解的总结性查询问题。
(2)痛点:
GraphRAG 运行速度通常非常慢,因为它需要多个 LLM API 调用,可能会达到速率限制。
它的成本极高。
为了将新数据合并到现有的图形索引中,我们还需要为以前的数据重建整个 KG,这是一种低效的方法。
没有对重复元素执行明确的重复数据删除步骤,这会导致图形索引嘈杂。
- 为了构建结构化索引知识图谱KG,GraphRAG 使用 LLM 从源文档中提取实体和关系。KG有什么好处呢?
快速总结(vs GraphRAG)
(1)LightRAG 的知识图谱可以增量更新。为了将新数据合并到现有的图形索引中,GraphRAG 还需要为以前的数据重建整个 KG
(2)结合了 graph indexing 和 standard embedding 方法构建知识图谱。相对于 GraphRAG 以社区遍历的方法,LightRAG 专注于实体和关系的检索,进而减少检索开销
(3)Hybrid Query双层检索策略,结合了 local 和 global 方法检索
(4)推理速度更快。在检索阶段,LightRAG 需要少于 100 个token和一个 API 调用,而 GraphRAG 需要 社区数量 x 每个社区的平均令牌数量token
详细步骤

构建基于图的文本索引(知识图谱 KG)
(1)R(.),提取实体和关系:正如 GraphRAG 中看到的那样,这里精心设计的提示词被发送到 LLM 以获取节点和边

"""Example 1:
Entity_types: [person, technology, mission, organization, location]
Text:
while Alex clenched his jaw, the buzz of frustration dull against the backdrop of Taylor's authoritarian certainty. It was this competitive undercurrent that kept him alert, the sense that his and Jordan's shared commitment to discovery was an unspoken rebellion against Cruz's narrowing vision of control and order.
Then Taylor did something unexpected. They paused beside Jordan and, for a moment, observed the device with something akin to reverence. “If this tech can be understood..." Taylor said, their voice quieter, "It could change the game for us. For all of us.”
The underlying dismissal earlier seemed to falter, replaced by a glimpse of reluctant respect for the gravity of what lay in their hands. Jordan looked up, and for a fleeting heartbeat, their eyes locked with Taylor's, a wordless clash of wills softening into an uneasy truce.
It was a small transformation, barely perceptible, but one that Alex noted with an inward nod. They had all been brought here by different paths
################
Output:
("entity"{tuple_delimiter}"Alex"{tuple_delimiter}"person"{tuple_delimiter}"Alex is a character who experiences frustration and is observant of the dynamics among other characters."){record_delimiter}
("entity"{tuple_delimiter}"Taylor"{tuple_delimiter}"person"{tuple_delimiter}"Taylor is portrayed with authoritarian certainty and shows a moment of reverence towards a device, indicating a change in perspective."){record_delimiter}
("entity"{tuple_delimiter}"Jordan"{tuple_delimiter}"person"{tuple_delimiter}"Jordan shares a commitment to discovery and has a significant interaction with Taylor regarding a device."){record_delimiter}
("entity"{tuple_delimiter}"Cruz"{tuple_delimiter}"person"{tuple_delimiter}"Cruz is associated with a vision of control and order, influencing the dynamics among other characters."){record_delimiter}
("entity"{tuple_delimiter}"The Device"{tuple_delimiter}"technology"{tuple_delimiter}"The Device is central to the story, with potential game-changing implications, and is revered by Taylor."){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Taylor"{tuple_delimiter}"Alex is affected by Taylor's authoritarian certainty and observes changes in Taylor's attitude towards the device."{tuple_delimiter}"power dynamics, perspective shift"{tuple_delimiter}7){record_delimiter}
("relationship"{tuple_delimiter}"Alex"{tuple_delimiter}"Jordan"{tuple_delimiter}"Alex and Jordan share a commitment to discovery, which contrasts with Cruz's vision."{tuple_delimiter}"shared goals, rebellion"{tuple_delimiter}6){record_delimiter}
("relationship"{tuple_delimiter}"Taylor"{tuple_delimiter}"Jordan"{tuple_delimiter}"Taylor and Jordan interact directly regarding the device, leading to a moment of mutual respect and an uneasy truce."{tuple_delimiter}"conflict resolution, mutual respect"{tuple_delimiter}8){record_delimiter}
("relationship"{tuple_delimiter}"Jordan"{tuple_delimiter}"Cruz"{tuple_delimiter}"Jordan's commitment to discovery is in rebellion against Cruz's vision of control and order."{tuple_delimiter}"ideological conflict, rebellion"{tuple_delimiter}5){record_delimiter}
("relationship"{tuple_delimiter}"Taylor"{tuple_delimiter}"The Device"{tuple_delimiter}"Taylor shows reverence towards the device, indicating its importance and potential impact."{tuple_delimiter}"reverence, technological significance"{tuple_delimiter}9){record_delimiter}
("content_keywords"{tuple_delimiter}"power dynamics, ideological conflict, discovery, rebellion"){completion_delimiter}"""
(2)P(.),LLM 分析键值对生成:键 (K) 是一个单词或短语,而值 (V) 是一段总结相关内容的段落。为每个实体及每条关系生成一个文本键值对(K, V),其中 K 是一个单词或短语,便于高效检索,V 是一个文本段落,用于文本片段的总结。
LightRAG combines graph indexing and standard embedding based approach. These KV data structures offer a more precise retrieval than less accurate standard embedding only RAG or inefficient chunk traversal techniques in GraphRAG.

PROMPTS[
"summarize_entity_descriptions"
] = """You are a helpful assistant responsible for generating a comprehensive summary of the data provided below.
Given one or two entities, and a list of descriptions, all related to the same entity or group of entities.
Please concatenate all of these into a single, comprehensive description. Make sure to include information collected from all the descriptions.
If the provided descriptions are contradictory, please resolve the contradictions and provide a single, coherent summary.
Make sure it is written in third person, and include the entity names so we the have full context.
Use {language} as output language.
#######
-Data-
Entities: {entity_name}
Description List: {description_list}
#######
Output:
"""
(3) D(.),重复数据删除以优化图形操作:通过去重函数识别并合并来自不同段落的相同实体和关系。
最后,我们得到了初始 KG 的最终优化版本:
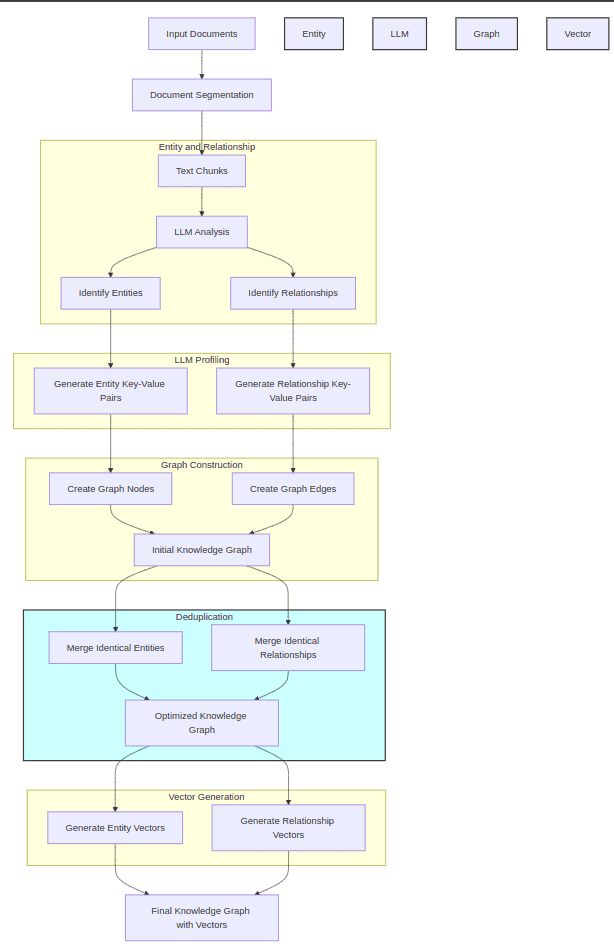
双层检索机制

(1)对于给定的查询,LightRAG 的检索算法会提取局部查询关键词(low_level_keywords)和全局查询关键词(high_level_keywords):

(2)检索算法使用向量数据库来匹配局部查询关键词与候选实体,以及全局查询关键词与候选关系:
async def _build_global_query_context(
keywords,
knowledge_graph_inst: BaseGraphStorage,
entities_vdb: BaseVectorStorage,
relationships_vdb: BaseVectorStorage,
text_chunks_db: BaseKVStorage[TextChunkSchema],
query_param: QueryParam,
):
# 用keywords匹配top_k个最相关的relationships
edge_datas = await relationships_vdb.query(keywords, top_k=query_param.top_k)
# 根据relationships找到entities
use_entities = await _find_most_related_entities_from_relationships(
edge_datas, query_param, knowledge_graph_inst
)
# 找到对应的文本块
use_text_units = await _find_related_text_unit_from_relationships(
edge_datas, query_param, text_chunks_db, knowledge_graph_inst
)
......
from nano_vectordb import NanoVectorDB
......
self._client = NanoVectorDB(
self.embedding_func.embedding_dim, storage_file=self._client_file_name
)
......
async def query(self, query: str, top_k=5):
embedding = await self.embedding_func([query])
embedding = embedding[0]
results = self._client.query(
query=embedding,
top_k=top_k,
better_than_threshold=self.cosine_better_than_threshold,
)
results = [
{**dp, "id": dp["__id__"], "distance": dp["__metrics__"]} for dp in results
]
return results
(3)增强高阶关联性:。LightRAG 进一步收集已检索到的实体或关系的局部子图,如实体或关系的一跳邻近节点,数学公式表示如下:

其中 Nv 和 Ne 分别表示检索到的节点 v 和边 e 的单跳相邻节点。
(4)检索到的信息分为三个部分:实体、关系和对应的文本块。然后将这个结构化数据输入到 LLM 中,使其能够为查询生成全面的答案:

评估指标
Win rates
跨越四个数据集和四个评估维度:

引入了一个综合评估框架,用于根据三个关键标准将两个答案与同一问题进行比较:Comprehensiveness、Diversity 和 Empowerment。其目的是通过为每个标准选择更好的答案来指导 LLM,然后进行整体评估。对于这三个标准中的每一个,LLM 必须确定哪些答案表现更好,并为其选择提供理由。最终,整体获胜者是根据所有三个维度的性能确定的,并附有证明决策的详细摘要:

Model cost

(1)索引阶段(Retrieval Phase):
Cmax 表示每个 API 调用允许的最大令牌数。在检索阶段,GraphRAG 生成 1,399 个社区,本实验积极使用 610 个 level-2 社区进行检索。因为 GraphRAG 的 map-reduce 机制,导致总内存消耗为 610,000 个 token(610 个社区 × 每个社区 1,000 个 token)。此外,GraphRAG 单独遍历每个社区的要求会导致数百个 API 调用,显著增加检索开销。相比之下,LightRAG 通过使用少于 100 个标记的关键字生成和检索来优化这个过程,只需要整个过程的单个 API 调用。
(2)更新 KG 阶段(Incremental Text Update):
Textract 表示实体和关系提取的令牌开销,Cextract 表示 extraction 所需的 API 调用数。在增量数据更新阶段,GraphRAG 必须消除其现有的社区结构以合并新的实体和关系,然后进行完全再生。GraphRAG 将需要大约 1399 个社区 × 2 级 level × 每个社区产生约 5,000 个 token 成本来重建原始和新的社区报告。相比之下,LightRAG 无缝地将新提取的实体和关系集成到现有图中,而无需完全重建。
论文解读《LightRAG: Simple and Fast Retrieval-Augmented Generation》的更多相关文章
- 《Population Based Training of Neural Networks》论文解读
很早之前看到这篇文章的时候,觉得这篇文章的思想很朴素,没有让人眼前一亮的东西就没有太在意.之后读到很多Multi-Agent或者并行训练的文章,都会提到这个算法,比如第一视角多人游戏(Quake ...
- ImageNet Classification with Deep Convolutional Neural Networks 论文解读
这个论文应该算是把深度学习应用到图片识别(ILSVRC,ImageNet large-scale Visual Recognition Challenge)上的具有重大意义的一篇文章.因为在之前,人们 ...
- 《Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks》论文笔记
论文题目<Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Ne ...
- Quantization aware training 量化背后的技术——Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
1,概述 模型量化属于模型压缩的范畴,模型压缩的目的旨在降低模型的内存大小,加速模型的推断速度(除了压缩之外,一些模型推断框架也可以通过内存,io,计算等优化来加速推断). 常见的模型压缩算法有:量化 ...
- Training Deep Neural Networks
http://handong1587.github.io/deep_learning/2015/10/09/training-dnn.html //转载于 Training Deep Neural ...
- Training (deep) Neural Networks Part: 1
Training (deep) Neural Networks Part: 1 Nowadays training deep learning models have become extremely ...
- [CVPR2015] Is object localization for free? – Weakly-supervised learning with convolutional neural networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- Training spiking neural networks for reinforcement learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 原文链接:https://arxiv.org/pdf/2005.05941.pdf Contents: Abstract Introduc ...
- CVPR 2018paper: DeepDefense: Training Deep Neural Networks with Improved Robustness第一讲
前言:好久不见了,最近一直瞎忙活,博客好久都没有更新了,表示道歉.希望大家在新的一年中工作顺利,学业进步,共勉! 今天我们介绍深度神经网络的缺点:无论模型有多深,无论是卷积还是RNN,都有的问题:以图 ...
- 论文翻译:BinaryConnect: Training Deep Neural Networks with binary weights during propagations
目录 摘要 1.引言 2.BinaryConnect 2.1 +1 or -1 2.2确定性与随机性二值化 2.3 Propagations vs updates 2.4 Clipping 2.5 A ...
随机推荐
- Spring —— DI入门案例
DI入门案例 思路分析: 1.基于IoC管理bean 2.Service中使用new形式创建的Dao对象是否保留(否) 3.Service中需要的Dao对象如何进入Serv ...
- 我发布了一款相亲平台《i相遇》
因缘际会之下,我踏入了相亲平台的领域.起初,是为一位客户打造专属相亲应用,过程中深入体验了众多同类平台,却遗憾地发现它们普遍掺杂着欺诈的阴影--高昂的费用.兼职托儿的身影.以及虚假的钓鱼信息,不一而足 ...
- 精彩回顾 | Flutter Engage China 视频合集
在上周的 Flutter Engage China 活动中,Google Flutter 团队和来自国内的开发者们共同探讨和交流 Flutter 的最新更新.实践和未来的发展.虽然只能通过线上交流,但 ...
- 一条 SQL 语句在 MySQL 中是如何执行的?
本篇文章会分析下一个 SQL 语句在 MySQL 中的执行流程,包括 SQL 的查询在 MySQL 内部会怎么流转,SQL 语句的更新是怎么完成的. 在分析之前我会先带着你看看 MySQL 的基础架构 ...
- 【Pwn】maze - writrup
1.运行函数,收集字符串 获取关键词字符串:luck 2.寻找字符串引用代码 3.生成伪代码 4.获得main函数的C语言代码 5.分析程序逻辑 check函数: main函数 int __fastc ...
- 来参与Oracle VS openGauss 在线研讨,与盖国强老师、李国良教授面对面!
11月11日下午14点,墨天轮社区邀请到两位数据库领域的巅峰人物:Oracle ACED 盖国强老师,和来自清华大学计算机与技术系的李国良教授,他们将进行一场"巅峰对话". 墨天轮 ...
- Vue3 的 nextTick 函数
作用: DOM 渲染是异步耗时的, vue2.x 需要等到 DOM 渲染完成之后做某个事情,需要使用 this.$nextTick , vue3.x 则直接提供了 nextTick 这个方法去实现 : ...
- Kubernetes 对接 GlusterFS 磁盘扩容实战
前言 知识点 定级:入门级 使用 Heketi Topology 扩容磁盘 使用 Heketi CLI 扩容磁盘 实战服务器配置 (架构 1:1 复刻小规模生产环境,配置略有不同) 主机名 IP CP ...
- insufficient permission for adding an object to repository database .git/objects
1.出错截图: 有时候使用软件项目管理系统github时候,会出现一些问题截图如下: 2.出错原因 从出错的地方就知道是因为权限不足导致,回想一下,在链接远程服务器时候,不小心切换为管理员权限进行了g ...
- 在Ubuntu小设备上使用VSCode+SSH开发部署nicegui的Web应用,并设置系统开机自动启动应用
在一些小的设备上跑Ubuntu系统,需要快速的开发和调整项目的时候,往往使用SSH进行远程的开发测试,这样可以避免传统的打包更新处理,能够快速的在实际环境上测试具体的内容.另外由于系统设备往往需要重启 ...