原子指令,自旋锁,CAS
原子指令,自旋锁,CAS
问题
我们先看一下这段代码:
/*
* badcnt.c - An improperly synchronized counter program
*/
/* $begin badcnt */
/* WARNING: This code is buggy! */
#include "csapp.h"
void *thread(void *vargp); /* Thread routine prototype */
/* Global shared variable */
volatile long cnt = 0; /* Counter */
int main(int argc, char **argv)
{
long niters;
pthread_t tid1, tid2;
niters = 100000;
/* Create threads and wait for them to finish */
Pthread_create(&tid1, NULL, thread, &niters);
Pthread_create(&tid2, NULL, thread, &niters);
Pthread_join(tid1, NULL);
Pthread_join(tid2, NULL);
/* Check result */
if (cnt != (2 * 100000))
printf("BOOM! cnt=%ld\n", cnt);
else
printf("OK cnt=%ld\n", cnt);
exit(0);
}
/* Thread routine */
void *thread(void *vargp)
{
long i, niters = *((long *)vargp);
for (i = 0; i < niters; i++) //line:conc:badcnt:beginloop
cnt++; //line:conc:badcnt:endloop
return NULL;
}
/* $end badcnt */
这段代码创建了两个线程,每个线程都对cnt全局变量执行100000次++操作,所以我们的得到的cnt应该是200000,但是结果却并不是这样:
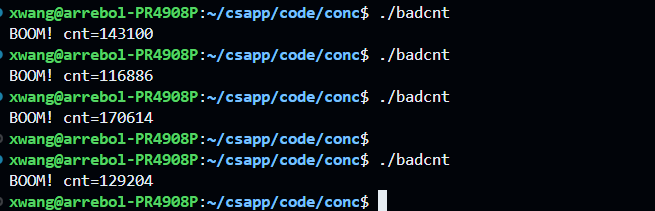
很奇怪啊,两个线程都对cnt执行++操作,怎么比200000要小啊,而且每次结果都不一样。
其实从汇编语言(指令)的角度去理解这个,就能解释这个问题。将cnt++翻译成对应的汇编指令,是这样:
movq cnt(%rip), %rdx // 加载cnt
addq $1, %rdx // 更新cnt
movq %rdx, cnt(%rip) // 写回cnt
我们知道,指令才是cpu上执行的最小单位(可以把一条指令的执行理解成不可中断的),我们可以发现,如果一个进程在更新cnt之后,还没有写回,但是此时另一个进程已经读取了cnt,是不是就出问题了!就比如此时cnt是1,一个进程取出来了进行加1,得到2,但是还没有写回,但是另一个进程此时正在执行第一条指令,这样就出问题了。所以这是导致cnt结果不符合期待的原因。
解决方案
思路1
前面不是说一个++操作被分解为了三条指令吗,如果CPU实现了一个这样的指令:
inc 1, cnt(%rip)
这个指令是在cnt(%rip)上实现加1操作,这样是不是就万事无忧了,但是其实这样也是不行的,因为指令并不是CPU上执行的最小单位,现代处理器CPU会把一个指令分为五个步骤进行执行,取指,译码,访存,执行,写回,这样做是为了实现处理器流水线,加快指令的执行。详见:CSAPP学习笔记——chapter4 处理器体系结构
所以正如下图所示,如果一个前面的inc指令在写回之前,前面已经有指令进行了访存,那么一样会导致错误的结果。
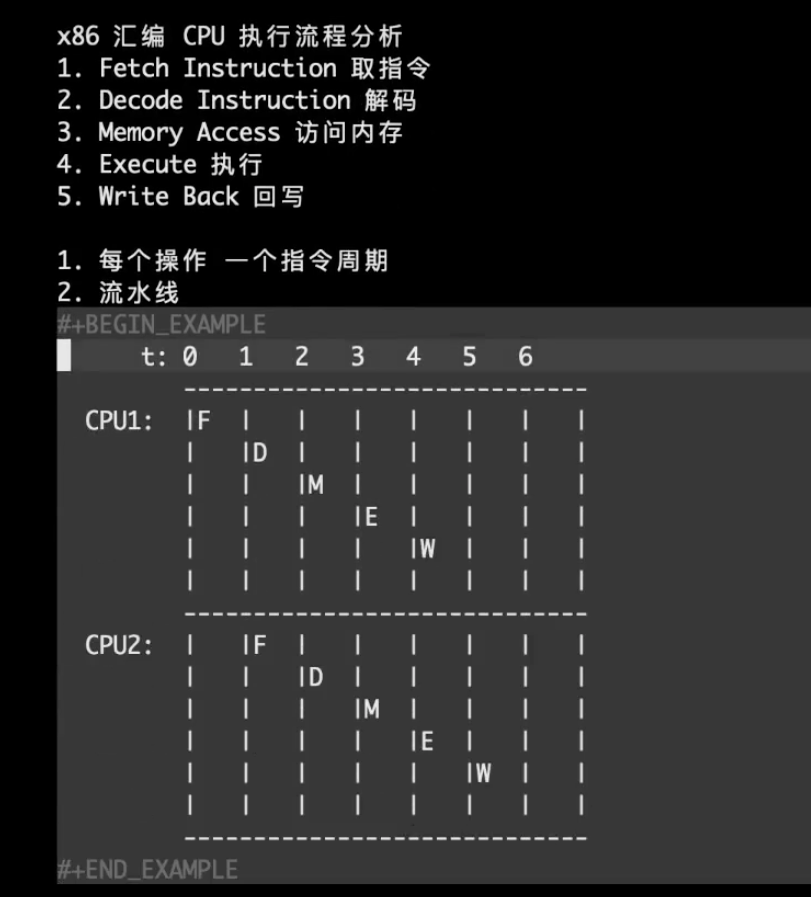
原子指令
C++给我们提供了原子操作: atomic<int> cnt;这个时候对cnt进行算数运算,就是正确的。宏观意义上就是对a进行的操作是原子的,但是atomic的是怎么实现的呢?。其实x86-64处理器提供了一个汇编指令帮助编译器实现atomic。
也就是 CMPXCHG (compare and exchange)(原子指令):
在执行CMPXCHG之前,先在EAX中存储了旧值,
这个指令的功能是这样的:
- 比较:
CMPXCHG首先将目标内存位置的值与 EAX 或 RAX中的旧值进行比较。- 交换:如果目标内存位置的值与寄存器中的值相等(即比较结果为相等),
CMPXCHG会将另一个指定寄存器的值写入目标内存位置。如果不相等,CMPXCHG将目标内存位置的值加载到那个寄存器中。这个指令的基本形式如下:
CMPXCHG 目标位置(与eax比较), source
稍微提一下原子指令在x86 硬件上的实现,大概如下图所示,将下一条指令的读内存给推迟到了上一条指令的写回。所以原子指令会牺牲一定的效率,但是又相较于使用互斥锁效率高,因为没有线程的上下文切换等开销。
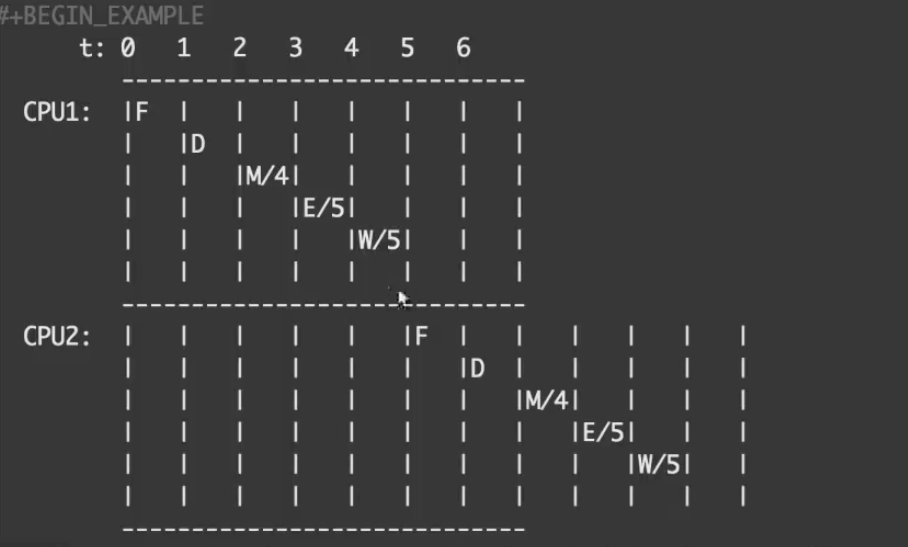
在执行累加之前,首先把cnt的旧值存储到eax中,然后再去读取这个值,并执行运算得到source值,此时就会执行CMPXCHG了,如果旧值和目标位置值相等,就写入,这个写入是不可中断的(应该是CMPXCHG内部的实现),如果不相等,就把目标内存的值加载到eax中的值就会被更新为内存中的新值,再重新执行算数操作,然后重复这个过程。
自旋锁
在xv6上基于原子指令还可以实现自旋锁,核心代码在这里:
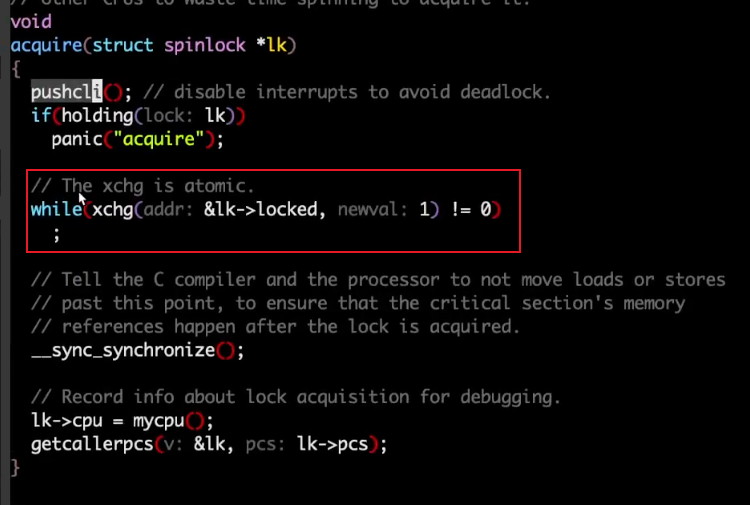
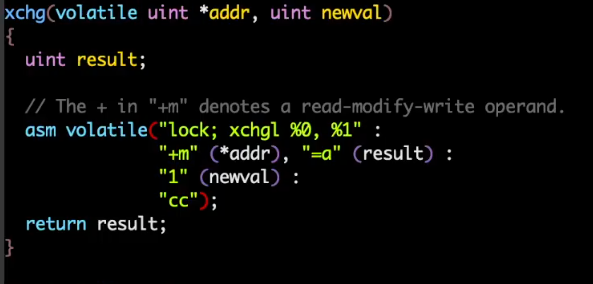
可以看到这里不断的想使用 xchg获取一把锁,将锁的值设为 1,如果写入之前不是 0,就代表获取锁失败了,因此会在这里使用 while 循环一直等待。
可以看到自旋锁也没有涉及线程的阻塞。
refer
原子指令,自旋锁,CAS的更多相关文章
- SpinLock 自旋锁, CAS操作(Compare & Set) ABA Problem
SpinLock 自旋锁 spinlock 用于CPU同步, 它的实现是基于CPU锁定数据总线的指令. 当某个CPU锁住数据总线后, 它读一个内存单元(spinlock_t)来判断这个spinlock ...
- Linux 同步方法剖析--内核原子,自旋锁和相互排斥锁
在学习 Linux® 的过程中,您或许接触过并发(concurrency).临界段(critical section)和锁定,可是怎样在内核中使用这些概念呢?本文讨论了 2.6 版内核中可用的锁定机制 ...
- 第47天打卡学习(单例模式 深入了解CAS 原子引用 各种锁的理解)
18彻底玩转 单例模式 饿汉式 DCL懒汉模式 探究! 饿汉式 package com.kuang.single; //饿汉式单例 //单例模式重要思想是构造器私有 public class Hun ...
- 使用C++11原子量实现自旋锁
一.自旋锁 自旋锁是一种基础的同步原语,用于保障对共享数据的互斥访问.与互斥锁的相比,在获取锁失败的时候不会使得线程阻塞而是一直自旋尝试获取锁.当线程等待自旋锁的时候,CPU不能做其他事情,而是一直处 ...
- JUC 并发编程--05, Volatile关键字特性: 可见性, 不保证原子性,禁止指令重排, 代码证明过程. CAS了解么 , ABA怎么解决, 手写自旋锁和死锁
问: 了解volatile关键字么? 答: 他是java 的关键字, 保证可见性, 不保证原子性, 禁止指令重排 问: 你说的这三个特性, 能写代码证明么? 答: .... 问: 听说过 CAS么 他 ...
- 我们常说的 CAS 自旋锁是什么
CAS(Compare and swap),即比较并交换,也是实现我们平时所说的自旋锁或乐观锁的核心操作. 它的实现很简单,就是用一个预期的值和内存值进行比较,如果两个值相等,就用预期的值替换内存值, ...
- CAS机制与自旋锁
CAS(Compare-and-Swap),即比较并替换,java并发包中许多Atomic的类的底层原理都是CAS. 它的功能是判断内存中某个地址的值是否为预期值,如果是就改变成新值,整个过程具有原子 ...
- synchronized底层实现原理&CAS操作&偏向锁、轻量级锁,重量级锁、自旋锁、自适应自旋锁、锁消除、锁粗化
进入时:monitorenter 每个对象有一个监视器锁(monitor).当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:1 ...
- 并发编程--CAS自旋锁
在前两篇博客中我们介绍了并发编程--volatile应用与原理和并发编程--synchronized的实现原理(二),接下来我们介绍一下CAS自旋锁相关的知识. 一.自旋锁提出的背景 由于在多处理器系 ...
- 多线程之美6一CAS与自旋锁
1.什么是CAS CAS 即 compare and swap 比较并交换, 涉及到三个参数,内存值V, 预期值A, 要更新为的值B, 拿着预期值A与内存值V比较,相等则符合预期,将内存值V更新为B, ...
随机推荐
- ThreeJs-09精通粒子特效
一.初识points与点材质 什么叫做点材质,之前说过所有物体都是有定点的比如一个球体,并且将材质设置为线框模式,这个之前就说过所有mesh物体都是由三角形构成,都是有顶点的 我们也可以创建点物体,电 ...
- Python 代码实现生命之轮Wheel of life
最近看一个生命之轮的视频,让我们珍惜时间,因为一生是有限的.使用Python创建生命倒计时图表,珍惜时间,活在当下. 生命之轮(Wheel of life),这一概念最初由 Success Motiv ...
- Datawhale AI 夏令营-天池Better Synth多模态大模型数据合成挑战赛-task2探索与进阶(更新中)
在大数据.大模型时代,随着大模型发展,互联网数据渐尽且需大量处理标注,为新模型训练高效合成优质数据成为新兴问题."天池 Better Synth - 多模态大模型数据合成挑战赛"应 ...
- 详解AQS五:深入理解共享锁CountDownLatch
CountDownLatch是一个常用的共享锁,其功能相当于一个多线程环境下的倒数门闩.CountDownLatch可以指定一个计数值,在并发环境下由线程进行减一操作,当计数值变为0之后,被await ...
- 一种调试 线段树 / Treap / Splay / 左偏树 / LCT 等树形结构的技巧
前言 如果我们需要观察程序运行过程中,某一个变量.某一个序列的变化情况,你可以在修改的地方打断点 debug,或者直接在需要的地方输出就行了. 但是对于一些树形结构,我们不好将其直观地呈现出来,常常只 ...
- c# 创建快捷方式并添加到开始菜单程序目录
Using the Windows Script Host (make sure to add a reference to the Windows Script Host Object Model, ...
- JVM:方法区、堆
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.6.2
- Sorcerer pg walkthrough Intermediate
nmap ┌──(root㉿kali)-[~/lab] └─# nmap -p- -A 192.168.192.100 Starting Nmap 7.94SVN ( https://nmap.org ...
- Zino pg walkthrough Intermediate
nmap 扫描 发现smba共享文件 ┌──(root㉿kali)-[~] └─# nmap -p- -A 192.168.167.64 Starting Nmap 7.94SVN ( https:/ ...
- GPU虚拟化技术简介:实现高性能图形处理的灵活部署
本文分享自天翼云开发者社区<GPU虚拟化技术简介:实现高性能图形处理的灵活部署>,作者:z****n GPU虚拟化技术是一项重要的创新,通过将物理GPU划分为多个虚拟GPU,实现多用户共享 ...