canal源码分析简介-3
5.0 store模块
1 store模块简介
store模块用于binlog事件的存储 ,目前开源的版本中仅实现了Memory内存模式。官方文档中提到"后续计划增加本地file存储,mixed混合模式”,这句话大家不必当真,从笔者最开始接触canal到现在已经几年了,依然没有动静,好在Memory内存模式已经可以满足绝大部分场景。
store模块目录结构如下,该模块的核心接口为CanalEventStore:
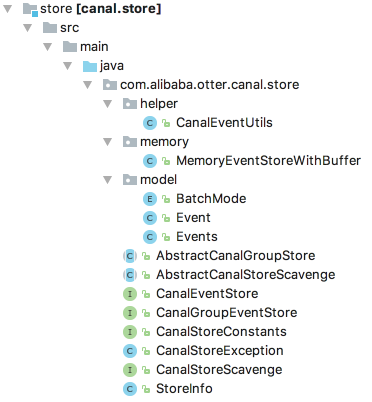
以下是相关类图:
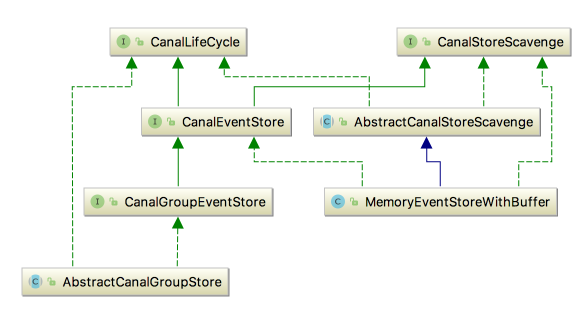
其中MemoryEventStoreWithBuffer就是内存模式的实现,是我们分析的重点,其实现了CanalEventStore接口,并继承了AbstractCanalStoreScavenge抽象类。需要注意的是,AbstractCanalStoreScavenge这个类中定义的字段和方法在开源版本中并没有任何地方使用到,因此我们不会对其进行分析。
MemoryEventStoreWithBuffer的实现借鉴了Disruptor的RingBuffer。简而言之,你可以把其当做一个环形队列,如下:
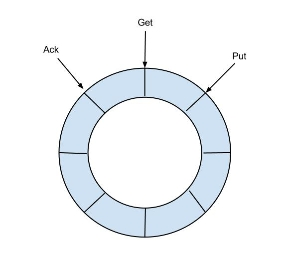
针对这个环形队列,canal定义了3类操作:Put、Get、Ack,其中:
Put 操作:添加数据。event parser模块拉取到binlog后,并经过event sink模块过滤,最终就通过Put操作存储到了队列中。
Get操作:获取数据。canal client连接到canal server后,最终获取到的binlog都是从这个队列中取得。
Ack操作:确认消费成功。canal client获取到binlog事件消费后,需要进行Ack。你可以认为Ack操作实际上就是将消费成功的事件从队列中删除,如果一直不Ack的话,队列满了之后,Put操作就无法添加新的数据了。
对应的,我们需要使用3个变量来记录Put、Get、Ack这三个操作的位置,其中:
putSequence: 每放入一个数据putSequence +1,可表示存储数据存储的总数量
getSequence: 每获取一个数据getSequence +1,可表示数据订阅获取的最后一次提取位置
ackSequence: 每确认一个数据ackSequence + 1,可表示数据最后一次消费成功位置
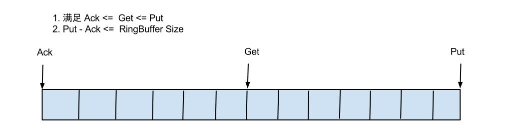
另外,putSequence、getSequence、ackSequence这3个变量初始值都是-1,且都是递增的,均用long型表示。由于数据只有被Put进来后,才能进行Get;Get之后才能进行Ack。 所以,这三个变量满足以下关系:
- ackSequence <= getSequence <= putSequence
如果将RingBuffer拉直来看,将会变得更加直观:
通过对这3个位置进行运算,我们可以得到一些有用的信息,如:
计算当前可消费的event数量:
- 当前可消费的event数量 = putSequence - getSequence
计算当前队列的大小(即队列中还有多少事件等待消费):
- 当前队列的大小 = putSequence - ackSequence
在进行Put/Get/Ack操作时,首先都要确定操作到环形队列的哪个位置。环形队列的bufferSize默认大小是16384,而这3个操作的位置变量putSequence、getSequence、ackSequence都是递增的,显然最终都会超过bufferSize。因此必须要对这3个值进行转换。最简单的操作就是使用%进行取余。
举例来说,putSequence的当前值为16383,这已经是环形队列的最大下标了(从0开始计算),下一个要插入的数据要在第16384个位置上,此时可以使用16384 % bufferSize = 0,因此下一个要插入的数据在0号位置上。可见,当达到队列的最大下标时,再从头开始循环,这也是为什么称之为环形队列的原因。当然在实际操作时,更加复杂,如0号位置上已经有数据了,就不能插入,需要等待这个位置被释放出来,否则出现数据覆盖。
canal使用的是通过位操作进行取余,这种取余方式与%作用完全相同,只不过因为是位操作,因此更加高效。其计算方式如下:
- 操作位置 = sequence & (bufferSize - 1)
需要注意的是,这种方式只对除数是2的N次方幂时才有效,如果对于位运算取余不熟悉,可参考:https://blog.csdn.net/actionzh/article/details/78976082。
在canal.properties文件中定义了几个MemoryEventStoreWithBuffer的配置参数,主要用于控制环形队列的大小和存储的数据可占用的最大内存,如下:
- canal.instance.memory.buffer.size = 16384
- canal.instance.memory.buffer.memunit = 1024
- canal.instance.memory.batch.mode = MEMSIZE
其中:
canal.instance.memory.buffer.size:
表示RingBuffer队列的最大容量,也就是可缓存的binlog事件的最大记录数,其值需要为2的指数(原因如前所述,canal通过位运算进行取余),默认值为2^16=16384。
canal.instance.memory.buffer.memunit:
表示RingBuffer使用的内存单元, 默认是1kb。和canal.instance.memory.buffer.size组合决定最终的内存使用大小。需要注意的是,这个配置项仅仅是用于计算占用总内存,并不是限制每个event最大为1kb。
canal.instance.memory.batch.mode:
表示canal内存store中数据缓存模式,支持两种方式:
ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量。这种方式有一些潜在的问题,举个极端例子,假设每个event有1M,那么16384个这种event占用内存要达到16G左右,基本上肯定会造成内存溢出(超大内存的物理机除外)。
MEMSIZE : 根据buffer.size * buffer.memunit的大小,限制缓存记录占用的总内存大小。指定为这种模式时,意味着默认缓存的event占用的总内存不能超过16384*1024=16M。这个值偏小,但笔者认为也足够了。因为通常我们在一个服务器上会部署多个instance,每个instance的store模块都会占用16M,因此只要instance的数量合适,也就不会浪费内存了。部分读者可能会担心,这是否限制了一个event的最大大小为16M,实际上是没有这个限制的。因为canal在Put一个新的event时,只会判断队列中已有的event占用的内存是否超过16M,如果没有,新的event不论大小是多少,总是可以放入的(canal的内存计算实际上是不精确的),之后的event再要放入时,如果这个超过16M的event没有被消费,则需要进行等待。
在canal自带的instance.xml文件中,使用了这些配置项来创建MemoryEventStoreWithBuffer实例,如下:
- <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer">
- <property name="bufferSize" value="${canal.instance.memory.buffer.size:16384}" />
- <property name="bufferMemUnit" value="${canal.instance.memory.buffer.memunit:1024}" />
- <property name="batchMode" value="${canal.instance.memory.batch.mode:MEMSIZE}" />
- <property name="ddlIsolation" value="${canal.instance.get.ddl.isolation:false}" />
- </bean>
这里我们还看到了一个ddlIsolation属性,其对于Get操作生效,用于设置ddl语句是否单独一个batch返回(比如下游dml/ddl如果做batch内无序并发处理,会导致结构不一致)。其值通过canal.instance.get.ddl.isolation配置项来设置,默认值为false。
2 CanalEventStore接口
通过前面的分析,我们知道了环形队列要支持三种操作:Put、Get、Ack,针对这三种操作,在CanalEventStore中都有相应的方法定义,如下所示:
com.alibaba.otter.canal.store.CanalEventStore
- /**
- * canel数据存储接口
- */
- public interface CanalEventStore<T> extends CanalLifeCycle, CanalStoreScavenge {
- //==========================Put操作==============================
- /**添加一组数据对象,阻塞等待其操作完成 (比如一次性添加一个事务数据)*/
- void put(List<T> data) throws InterruptedException, CanalStoreException;
- /**添加一组数据对象,阻塞等待其操作完成或者时间超时 (比如一次性添加一个事务数据)*/
- boolean put(List<T> data, long timeout, TimeUnit unit) throws InterruptedException,
- CanalStoreException;
- /**添加一组数据对象 (比如一次性添加一个事务数据)*/
- boolean tryPut(List<T> data) throws CanalStoreException;
- /**添加一个数据对象,阻塞等待其操作完成*/
- void put(T data) throws InterruptedException, CanalStoreException;
- /**添加一个数据对象,阻塞等待其操作完成或者时间超时*/
- boolean put(T data, long timeout, TimeUnit unit) throws InterruptedException, CanalStoreException;
- /** 添加一个数据对象*/
- boolean tryPut(T data) throws CanalStoreException;
- //==========================GET操作==============================
- /** 获取指定大小的数据,阻塞等待其操作完成*/
- Events<T> get(Position start, int batchSize) throws InterruptedException, CanalStoreException;
- /**获取指定大小的数据,阻塞等待其操作完成或者时间超时*/
- Events<T> get(Position start, int batchSize, long timeout, TimeUnit unit) throws
- InterruptedException,CanalStoreException;
- /**根据指定位置,获取一个指定大小的数据*/
- Events<T> tryGet(Position start, int batchSize) throws CanalStoreException;
- //=========================Ack操作==============================
- /**删除{@linkplain Position}之前的数据*/
- void ack(Position position) throws CanalStoreException;
- //==========================其他操作==============================
- /** 获取最后一条数据的position*/
- Position getLatestPosition() throws CanalStoreException;
- /**获取第一条数据的position,如果没有数据返回为null*/
- Position getFirstPosition() throws CanalStoreException;
- /**出错时执行回滚操作(未提交ack的所有状态信息重新归位,减少出错时数据全部重来的成本)*/
- void rollback() throws CanalStoreException;
- }
可以看到Put/Get/Ack操作都有多种重载形式,各个方法的作用参考方法注释即可,后文在分析MemoryEventStoreWithBuffer时,将会进行详细的介绍。
这里对 get方法返回的Events对象,进行一下说明:
com.alibaba.otter.canal.store.model.Events
- public class Events<EVENT> implements Serializable {
- private static final long serialVersionUID = -7337454954300706044L;
- private PositionRange positionRange = new PositionRange();
- private List<EVENT> events = new ArrayList<EVENT>();
- //setters getters and toString
- }
可以看到,仅仅是通过一个List维护了一组数据,尽管这里定义的是泛型,但真实放入的数据实际上是Event类型。而PositionRange是protocol模块中的类,描述了这组Event的开始(start)和结束位置(end),显然,start表示List集合中第一个Event的位置,end表示最后一个Event的位置。
Event的定义如下所示 :
com.alibaba.otter.canal.store.model.Event
- public class Event implements Serializable {
- private static final long serialVersionUID = 1333330351758762739L;
- private LogIdentity logIdentity; // 记录数据产生的来源
- private CanalEntry.Entry entry;
- //constructor setters getters and toString
- }
其中:CanalEntry.Entry和LogIdentity也都是protocol模块中的类:
LogIdentity记录这个Event的来源信息mysql地址(sourceAddress)和slaveId。
CanalEntry.Entry封装了binlog事件的数据
3 MemoryEventStoreWithBuffer
MemoryEventStoreWithBuffer是目前开源版本中的CanalEventStore接口的唯一实现,基于内存模式。当然你也可以进行扩展,提供一个基于本地文件存储方式的CanalEventStore实现。这样就可以一份数据让多个业务费进行订阅,只要独立维护消费位置元数据即可。然而,我不得不提醒你的是,基于本地文件的存储方式,一定要考虑好数据清理工作,否则会有大坑。
如果一个库只有一个业务方订阅,其实根本也不用实现本地存储,使用基于内存模式的队列进行缓存即可。如果client消费的快,那么队列中的数据放入后就被取走,队列基本上一直是空的,实现本地存储也没意义;如果client消费的慢,队列基本上一直是满的,只要client来获取,总是能拿到数据,因此也没有必要实现本地存储。
言归正传,下面对MemoryEventStoreWithBuffer的源码进行分析。
3.1 MemoryEventStoreWithBuffer字段
首先对MemoryEventStoreWithBuffer中定义的字段进行一下介绍,这是后面分析其他方法的基础,如下:
- public class MemoryEventStoreWithBuffer extends AbstractCanalStoreScavenge implements
- CanalEventStore<Event>, CanalStoreScavenge {
- private static final long INIT_SQEUENCE = -1;
- private int bufferSize = 16 * 1024;
- // memsize的单位,默认为1kb大小
- private int bufferMemUnit = 1024;
- private int indexMask;
- private Event[] entries;
- // 记录下put/get/ack操作的三个下标,初始值都是-1
- // 代表当前put操作最后一次写操作发生的位置
- private AtomicLong putSequence = new AtomicLong(INIT_SQEUENCE);
- // 代表当前get操作读取的最后一条的位置
- private AtomicLong getSequence = new AtomicLong(INIT_SQEUENCE);
- // 代表当前ack操作的最后一条的位置
- private AtomicLong ackSequence = new AtomicLong(INIT_SQEUENCE);
- // 记录下put/get/ack操作的三个memsize大小
- private AtomicLong putMemSize = new AtomicLong(0);
- private AtomicLong getMemSize = new AtomicLong(0);
- private AtomicLong ackMemSize = new AtomicLong(0);
- // 阻塞put/get操作控制信号
- private ReentrantLock lock = new ReentrantLock();
- private Condition notFull = lock.newCondition();
- private Condition notEmpty = lock.newCondition();
- // 默认为内存大小模式
- private BatchMode batchMode = BatchMode.ITEMSIZE;
- private boolean ddlIsolation = false;
- ...
- }
属性说明:
bufferSize、bufferMemUnit、batchMode、ddlIsolation、putSequence、getSequence、ackSequence:
这几个属性前面已经介绍过,这里不再赘述。
entries:
类型为Event[]数组,环形队列底层基于的Event[]数组,队列的大小就是bufferSize。关于如何使用数组来实现环形队列,可参考笔者的另一篇文章http://www.tianshouzhi.com/api/tutorials/basicalgorithm/43。
indexMask
用于对putSequence、getSequence、ackSequence进行取余操作,前面已经介绍过canal通过位操作进行取余,其值为bufferSize-1 ,参见下文的start方法
putMemSize、getMemSize、ackMemSize:
分别用于记录put/get/ack操作的event占用内存的累加值,都是从0开始计算。例如每put一个event,putMemSize就要增加这个event占用的内存大小;get和ack操作也是类似。这三个变量,都是在batchMode指定为MEMSIZE的情况下,才会发生作用。
因为都是累加值,所以我们需要进行一些运算,才能得有有用的信息,如:
计算出当前环形队列当前占用的内存大小
- 环形队列当前占用的内存大小 = putMemSize - ackMemSize
前面我们提到,batchMode为MEMSIZE时,需要限制环形队列中event占用的总内存,事实上在执行put操作前,就是通过这种方式计算出来当前大小,然后我们限制的bufferSize * bufferMemUnit大小进行比较。
计算尚未被获取的事件占用的内存大小
- 尚未被获取的事件占用的内存大小 = putMemSize - getMemSize
batchMode除了对PUT操作有限制,对Get操作也有影响。Get操作可以指定一个batchSize,用于指定批量获取的大小。当batchMode为MEMSIZE时,其含义就在不再是记录数,而是要获取到总共占用 batchSize * bufferMemUnit 内存大小的事件数量。
lock、notFull、notEmpty:
阻塞put/get操作控制信号。notFull用于控制put操作,只有队列没满的情况下才能put。notEmpty控制get操作,只有队列不为空的情况下,才能get。put操作和get操作共用一把锁(lock)。
3.2 启动和停止方法
MemoryEventStoreWithBuffer实现了CanalLifeCycle接口,因此实现了其定义的start、stop方法
start启动方法
start方法主要是初始化MemoryEventStoreWithBuffer内部的环形队列,其实就是初始化一下Event[]数组。
- public void start() throws CanalStoreException {
- super.start();
- if (Integer.bitCount(bufferSize) != 1) {
- throw new IllegalArgumentException("bufferSize must be a power of 2");
- }
- indexMask = bufferSize - 1;//初始化indexMask,前面已经介绍过,用于通过位操作进行取余
- entries = new Event[bufferSize];//创建循环队列基于的底层数组,大小为bufferSize
- }
stop停止方法
stop方法作用是停止,在停止时会清空所有缓存的数据,将维护的相关状态变量设置为初始值。
MemoryEventStoreWithBuffer#stop
- public void stop() throws CanalStoreException {
- super.stop();
- //清空所有缓存的数据,将维护的相关状态变量设置为初始值
- cleanAll();
- }
在停止时,通过调用cleanAll方法清空所有缓存的数据。
cleanAll方法是在CanalStoreScavenge接口中定义的,在MemoryEventStoreWithBuffer中进行了实现, 此外这个接口还定义了另外一个方法cleanUtil,在执行ack操作时会被调用,我们将在介绍ack方法时进行讲解。
MemoryEventStoreWithBuffer#cleanAll
- public void cleanAll() throws CanalStoreException {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- //将Put/Get/Ack三个操作的位置都重置为初始状态-1
- putSequence.set(INIT_SQEUENCE);
- getSequence.set(INIT_SQEUENCE);
- ackSequence.set(INIT_SQEUENCE);
- //将Put/Get/Ack三个操作的memSize都重置为0
- putMemSize.set(0);
- getMemSize.set(0);
- ackMemSize.set(0);
- //将底层Event[]数组置为null,相当于清空所有数据
- entries = null;
- } finally {
- lock.unlock();
- }
- }
4.2 Put操作
前面分析CanalEventStore接口中,我们看到总共有6个put方法,可以分为3类:
不带timeout超时参数的put方法,会一直进行阻塞,直到有足够的空间可以放入。
带timeout参数超时参数的put方法,如果超过指定时间还未put成功,会抛出InterruptedException。
tryPut方法每次只是尝试放入数据,立即返回true或者false,不会阻塞。
事实上,这些方法只是超时机制不同,底层都是通过调用doPut方法来完成真正的数据放入。因此在后面的分析中,笔者只选择其中一种进行讲解。
所有的put操作,在放入数据之前,都需要进行一些前置检查工作,主要检查2点:
1、检查是否足够的slot
默认的bufferSize设置大小为16384,即有16384个slot,每个slot可以存储一个event,因此canal默认最多缓存16384个event。从来另一个角度出发,这意味着putSequence最多比ackSequence可以大16384,不能超过这个值。如果超过了,就意味着尚未没有被消费的数据被覆盖了,相当于丢失了数据。因此,如果Put操作满足以下条件时,是不能新加入数据的
- (putSequence + need_put_events_size)- ackSequence > bufferSize
"putSequence + need_put_events_size"的结果为添加数据后的putSequence的最终位置值,要把这个作为预判断条件,其减去ackSequence,如果大于bufferSize,则不能插入数据。需要等待有足够的空间,或者抛出异常。
2、检测是否超出了内存限制
前面我们已经看到了,为了控制队列中event占用的总内存大小,可以指定batchMode为MEMSIZE。在这种情况下,buffer.size * buffer.memunit(默认为16M)就表示环形队列存储的event总共可以占用的内存大小。因此当出现以下情况下, 不能加入新的event:
- (putMemSize - ackMemSize) > buffer.size * buffer.memunit
关于putMemSize和ackMemSize前面已经介绍过,二者的差值,实际上就是"队列当前包含的event占用的总内存”。
下面我们选择可以指定timeout超时时间的put方法进行讲解,如下:
- public boolean put(List<Event> data, long timeout, TimeUnit unit) throws InterruptedException,
- CanalStoreException {
- //1 如果需要插入的List为空,直接返回true
- if (data == null || data.isEmpty()) {
- return true;
- }
- //2 获得超时时间,并通过加锁进行put操作
- long nanos = unit.toNanos(timeout);
- final ReentrantLock lock = this.lock;
- lock.lockInterruptibly();
- try {
- for (;;) {//这是一个死循环,执行到下面任意一个return或者抛出异常是时才会停止
- //3 检查是否满足插入条件,如果满足,进入到3.1,否则进入到3.2
- if (checkFreeSlotAt(putSequence.get() + data.size())) {
- //3.1 如果满足条件,调用doPut方法进行真正的插入
- doPut(data);
- return true;
- }
- //3.2 判断是否已经超时,如果超时,则不执行插入操作,直接返回false
- if (nanos <= 0) {
- return false;
- }
- //3.3 如果还没有超时,调用notFull.awaitNanos进行等待,需要其他线程调用notFull.signal()方法唤醒。
- //唤醒是在ack操作中进行的,ack操作会删除已经消费成功的event,此时队列有了空间,因此可以唤醒,详见ack方法分析
- //当被唤醒后,因为这是一个死循环,所以循环中的代码会重复执行。当插入条件满足时,调用doPut方法插入,然后返回
- try {
- nanos = notFull.awaitNanos(nanos);
- //3.4 如果一直等待到超时,都没有可用空间可以插入,notFull.awaitNanos会抛出InterruptedException
- } catch (InterruptedException ie) {
- notFull.signal(); //3.5 超时之后,唤醒一个其他执行put操作且未被中断的线程(不明白是为了干啥)
- throw ie;
- }
- }
- } finally {
- lock.unlock();
- }
- }
上述方法的第3步,通过调用checkFreeSlotAt方法来执行插入数据前的检查工作,所做的事情就是我们前面提到的2点:1、检查是否足够的slot 2、检测是否超出了内存限制,源码如下所示:
MemoryEventStoreWithBuffer#checkFreeSlotAt
- /**查询是否有空位*/
- private boolean checkFreeSlotAt(final long sequence) {
- //1、检查是否足够的slot。注意方法参数传入的sequence值是:当前putSequence值 + 新插入的event的记录数。
- //按照前面的说明,其减去bufferSize不能大于ack位置,或者换一种说法,减去bufferSize不能大于ack位置。
- //1.1 首先用sequence值减去bufferSize
- final long wrapPoint = sequence - bufferSize;
- //1.2 获取get位置ack位置的较小值,事实上,ack位置总是应该小于等于get位置,因此这里总是应该返回的是ack位置。
- final long minPoint = getMinimumGetOrAck();
- //1.3 将1.1 与1.2步得到的值进行比较,如果前者大,说明二者差值已经超过了bufferSize,不能插入数据,返回false
- if (wrapPoint > minPoint) { // 刚好追上一轮
- return false;
- } else {
- //2 如果batchMode是MEMSIZE,继续检查是否超出了内存限制。
- if (batchMode.isMemSize()) {
- //2.1 使用putMemSize值减去ackMemSize值,得到当前保存的event事件占用的总内存
- final long memsize = putMemSize.get() - ackMemSize.get();
- //2.2 如果没有超出bufferSize * bufferMemUnit内存限制,返回true,否则返回false
- if (memsize < bufferSize * bufferMemUnit) {
- return true;
- } else {
- return false;
- }
- } else {
- //3 如果batchMode不是MEMSIZE,说明只限制记录数,则直接返回true
- return true;
- }
- }
- }
getMinimumGetOrAck方法用于返回getSequence和ackSequence二者的较小值,源码如下所示:
MemoryEventStoreWithBuffer#getMinimumGetOrAck
- private long getMinimumGetOrAck() {
- long get = getSequence.get();
- long ack = ackSequence.get();
- return ack <= get ? ack : get;
- }
如前所述,ackSequence总是应该小于等于getSequence,因此这里判断应该是没有必要的,笔者已经给官方提了issue,也得到了确认,参见:https://github.com/alibaba/canal/issues/966。
当checkFreeSlotAt方法检验通过后,最终调用的是doPut方法进行插入。doPut方法主要有4个步骤:
1、将新插入的event数据赋值到Event[]数组的正确位置上,就算完成了插入
2、当新插入的event记录数累加到putSequence上
3、累加新插入的event的大小到putMemSize上
4、调用notEmpty.signal()方法,通知队列中有数据了,如果之前有client获取数据处于阻塞状态,将会被唤醒
MemoryEventStoreWithBuffer#doPut
- /*** 执行具体的put操作*/
- private void doPut(List<Event> data) {
- //1 将新插入的event数据赋值到Event[]数组的正确位置上
- //1.1 获得putSequence的当前值current,和插入数据后的putSequence结束值end
- long current = putSequence.get();
- long end = current + data.size();
- //1.2 循环需要插入的数据,从current位置开始,到end位置结束
- for (long next = current + 1; next <= end; next++) {
- //1.3 通过getIndex方法对next变量转换成正确的位置,设置到Event[]数组中
- //需要转换的原因在于,这里的Event[]数组是环形队列的底层实现,其大小为bufferSize值,默认为16384。
- //运行一段时间后,接收到的binlog数量肯定会超过16384,每接受到一个event,putSequence+1,因此最终必然超过这个值。
- //而next变量是比当前putSequence值要大的,因此必须进行转换,否则会数组越界,转换工作就是在getIndex方法中进行的。
- entries[getIndex(next)] = data.get((int) (next - current - 1));
- }
- //2 直接设置putSequence为end值,相当于完成event记录数的累加
- putSequence.set(end);
- //3 累加新插入的event的大小到putMemSize上
- if (batchMode.isMemSize()) {
- //用于记录本次插入的event记录的大小
- long size = 0;
- //循环每一个event
- for (Event event : data) {
- //通过calculateSize方法计算每个event的大小,并累加到size变量上
- size += calculateSize(event);
- }
- //将size变量的值,添加到当前putMemSize
- putMemSize.getAndAdd(size);
- }
- // 4 调用notEmpty.signal()方法,通知队列中有数据了,如果之前有client获取数据处于阻塞状态,将会被唤醒
- notEmpty.signal();
- }
上述代码中,通过getIndex方法方法来进行位置转换,其内部通过位运算来快速取余数,不再赘述
MemoryEventStoreWithBuffer#getIndex
- private int getIndex(long sequcnce) {
- return (int) sequcnce & indexMask; //bufferSize-1
- }
对于batchMode是MEMSIZE的情况下, 还会通过calculateSize方法计算每个event占用的内存大小,累加到putMemSize上。
MemoryEventStoreWithBuffer#calculateSize
- private long calculateSize(Event event) {
- // 直接返回binlog中的事件大小
- return event.getEntry().getHeader().getEventLength();
- }
其原理在于,mysql的binlog的event header中,都有一个event_length表示这个event占用的字节数。不熟悉mysql binlog event结构的读者可参考:https://dev.mysql.com/doc/internals/en/event-structure.html
parser模块将二进制形式binlog event解析后,这个event_length字段的值也被解析出来了,转换成Event对象后,在存储到store模块时,就可以根据其值判断占用内存大小。
需要注意的是,这个计算并不精确。原始的event_length表示的是event是二进制字节流时的字节数,在转换成java对象后,基本上都会变大。如何获取java对象的真实大小,可参考这个博客:https://www.cnblogs.com/Kidezyq/p/8030098.html。
4.3 Get操作
Put操作是canal parser模块解析binlog事件,并经过sink模块过滤后,放入到store模块中,也就是说Put操作实际上是canal内部调用。 Get操作(以及ack、rollback)则不同,其是由client发起的网络请求,server端通过对请求参数进行解析,最终调用CanalEventStore模块中定义的对应方法。
Get操作用于获取指定batchSize大小的Events。提供了3个方法:
- // 尝试获取,如果获取不到立即返回
- public Events<Event> tryGet(Position start, int batchSize) throws CanalStoreException
- // 获取指定大小的数据,阻塞等待其操作完成
- public Events<Event> get(Position start, int batchSize) throws InterruptedException, CanalStoreException
- // 获取指定大小的数据,阻塞等待其操作完成或者超时,如果超时了,有多少,返回多少
- public Events<Event> get(Position start, int batchSize, long timeout, TimeUnit unit)
- throws InterruptedException,CanalStoreException
其中:
start参数:其类型为Posisiton,表示从哪个位置开始获取
batchSize参数:表示批量获取的大小
timeout和uint参数:超时参数配置
与Put操作类似,MemoryEventStoreWithBuffer在实现这三个方法时,真正的获取操作都是在doGet方法中进行的。这里我们依然只选择其中一种进行完整的讲解:
- public Events<Event> get(Position start, int batchSize, long timeout, TimeUnit unit)
- throws InterruptedException,CanalStoreException {
- long nanos = unit.toNanos(timeout);
- final ReentrantLock lock = this.lock;
- lock.lockInterruptibly();
- try {
- for (;;) {
- if (checkUnGetSlotAt((LogPosition) start, batchSize)) {
- return doGet(start, batchSize);
- }
- if (nanos <= 0) {
- // 如果时间到了,有多少取多少
- return doGet(start, batchSize);
- }
- try {
- nanos = notEmpty.awaitNanos(nanos);
- } catch (InterruptedException ie) {
- notEmpty.signal(); // propagate to non-interrupted thread
- throw ie;
- }
- }
- } finally {
- lock.unlock();
- }
- }
可以看到,get方法的实现逻辑与put方法整体上是类似的,不再赘述。这里我们直接关注checkUnGetSlotAt和doGet方法。
checkUnGetSlotAt方法,用于检查是否有足够的event可供获取,根据batchMode的不同,有着不同的判断逻辑
如果batchMode为ITEMSIZE,则表示只要有有满足batchSize数量的记录数即可,即putSequence - getSequence >= batchSize
如果batchMode为MEMSIZE,此时batchSize不再表示记录数,而是bufferMemUnit的个数,也就是说,获取到的event列表占用的总内存要达到batchSize * bufferMemUnit,即putMemSize-getMemSize >= batchSize * bufferMemUnit
MemoryEventStoreWithBuffer#checkUnGetSlotAt
- private boolean checkUnGetSlotAt(LogPosition startPosition, int batchSize) {
- //1 如果batchMode为ITEMSIZE
- if (batchMode.isItemSize()) {
- long current = getSequence.get();
- long maxAbleSequence = putSequence.get();
- long next = current;
- //1.1 第一次订阅之后,需要包含一下start位置,防止丢失第一条记录。
- if (startPosition == null || !startPosition.getPostion().isIncluded()) {
- next = next + 1;
- }
- //1.2 理论上只需要满足条件:putSequence - getSequence >= batchSize
- //1.2.1 先通过current < maxAbleSequence进行一下简单判断,如果不满足,可以直接返回false了
- //1.2.2 如果1.2.1满足,再通过putSequence - getSequence >= batchSize判断是否有足够的数据
- if (current < maxAbleSequence && next + batchSize - 1 <= maxAbleSequence) {
- return true;
- } else {
- return false;
- }
- //2 如果batchMode为MEMSIZE
- } else {
- long currentSize = getMemSize.get();
- long maxAbleSize = putMemSize.get();
- //2.1 需要满足条件 putMemSize-getMemSize >= batchSize * bufferMemUnit
- if (maxAbleSize - currentSize >= batchSize * bufferMemUnit) {
- return true;
- } else {
- return false;
- }
- }
- }
关于1.1步的描述"第一次订阅之后,需要包含一下start位置,防止丢失第一条记录”,这里进行一下特殊说明。首先要明确checkUnGetSlotAt方法的startPosition参数到底是从哪里传递过来的。
当一个client在获取数据时,CanalServerWithEmbedded的getWithoutAck/或get方法会被调用。其内部首先通过CanalMetaManager查找client的消费位置信息,由于是第一次,肯定没有记录,因此返回null,此时会调用CanalEventStore的getFirstPosition()方法,尝试把第一条数据作为消费的开始。而此时CanalEventStore中可能有数据,也可能没有数据。在没有数据的情况下,依然返回null;在有数据的情况下,把第一个Event的位置作为消费开始位置。那么显然,传入checkUnGetSlotAt方法的startPosition参数可能是null,也可能不是null。所以有了以下处理逻辑:
- if (startPosition == null || !startPosition.getPostion().isIncluded()) {
- next = next + 1;
- }
如果不是null的情况下,尽管把第一个event当做开始位置,但是因为这个event毕竟还没有消费,所以在消费的时候我们必须也将其包含进去。之所以要+1,因为是第一次获取,getSequence的值肯定还是初始值-1,所以要+1变成0之后才是队列的第一个event位置。关于CanalEventStore的getFirstPosition()方法,我们将在最后分析。
当通过checkUnGetSlotAt的检查条件后,通过doGet方法进行真正的数据获取操作,获取主要分为5个步骤:
1、确定从哪个位置开始获取数据
2、根据batchMode是MEMSIZE还是ITEMSIZE,通过不同的方式来获取数据
3、设置PositionRange,表示获取到的event列表开始和结束位置
4、设置ack点
5、累加getSequence,getMemSize值
MemoryEventStoreWithBuffer#doGet
- private Events<Event> doGet(Position start, int batchSize) throws CanalStoreException {
- LogPosition startPosition = (LogPosition) start;
- //1 确定从哪个位置开始获取数据
- //获得当前的get位置
- long current = getSequence.get();
- //获得当前的put位置
- long maxAbleSequence = putSequence.get();
- //要获取的第一个Event的位置,一开始等于当前get位置
- long next = current;
- //要获取的最后一个event的位置,一开始也是当前get位置,每获取一个event,end值加1,最大为current+batchSize
- //因为可能进行ddl隔离,因此可能没有获取到batchSize个event就返回了,此时end值就会小于current+batchSize
- long end = current;
- // 如果startPosition为null,说明是第一次订阅,默认+1处理,因为getSequence的值是从-1开始的
- // 如果tartPosition不为null,需要包含一下start位置,防止丢失第一条记录
- if (startPosition == null || !startPosition.getPostion().isIncluded()) {
- next = next + 1;
- }
- // 如果没有数据,直接返回一个空列表
- if (current >= maxAbleSequence) {
- return new Events<Event>();
- }
- //2 如果有数据,根据batchMode是ITEMSIZE或MEMSIZE选择不同的处理方式
- Events<Event> result = new Events<Event>();
- //维护要返回的Event列表
- List<Event> entrys = result.getEvents();
- long memsize = 0;
- //2.1 如果batchMode是ITEMSIZE
- if (batchMode.isItemSize()) {
- end = (next + batchSize - 1) < maxAbleSequence ? (next + batchSize - 1) : maxAbleSequence;
- //2.1.1 循环从开始位置(next)到结束位置(end),每次循环next+1
- for (; next <= end; next++) {
- //2.1.2 获取指定位置上的事件
- Event event = entries[getIndex(next)];
- //2.1.3 果是当前事件是DDL事件,且开启了ddl隔离,本次事件处理完后,即结束循环(if语句最后是一行是break)
- if (ddlIsolation && isDdl(event.getEntry().getHeader().getEventType())) {
- // 2.1.4 因为ddl事件需要单独返回,因此需要判断entrys中是否应添加了其他事件
- if (entrys.size() == 0) {//如果entrys中尚未添加任何其他event
- entrys.add(event);//加入当前的DDL事件
- end = next; // 更新end为当前值
- } else {
- //如果已经添加了其他事件 如果之前已经有DML事件,直接返回了,因为不包含当前next这记录,需要回退一个位置
- end = next - 1; // next-1一定大于current,不需要判断
- }
- break;
- } else {//如果没有开启DDL隔离,直接将事件加入到entrys中
- entrys.add(event);
- }
- }
- //2.2 如果batchMode是MEMSIZE
- } else {
- //2.2.1 计算本次要获取的event占用最大字节数
- long maxMemSize = batchSize * bufferMemUnit;
- //2.2.2 memsize从0开始,当memsize小于maxMemSize且next未超过maxAbleSequence时,可以进行循环
- for (; memsize <= maxMemSize && next <= maxAbleSequence; next++) {
- //2.2.3 获取指定位置上的Event
- Event event = entries[getIndex(next)];
- //2.2.4 果是当前事件是DDL事件,且开启了ddl隔离,本次事件处理完后,即结束循环(if语句最后是一行是break)
- if (ddlIsolation && isDdl(event.getEntry().getHeader().getEventType())) {
- // 如果是ddl隔离,直接返回
- if (entrys.size() == 0) {
- entrys.add(event);// 如果没有DML事件,加入当前的DDL事件
- end = next; // 更新end为当前
- } else {
- // 如果之前已经有DML事件,直接返回了,因为不包含当前next这记录,需要回退一个位置
- end = next - 1; // next-1一定大于current,不需要判断
- }
- break;
- } else {
- //如果没有开启DDL隔离,直接将事件加入到entrys中
- entrys.add(event);
- //并将当前添加的event占用字节数累加到memsize变量上
- memsize += calculateSize(event);
- end = next;// 记录end位点
- }
- }
- }
- //3 构造PositionRange,表示本次获取的Event的开始和结束位置
- PositionRange<LogPosition> range = new PositionRange<LogPosition>();
- result.setPositionRange(range);
- //3.1 把entrys列表中的第一个event的位置,当做PositionRange的开始位置
- range.setStart(CanalEventUtils.createPosition(entrys.get(0)));
- //3.2 把entrys列表中的最后一个event的位置,当做PositionRange的结束位置
- range.setEnd(CanalEventUtils.createPosition(entrys.get(result.getEvents().size() - 1)));
- //4 记录一下是否存在可以被ack的点,逆序迭代获取到的Event列表
- for (int i = entrys.size() - 1; i >= 0; i--) {
- Event event = entrys.get(i);
- //4.1.1 如果是事务开始/事务结束/或者dll事件,
- if (CanalEntry.EntryType.TRANSACTIONBEGIN == event.getEntry().getEntryType()
- || CanalEntry.EntryType.TRANSACTIONEND == event.getEntry().getEntryType()
- || isDdl(event.getEntry().getHeader().getEventType())) {
- // 4.1.2 将其设置为可被ack的点,并跳出循环
- range.setAck(CanalEventUtils.createPosition(event));
- break;
- }
- //4.1.3 如果没有这三种类型事件,意味着没有可被ack的点
- }
- //5 累加getMemSize值,getMemSize值
- //5.1 通过AtomLong的compareAndSet尝试增加getSequence值
- if (getSequence.compareAndSet(current, end)) {//如果成功,累加getMemSize
- getMemSize.addAndGet(memsize);
- //如果之前有put操作因为队列满了而被阻塞,这里发送信号,通知队列已经有空位置,下面还要进行说明
- notFull.signal();
- return result;
- } else {//如果失败,直接返回空事件列表
- return new Events<Event>();
- }
- }
补充说明:
1 Get数据时,会通过isDdl方法判断event是否是ddl类型。
MemoryEventStoreWithBuffer#isDdl
- private boolean isDdl(EventType type) {
- return type == EventType.ALTER || type == EventType.CREATE || type == EventType.ERASE
- || type == EventType.RENAME || type == EventType.TRUNCATE || type == EventType.CINDEX
- || type == EventType.DINDEX;
- }
这里的EventType是在protocol模块中定义的,并非mysql binlog event结构中的event type。在原始的mysql binlog event类型中,有一个QueryEvent,里面记录的是执行的sql语句,canal通过对这个sql语句进行正则表达式匹配,判断出这个event是否是DDL语句(参见SimpleDdlParser#parse方法)。
2 获取到event列表之后,会构造一个PostionRange对象。
通过CanalEventUtils.createPosition方法计算出第一、最后一个event的位置,作为PostionRange的开始和结束。
事实上,parser模块解析后,已经将位置信息:binlog文件,position封装到了Event中,createPosition方法只是将这些信息提取出来。
CanalEventUtils#createPosition
- public static LogPosition createPosition(Event event) {
- //=============创建一个EntryPosition实例,提取event中的位置信息============
- EntryPosition position = new EntryPosition();
- //event所在的binlog文件
- position.setJournalName(event.getEntry().getHeader().getLogfileName());
- //event锁在binlog文件中的位置
- position.setPosition(event.getEntry().getHeader().getLogfileOffset());
- //event的创建时间
- position.setTimestamp(event.getEntry().getHeader().getExecuteTime());
- //event是mysql主从集群哪一个实例上生成的,一般都是主库,如果从库没有配置read-only,那么serverId也可能是从库
- position.setServerId(event.getEntry().getHeader().getServerId());
- //===========将EntryPosition实例封装到一个LogPosition对象中===============
- LogPosition logPosition = new LogPosition();
- logPosition.setPostion(position);
- //LogIdentity中包含了这个event来源的mysql实力的ip地址信息
- logPosition.setIdentity(event.getLogIdentity());
- return logPosition;
- }
3 获取到Event列表后,会从中逆序寻找第一个类型为"事务开始/事务结束/DDL"的Event,将其位置作为PostionRange的可ack位置。
mysql原生的binlog事件中,总是以一个内容”BEGIN”的QueryEvent作为事务开始,以XidEvent事件表示事务结束。即使我们没有显式的开启事务,对于单独的一个更新语句(如Insert、update、delete),mysql也会默认开启事务。而canal将其转换成更容易理解的自定义EventType类型:TRANSACTIONBEGIN、TRANSACTIONEND。
而将这些事件作为ack点,主要是为了保证事务的完整性。例如client一次拉取了10个binlog event,前5个构成一个事务,后5个还不足以构成一个完整事务。在ack后,如果这个client停止了,也就是说下一个事务还没有被完整处理完。尽管之前ack的是10条数据,但是client重新启动后,将从第6个event开始消费,而不是从第11个event开始消费,因为第6个event是下一个事务的开始。
具体逻辑在于,canal server在接受到client ack后,CanalServerWithEmbedded#ack方法会执行。其内部首先根据ack的batchId找到对应的PositionRange,再找出其中的ack点,通过CanalMetaManager将这个位置记录下来。之后client重启后,再把这个位置信息取出来,从这个位置开始消费。
也就是说,ack位置实际上提供给CanalMetaManager使用的。而对于MemoryEventStoreWithBuffer本身而言,也需要进行ack,用于将已经消费的数据从队列中清除,从而腾出更多的空间存放新的数据。
4.4 ack操作
相对于get操作和put操作,ack操作没有重载,只有一个ack方法,用于清空指定position之前的数据,如下:
MemoryEventStoreWithBuffer#ack
- public void ack(Position position) throws CanalStoreException {
- cleanUntil(position);
- }
CanalStoreScavenge接口定义了2个方法:cleanAll和cleanUntil。前面我们已经看到了在stop时,cleanAll方法会被执行。而每次ack时,cleanUntil方法会被执行,这个方法实现如下所示:
MemoryEventStoreWithBuffer#cleanUntil
- // postion表示要ack的配置
- public void cleanUntil(Position position) throws CanalStoreException {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- //获得当前ack值
- long sequence = ackSequence.get();
- //获得当前get值
- long maxSequence = getSequence.get();
- boolean hasMatch = false;
- long memsize = 0;
- //迭代所有未被ack的event,从中找出与需要ack的position相同位置的event,清空这个event之前的所有数据。
- //一旦找到这个event,循环结束。
- for (long next = sequence + 1; next <= maxSequence; next++) {
- Event event = entries[getIndex(next)];//获得要ack的event
- memsize += calculateSize(event);//计算当前要ack的event占用字节数
- boolean match = CanalEventUtils.checkPosition(event, (LogPosition) position);
- if (match) {// 找到对应的position,更新ack seq
- hasMatch = true;
- if (batchMode.isMemSize()) {//如果batchMode是MEMSIZE
- ackMemSize.addAndGet(memsize);//累加ackMemSize
- // 尝试清空buffer中的内存,将ack之前的内存全部释放掉
- for (long index = sequence + 1; index < next; index++) {
- entries[getIndex(index)] = null;// 设置为null
- }
- }
- //累加ack值
- //官方注释说,采用compareAndSet,是为了避免并发ack。我觉得根本不会并发ack,因为都加锁了
- if (ackSequence.compareAndSet(sequence, next)) {
- notFull.signal();//如果之前存在put操作因为队列满了而被阻塞,通知其队列有了新空间
- return;
- }
- }
- }
- if (!hasMatch) {// 找不到对应需要ack的position
- throw new CanalStoreException("no match ack position" + position.toString());
- }
- } finally {
- lock.unlock();
- }
- }
在匹配尚未ack的Event,是否有匹配的位置时,调用了CanalEventUtils#checkPosition方法。其内部:
首先比较Event的生成时间
接着,如果位置信息的binlog文件名或者信息不为空的话(通常不为空),则会进行精确匹配
CanalEventUtils#checkPosition
- /**
- * 判断当前的entry和position是否相同
- */
- public static boolean checkPosition(Event event, LogPosition logPosition) {
- EntryPosition position = logPosition.getPostion();
- CanalEntry.Entry entry = event.getEntry();
- //匹配时间
- boolean result = position.getTimestamp().equals(entry.getHeader().getExecuteTime());
- //判断是否需要根据:binlog文件+position进行比较
- boolean exactely = (StringUtils.isBlank(position.getJournalName()) && position.getPosition() == null);
- if (!exactely) {// 精确匹配
- result &= StringUtils.equals(entry.getHeader().getLogfileName(), position.getJournalName());
- result &= position.getPosition().equals(entry.getHeader().getLogfileOffset());
- }
- return result;
- }
4.5 rollback操作
相对于put/get/ack操作,rollback操作简单了很多。所谓rollback,就是client已经get到的数据,没能消费成功,因此需要进行回滚。回滚操作特别简单,只需要将getSequence的位置重置为ackSequence,将getMemSize设置为ackMemSize即可。
- public void rollback() throws CanalStoreException {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- getSequence.set(ackSequence.get());
- getMemSize.set(ackMemSize.get());
- } finally {
- lock.unlock();
- }
- }
4.6 其他方法
除了上述提到的所有方法外,MemoryEventStoreWithBuffer还提供了getFirstPosition()和getLatestPosition()方法,分别用于获取当前队列中的第一个和最后一个Event的位置信息。前面已经提到,在CanalServerWithEmbedded中会使用getFirstPosition()方法来获取CanalEventStore中存储的第一个Event的位置,而getLatestPosition()只是在一些单元测试中使用到,因此在这里我们只分析getFirstPosition()方法。
第一条数据通过ackSequence当前值对应的Event来确定,因为更早的Event在ack后都已经被删除了。相关源码如下:
MemoryEventStoreWithBuffer#getFirstPosition
- //获取第一条数据的position,如果没有数据返回为null
- public LogPosition getFirstPosition() throws CanalStoreException {
- final ReentrantLock lock = this.lock;
- lock.lock();
- try {
- long firstSeqeuence = ackSequence.get();
- //1 没有ack过数据,且队列中有数据
- if (firstSeqeuence == INIT_SQEUENCE && firstSeqeuence < putSequence.get()) {
- //没有ack过数据,那么ack为初始值-1,又因为队列中有数据,因此ack+1,即返回队列中第一条数据的位置
- Event event = entries[getIndex(firstSeqeuence + 1)];
- return CanalEventUtils.createPosition(event, false);
- //2 已经ack过数据,但是未追上put操作
- } else if (firstSeqeuence > INIT_SQEUENCE && firstSeqeuence < putSequence.get()) {
- //返回最后一次ack的位置数据 + 1
- Event event = entries[getIndex(firstSeqeuence + 1)];
- return CanalEventUtils.createPosition(event, true);
- //3 已经ack过数据,且已经追上put操作,说明队列中所有数据都被消费完了
- } else if (firstSeqeuence > INIT_SQEUENCE && firstSeqeuence == putSequence.get()) {
- // 最后一次ack的位置数据,和last为同一条
- Event event = entries[getIndex(firstSeqeuence)];
- return CanalEventUtils.createPosition(event, false);
- //4 没有任何数据,返回null
- } else {
- return null;
- }
- } finally {
- lock.unlock();
- }
- }
代码逻辑很简单,唯一需要关注的是,通过CanalEventUtils#createPosition(Event, boolean)方法来计算第一个Event的位置,返回的是一个LogPosition对象。其中boolean参数用LogPosition内部维护的EntryPosition的included属性赋值。在前面get方法源码分析时,我们已经看到,当included值为false时,会把当前get位置+1,然后开始获取Event;当为true时,则直接从当前get位置开始获取数据。
6.0 filter模块
1 Filter模块简介
filter模块用于对binlog进行过滤。在实际开发中,一个mysql实例中可能会有多个库,每个库里面又会有多个表,可能我们只是想订阅某个库中的部分表,这个时候就需要进行过滤。也就是说,parser模块解析出来binlog之后,会进行一次过滤之后,才会存储到store模块中。
过滤规则的配置既可以在canal服务端进行,也可以在客户端进行。
1.1 服务端配置
我们在配置一个canal instance时,在instance.properties中有以下两个配置项:

其中:
canal.instance.filter.regex用于配置白名单,也就是我们希望订阅哪些库,哪些表,默认值为.*\\..*,也就是订阅所有库,所有表。
canal.instance.filter.black.regex用于配置黑名单,也就是我们不希望订阅哪些库,哪些表。没有默认值,也就是默认黑名单为空。
需要注意的是,在过滤的时候,会先根据白名单进行过滤,再根据黑名单过滤。意味着,如果一张表在白名单和黑名单中都出现了,那么这张表最终不会被订阅到,因为白名单通过后,黑名单又将这张表给过滤掉了。
另外一点值得注意的是,过滤规则使用的是perl正则表达式,而不是jdk自带的正则表达式。意味着filter模块引入了其他依赖,来进行匹配。具体来说,filter模块的pom.xml中包含以下两个依赖:
- <dependency>
- <groupId>com.googlecode.aviator</groupId>
- <artifactId>aviator</artifactId>
- </dependency>
- <dependency>
- <groupId>oro</groupId>
- <artifactId>oro</artifactId>
- </dependency>
其中:
aviator:是一个开源的、高性能、轻量级的 java 语言实现的表达式求值引擎
oro:全称为Jakarta ORO,最全面以及优化得最好的正则表达式API之一,Jakarta-ORO库以前叫做OROMatcher,是由DanielF. Savarese编写,后来捐赠给了apache Jakarta Project。canal的过滤规则就是通过oro中的Perl5Matcher来进行完成的。
显然,对于filter模块的源码解析,实际上主要变成了对aviator、oro的分析。
这一点,我们可以从filter模块核心接口CanalEventFilter的实现类中得到验证。CanalEventFilter接口定义了一个filter方法:
- public interface CanalEventFilter<T> {
- boolean filter(T event) throws CanalFilterException;
- }
目前针对CanalEventFilter提供了3个实现类,都是基于开源的java表达式求值引擎Aviator,如下:
提示:这个3个实现都是以Aviater开头,应该是拼写错误,正确的应该是Aviator。
其中:
AviaterELFilter:基于Aviator el表达式的匹配过滤
AviaterSimpleFilter:基于Aviator进行tableName简单过滤计算,不支持正则匹配
AviaterRegexFilter:基于Aviator进行tableName正则匹配的过滤算法。内部使用到了一个RegexFunction类,这是对Aviator自定义的函数的扩展,内部使用到了oro中的Perl5Matcher来进行正则匹配。
需要注意的是,尽管filter模块提供了3个基于Aviator的过滤器实现,但是实际上使用到的只有AviaterRegexFilter。这一点可以在canal-deploy模块提供的xxx-instance.xml配置文件中得要验证。以default-instance.xml为例,eventParser这个bean包含以下两个属性:
- <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.mysql.MysqlEventParser">
- <!-- ... -->
- <!-- 解析过滤处理 -->
- <property name="eventFilter">
- <bean class="com.alibaba.otter.canal.filter.aviater.AviaterRegexFilter" >
- <constructor-arg index="0" value="${canal.instance.filter.regex:.*\..*}" />
- </bean>
- </property>
- <property name="eventBlackFilter">
- <bean class="com.alibaba.otter.canal.filter.aviater.AviaterRegexFilter" >
- <constructor-arg index="0" value="${canal.instance.filter.black.regex:}" />
- <constructor-arg index="1" value="false" />
- </bean>
- </property>
- <!-- ... -->
- </bean>
其中:
eventFilter属性:使用配置项canal.instance.filter.regex的值进行白名单过滤。
eventBlackFilter属性:使用配置项canal.instance.filter.black.regex进行黑名单过滤。
这两个属性的值都是通过一个内部bean的方式进行配置,类型都是AviaterRegexFilter。由于其他两个类型的CanalEventFilter实现在parser模块中并没有使用到,因此后文中,我们也只会对AviaterRegexFilter进行分析。
前面提到,parser模块在过滤的时候,会先根据canal.instance.filter.regex进行白名单过滤,再根据 canal.instance.filter.black.regex进行黑名单过滤。到这里,实际上就是先通过eventFilter进行摆明但过滤,通过eventBlackFilter进行黑名单过滤。
parser模块实际上会将eventFilter、eventBlackFilter设置到一个LogEventConvert对象中,这个对象有2个方法:parseQueryEvent和parseRowsEvent都进行了过滤。以parseRowsEvent方法为例:
com.alibaba.otter.canal.parse.inbound.mysql.dbsync.LogEventConvert#parseRowsEvent(省略部分代码片段)
- private Entry parseRowsEvent(RowsLogEvent event) {
- ...
- TableMapLogEvent table = event.getTable();
- String fullname = table.getDbName() + "." + table.getTableName();
- // check name filter
- if (nameFilter != null && !nameFilter.filter(fullname)) {
- return null;
- }
- if (nameBlackFilter != null && nameBlackFilter.filter(fullname)) {
- return null;
- }
- ...
- }
这里的nameFilter、nameBlackFilter实际上就是我们设置到parser中的 eventFilter、eventBlackFilter,只不过parser将其设置到LogEventConvert对象中换了一个名字。
可以看到,的确是先使用nameFilter进行白名单过滤,再使用nameBlackFilter进行黑名单过滤。在过滤时,使用dbName+"."+tableName作为参数,进行过滤。如果被过滤掉了,就返回null。
再次提醒,由于黑名单后过滤,因此如果希望订阅一个表,一定不要在黑名单中出现。
1.2 客户端配置
上面提到的都是服务端配置。canal也支持客户端配置过滤规则。举例来说,假设一个库有10张表,一个client希望订阅其中5张表,另一个client希望订阅另5张表。此时,服务端可以订阅10张表,当client来消费的时候,根据client的过滤规则只返回给对应的binlog event。
客户端指定过滤规则通过client模块中的CanalConnector的subscribe方法来进行,subscribe有两种重载形式,如下:
- //对于第一个subscribe方法,不指定filter,以服务端的filter为准
- void subscribe() throws CanalClientException;
- // 指定了filter:
- // 如果本次订阅中filter信息为空,则直接使用canal server服务端配置的filter信息
- // 如果本次订阅中filter信息不为空,目前会直接替换canal server服务端配置的filter信息,以本次提交的为准
- void subscribe(String filter) throws CanalClientException;
通过不同client指定不同的过滤规则,可以达到服务端一份数据供多个client进行订阅消费的效果。
然而,想法是好的,现实确是残酷的,由于目前一个canal instance只允许一个client订阅,因此目前还达不到这种效果。读者明白这种设计的初衷即可。
最后列出filter模块的目录结构,这个模块的类相当的少,如下:
到此,filter模块的主要作用已经讲解完成。接着应该针对AviaterRegexFilter进行源码分析,由于其基于Aviator和oro基础之上编写,因此先对Aviator和oro进行介绍。
2 Aviator快速入门
说明,这里关于Aviator的相关内容直接摘录自官网:https://github.com/killme2008/aviator,并没有包含Aviator所有内容,仅仅是就canal内部使用到的一些特性进行讲解。
Aviator是一个高性能、轻量级的 java 语言实现的表达式求值引擎, 主要用于各种表达式的动态求值。现在已经有很多开源可用的 java 表达式求值引擎,为什么还需要 Avaitor 呢?
Aviator的设计目标是轻量级和高性能,相比于Groovy、JRuby的笨重, Aviator非常小, 加上依赖包也才 537K,不算依赖包的话只有 70K; 当然, Aviator的语法是受限的, 它不是一门完整的语言, 而只是语言的一小部分集合。
其次, Aviator的实现思路与其他轻量级的求值器很不相同, 其他求值器一般都是通过解释的方式运行, 而Aviator则是直接将表达式编译成 JVM 字节码, 交给 JVM 去执行。简单来说, Aviator的定位是介于 Groovy 这样的重量级脚本语言和 IKExpression 这样的轻量级表达式引擎之间。
Aviator 的特性:
支持绝大多数运算操作符,包括算术操作符、关系运算符、逻辑操作符、位运算符、正则匹配操作符(=~)、三元表达式(?:)
支持操作符优先级和括号强制设定优先级
逻辑运算符支持短路运算。
支持丰富类型,例如nil、整数和浮点数、字符串、正则表达式、日期、变量等,支持自动类型转换。
内置一套强大的常用函数库
可自定义函数,易于扩展
可重载操作符
支持大数运算(BigInteger)和高精度运算(BigDecimal)
性能优秀
引入Aviator, 从 3.2.0 版本开始, Aviator 仅支持 JDK 7 及其以上版本。 JDK 6 请使用 3.1.1 这个稳定版本。
- <dependency>
- <groupId>com.googlecode.aviator</groupId>
- <artifactId>aviator</artifactId>
- <version>{version}</version>
- </dependency>
注意:canal 1.0.24 中使用的是Aviator 2.2.1版本。
Aviator的使用都是集中通过com.googlecode.aviator.AviatorEvaluator这个入口类来处理。在canal提供的AviaterRegexFilter中,仅仅使用到了Aviator部分功能,我们这里也仅仅就这些功能进行讲解。
2.1 编译表达式
参考:https://github.com/killme2008/aviator/wiki#%E7%BC%96%E8%AF%91%E8%A1%A8%E8%BE%BE%E5%BC%8F
案例:
- public class TestAviator {
- public static void main(String[] args) {
- //1、定义一个字符串表达式
- String expression = "a-(b-c)>100";
- //2、对表达式进行编译,得到Expression对象实例
- Expression compiledExp = AviatorEvaluator.compile(expression);
- //3、准备计算表达式需要的参数
- Map<String, Object> env = new HashMap<String, Object>();
- env.put("a", 100.3);
- env.put("b", 45);
- env.put("c", -199.100);
- //4、执行表达式,通过调用Expression的execute方法
- Boolean result = (Boolean) compiledExp.execute(env);
- System.out.println(result); // false
- }
- }
通过compile方法可以将表达式编译成Expression的中间对象, 当要执行表达式的时候传入env并调用Expression的execute方法即可。 表达式中使用了括号来强制优先级, 这个例子还使用了>用于比较数值大小, 比较运算符!=、==、>、>=、<、<=不仅可以用于数值, 也可以用于String、Pattern、Boolean等等, 甚至是任何用户传入的两个都实现了java.lang.Comparable接口的对象之间。
编译后的结果你可以自己缓存, 也可以交给 Aviator 帮你缓存, AviatorEvaluator内部有一个全局的缓存池, 如果你决定缓存编译结果, 可以通过:
- public static Expression compile(String expression, boolean cached)
将cached设置为true即可, 那么下次编译同一个表达式的时候将直接返回上一次编译的结果。
使缓存失效通过以下方法:
- public static void invalidateCache(String expression)
2.2 自定义函数
参考:https://github.com/killme2008/aviator/wiki#%E8%87%AA%E5%AE%9A%E4%B9%89%E5%87%BD%E6%95%B0
Aviator 除了内置的函数之外,还允许用户自定义函数,只要实现com.googlecode.aviator.runtime.type.AviatorFunction接口, 并注册到AviatorEvaluator即可使用. AviatorFunction接口十分庞大, 通常来说你并不需要实现所有的方法, 只要根据你的方法的参 数个数, 继承AbstractFunction类并override相应方法即可。
可以看一个例子,我们实现一个add函数来做数值的相加:
- //1、自定义函数AddFunction,继承AbstractFunction,覆盖其getName方法和call方法
- class AddFunction extends AbstractFunction {
- // 1.1 getName用于返回函数的名字,之后需要使用这个函数时,达表示需要以add开头
- public String getName() {
- return "add";
- }
- // 1.2 在执行计算时,call方法将会被回调。call方法有多种重载形式,参数可以分为2类:
- // 第一类:所有的call方法的第一个参数都是Map类型的env参数。
- // 第二类:不同数量的AviatorObject参数。由于在这里我们的add方法只接受2个参数,
- // 所以覆盖接受2个AviatorObject参数call方法重载形式
- // 用户在执行时,通过"函数名(参数1,参数2,...)"方式执行函数,如:"add(1, 2)"
- @Override
- public AviatorObject call(Map<String, Object> env, AviatorObject arg1, AviatorObject arg2) {
- Number left = FunctionUtils.getNumberValue(arg1, env);
- Number right = FunctionUtils.getNumberValue(arg2, env);
- return new AviatorDouble(left.doubleValue() + right.doubleValue());
- }
- }
- public class TestAviator {
- public static void main(String[] args) {
- //注册函数
- AviatorEvaluator.addFunction(new AddFunction());
- System.out.println(AviatorEvaluator.execute("add(1, 2)")); // 3.0
- System.out.println(AviatorEvaluator.execute("add(add(1, 2), 100)")); // 103.0
- }
- }
注册函数通过AviatorEvaluator.addFunction方法, 移除可以通过removeFunction。另外, FunctionUtils 提供了一些方便参数类型转换的方法。
3 AviaterRegexFilter源码解析
AviaterRegexFilter实现了CanalEventParser接口,主要是实现其filter方法对binlog进行过滤。
首先对AviaterRegexFilter中定义的字段和构造方法进行介绍:
com.alibaba.otter.canal.filter.aviater.AviaterRegexFilter
- public class AviaterRegexFilter implements CanalEventFilter<String> {
- //我们的配置的binlog过滤规则可以由多个正则表达式组成,使用逗号”,"进行分割
- private static final String SPLIT = ",";
- //将经过逗号",”分割后的过滤规则重新使用|串联起来
- private static final String PATTERN_SPLIT = "|";
- //canal定义的Aviator过滤表达式,使用了regex自定义函数,接受pattern和target两个参数
- private static final String FILTER_EXPRESSION = "regex(pattern,target)";
- //regex自定义函数实现,RegexFunction的getName方法返回regex,call方法接受两个参数
- private static final RegexFunction regexFunction = new RegexFunction();
- //对自定义表达式进行编译,得到Expression对象
- private final Expression exp = AviatorEvaluator.compile(FILTER_EXPRESSION, true);
- static {
- //将自定义函数添加到AviatorEvaluator中
- AviatorEvaluator.addFunction(regexFunction);
- }
- //用于比较两个字符串的大小
- private static final Comparator<String> COMPARATOR = new StringComparator();
- //用户设置的过滤规则,需要使用SPLIT进行分割
- final private String pattern;
- //在没有指定过滤规则pattern情况下的默认值,例如默认为true,表示用户不指定过滤规则情况下,总是返回所有的binlog event
- final private boolean defaultEmptyValue;
- public AviaterRegexFilter(String pattern) {
- this(pattern, true);
- }
- //构造方法
- public AviaterRegexFilter(String pattern, boolean defaultEmptyValue) {
- //1 给defaultEmptyValue字段赋值
- this.defaultEmptyValue = defaultEmptyValue;
- //2、给pattern字段赋值
- //2.1 将传入pattern以逗号",”进行分割,放到list中;如果没有指定pattern,则list为空,意味着不需要过滤
- List<String> list = null;
- if (StringUtils.isEmpty(pattern)) {
- list = new ArrayList<String>();
- } else {
- String[] ss = StringUtils.split(pattern, SPLIT);
- list = Arrays.asList(ss);
- }
- //2.2 对list中的pattern元素,按照从长到短的排序
- Collections.sort(list, COMPARATOR);
- //2.3 对pattern进行头尾完全匹配
- list = completionPattern(list);
- //2.4 将过滤规则重新使用|串联起来赋值给pattern
- this.pattern = StringUtils.join(list, PATTERN_SPLIT);
- }
- ...
- }
上述代码中,2.2 步骤使用了COMPARATOR对list中分割后的pattern进行比较,COMPARATOR的类型是StringComparator,这是定义在AviaterRegexFilter中的一个静态内部类
- /**
- * 修复正则表达式匹配的问题,因为使用了 oro 的 matches,会出现:
- * foo|foot 匹配 foot 出错,原因是 foot 匹配了 foo 之后,会返回 foo,但是 foo 的长度和 foot 的长度不一样
- * 因此此类对正则表达式进行了从长到短的排序
- */
- private static class StringComparator implements Comparator<String> {
- @Override
- public int compare(String str1, String str2) {
- if (str1.length() > str2.length()) {
- return -1;
- } else if (str1.length() < str2.length()) {
- return 1;
- } else {
- return 0;
- }
- }
- }
上述代码2.3节调用completionPattern(list)方法对list中分割后的pattern进行头尾完全匹配
- /**
- * 修复正则表达式匹配的问题,即使按照长度递减排序,还是会出现以下问题:
- * foooo|f.*t 匹配 fooooot 出错,原因是 fooooot 匹配了 foooo 之后,会将 fooo 和数据进行匹配,
- * 但是 foooo 的长度和 fooooot 的长度不一样,因此此类对正则表达式进行头尾完全匹配
- */
- private List<String> completionPattern(List<String> patterns) {
- List<String> result = new ArrayList<String>();
- for (String pattern : patterns) {
- StringBuffer stringBuffer = new StringBuffer();
- stringBuffer.append("^");
- stringBuffer.append(pattern);
- stringBuffer.append("$");
- result.add(stringBuffer.toString());
- }
- return result;
- }
- }
filter方法
AviaterRegexFilter类中最重要的就是filter方法,由这个方法执行过滤,如下:
- //1 参数:前面已经分析过parser模块的LogEventConvert中,会将binlog event的 dbName+”."+tableName当做参数过滤
- public boolean filter(String filtered) throws CanalFilterException {
- //2 如果没有指定匹配规则,返回默认值
- if (StringUtils.isEmpty(pattern)) {
- return defaultEmptyValue;
- }
- //3 如果需要过滤的dbName+”.”+tableName是一个空串,返回默认值
- //提示:一些类型的binlog event,如heartbeat,并不是真正修改数据,这种类型的event是没有库名和表名的
- if (StringUtils.isEmpty(filtered)) {
- return defaultEmptyValue;
- }
- //4 将传入的dbName+”."+tableName通过canal自定义的Aviator扩展函数RegexFunction进行计算
- Map<String, Object> env = new HashMap<String, Object>();
- env.put("pattern", pattern);
- env.put("target", filtered.toLowerCase());
- return (Boolean) exp.execute(env);
- }
第4步通过exp.execute方法进行过滤判断,前面已经看到,exp这个Expression实例是通过"regex(pattern,target)"编译得到。根据前面对AviatorEvaluator的介绍,其应该调用一个名字为regex的Aviator自定义函数,这个函数接受2个参数。
RegexFunction的实现如下所示:
com.alibaba.otter.canal.filter.aviater.RegexFunction
- public class RegexFunction extends AbstractFunction {
- public AviatorObject call(Map<String, Object> env, AviatorObject arg1, AviatorObject arg2) {
- String pattern = FunctionUtils.getStringValue(arg1, env);
- String text = FunctionUtils.getStringValue(arg2, env);
- Perl5Matcher matcher = new Perl5Matcher();
- boolean isMatch = matcher.matches(text, PatternUtils.getPattern(pattern));
- return AviatorBoolean.valueOf(isMatch);
- }
- public String getName() {
- return "regex";
- }
- }
可以看到,在这个函数里面,实际上是根据配置的过滤规则pattern,以及需要过滤的内容text(即dbName+”.”+tableName),通过jarkata-oro中Perl5Matcher类进行正则表达式匹配。
canal源码分析简介-3的更多相关文章
- 【Canal源码分析】Canal Instance启动和停止
一.序列图 1.1 启动 1.2 停止 二.源码分析 2.1 启动 这部分代码其实在ServerRunningMonitor的start()方法中.针对不同的destination,启动不同的Cana ...
- 【Canal源码分析】Canal Server的启动和停止过程
本文主要解析下canal server的启动过程,希望能有所收获. 一.序列图 1.1 启动 1.2 停止 二.源码分析 整个server启动的过程比较复杂,看图难以理解,需要辅以文字说明. 首先程序 ...
- 「从零单排canal 03」 canal源码分析大纲
在前面两篇中,我们从基本概念理解了canal是一个什么项目,能应用于什么场景,然后通过一个demo体验,有了基本的体感和认识. 从这一篇开始,我们将从源码入手,深入学习canal的实现方式.了解can ...
- 【Canal源码分析】parser工作过程
本文主要分析的部分是instance启动时,parser的一个启动和工作过程.主要关注的是AbstractEventParser的start()方法中的parseThread. 一.序列图 二.源码分 ...
- 【Canal源码分析】Sink及Store工作过程
一.序列图 二.源码分析 2.1 Sink Sink阶段所做的事情,就是根据一定的规则,对binlog数据进行一定的过滤.我们之前跟踪过parser过程的代码,发现在parser完成后,会把数据放到一 ...
- 使用canal分析binlog(二) canal源码分析
在能够跑通example后有几个疑问 1. canal的server端对于已经读取的binlog,client已经ack的position,是否持久化,保存在哪里 2. 即使不启动zookeeper, ...
- 【Canal源码分析】重要类图
从Canal的整体架构中,我们可以看出,在Canal中,比较重要的一些领域有Parser.Sink.Store.MetaManager.CanalServer.CanalInstance.CanalC ...
- 【Canal源码分析】TableMetaTSDB
这是Canal在新版本引入的一个内容,主要是为了解决由于历史的DDL导致表结构与现有表结构不一致,导致的同步失败的问题.采用的是Druid和Fastsql,来记录表结构到DB中,如果需要进行回滚时,得 ...
- 【Canal源码分析】整体架构
本文详解canal的整体架构. 一.整体架构 说明: server代表一个canal运行实例,对应于一个jvm instance对应于一个数据队列 (1个server对应1..n个instance) ...
- 【Canal源码分析】配置项
本文讲解canal中的一些配置含义. 一.配置加载图 二.配置文件canal.properties 2.1 common参数定义 比如可以将instance.properties的公用参数,抽取放置到 ...
随机推荐
- rce临时文件上传[RCE1]P8
rce临时文件上传[RCE1]P8 /[A-Za-z0-9!~^|&]+/i 匹配了我能想到的所有绕过方法,想到临时文件上传,是否可以执行/tmp/?????????这个文件呢 /tmp/?? ...
- Codeforces 1969 A-F
题面 A B C D E F 难度:红 橙 绿 绿 蓝 紫
- 如何挑选海外4G模组?这里有秘籍!
今天我会告诉大家如何挑选海外4G模组,我会把优势给贴出作为参考.去过国外的都知道国外4G网络各种状况实在让人无力吐槽,做海外设备的朋友,是时候了解一下Air780EEN/EEU/EEJ系列海外模组-- ...
- nvidia公司的机器人仿真环境的历史发展介绍(Isaac-Gym、Isaac-Sim)
相关: NVIDIA机器人仿真项目 -- Isaac Gym - Preview Release 本文说下NVIDIA公司的机器人仿真项目的一些历史发展. NVIDIA公司的产品最初只有显卡,但是卖着 ...
- C#-JavaScript-base64加密解码
C# //base64加密 //调用方式:Helper.EncodeToBase64(需要加密字符串) public static string EncodeToBase64(string data) ...
- 想学习建个网站?WAMP Server助你在Windows上快速搭建PHP集成环境
我想只要爬过几天网的同学都会知道PHP吧,异次元的新版本就是基于PHP的WordPress程序制造出来的,还有国内绝大部分论坛都是PHP的哦.据我所知很多同学都想要试着学习一下PHP,无奈要在Wind ...
- sort函数详解
sort函数 简介 其实STL中的sort()并非只是普通的快速排序,除了对普通的快速排序进行优化,它还结合了插入排序和堆排序.根据不同的数量级别以及不同情况,能自动选用合适的排序方法.当数据量较大时 ...
- Skyvern – AI浏览器自动化测试工具
Skyvern – AI浏览器自动化测试工具 Skyvern是什么 Skyvern是开源的浏览器自动化工具,结合大型语言模型(LLMs)和计算机视觉技术实现复杂的网页交互和数据提取.与传统的 ...
- 一图一知-vue强大的slot
vue常用的slot知识点记录
- 某开源ERP最新版SQL与RCE的审计过程
文章首发于 https://forum.butian.net/share/134 前言 代码路径 https://gitee.com/jishenghua/JSH_ERP 软件版本 华夏ERP_v2. ...