elasticsearch5.0.1集群排错的几个思路总结
1.首先查看集群整体健康状态
# curl -XGET http://10.27.35.94:9200/_cluster/health?pretty
{
"cluster_name" : "yunva-es",
"status" : "red",
"timed_out" : false,
"number_of_nodes" : ,
"number_of_data_nodes" : ,
"active_primary_shards" : ,
"active_shards" : ,
"relocating_shards" : ,
"initializing_shards" : ,
"unassigned_shards" : ,
"delayed_unassigned_shards" : ,
"number_of_pending_tasks" : ,
"number_of_in_flight_fetch" : ,
"task_max_waiting_in_queue_millis" : ,
"active_shards_percent_as_number" : 86.26373626373626
}
如果是red状态,说明有节点挂掉,找到挂掉的索引分片和节点
如下例子,可以看到 voice:live:logout 这个索引的0分片都没有分配说明挂掉了,我们可以查看之前正常的时候的分片情况(可以定期将分片的分配情况记录下来)
# curl 10.26.241.237:/_cat/shards
....
voice:live:logout p STARTED .9kb 10.27.65.121 yunva_etl_es6
voice:live:logout r STARTED .9kb 10.26.241.239 yunva_etl_es3
voice:live:logout r STARTED .8kb 10.45.150.115 yunva_etl_es9
voice:live:logout p STARTED .8kb 10.25.177.47 yunva_etl_es11
voice:live:logout p STARTED .7kb 10.26.241.239 yunva_etl_es3
voice:live:logout r STARTED .7kb 10.25.177.47 yunva_etl_es11
voice:live:logout p STARTED .2kb 10.27.35.94 yunva_etl_es7
voice:live:logout r STARTED .2kb 10.27.78.228 yunva_etl_es5
voice:live:logout 0 p UNASSIGNED
voice:live:logout 0 r UNASSIGNED
定期记录分片的脚本
# cat es_shard.sh
#!/bin/bash echo $(date +"%Y-%m-%d %H:%M:%S") >> /data/es_shards.txt
curl -XGET http://10.26.241.237:9200/_cat/shards >> /data/es_shards.txt
2.依次查询节点的健康状态,如果哪个节点不返回,或者很慢,可能是内存溢出,需要直接重启该节点
# curl -XGET http://IP:9200/_cluster/health?pretty
内存溢出的典型特征会在elasticsearch/bin目录下产生类似如下文件:
hs_err_pid27186.log
java_pid1151.hprof
3.zabbix添加监控
①如果挂掉自动启动(注意不能是root用户)
自动启动elasticsearch脚本:
# cat /usr/local/zabbix-agent/scripts/start_es.sh #!/bin/bash
# if elasticsearch process exists kill it
source /etc/profile count_es=`ps -ef|grep elasticsearch|grep -v grep|wc -l`
if [ $count_es -gt ];then
ps -ef|grep elasticsearch|grep -v grep|/bin/kill `awk '{print $2}'`
fi
rm -f /data/elasticsearch-5.0./bin/java_pid*.hprof
# start it
su yunva -c "cd /data/elasticsearch-5.0.1/bin && /bin/bash elasticsearch &"
②有hs_err*.log或者hprof文件删除文件然后重启该节点(可以直接触发start_es.sh脚本)
elasticsearch报错监控项:
UserParameter=es_debug,sudo /bin/find /data/elasticsearch-5.0.1/bin/ -name hs_err_pid*.log -o -name java_pid*.hprof|wc -l
java报错的监控项:
UserParameter=java_error,sudo /bin/find /home -name hs_err_pid*.log -o -name java_pid*.hprof -o -name jvm.log|wc -l
③curl -XGET http://IP:9200/_cluster/health?pretty 如果响应时间超过30S重启
for IP in 10.28.50.131 10.26.241.239 10.25.135.215 10.26.241.237 10.27.78.228 10.27.65.121 10.27.35.94 10.30.136.143 10.174.12.230 10.45.150.115 10.25.177.47
do
curl -XGET http://$IP:9200/_cluster/health?pretty
done
4.优化配置:
# 以下配置可以减少当es节点短时间宕机或重启时shards重新分布带来的磁盘io读写浪费
discovery.zen.fd.ping_timeout: 300s
discovery.zen.fd.ping_retries:
discovery.zen.fd.ping_interval: 30s
discovery.zen.ping_timeout: 300s
5.es集群状态检测
UserParameter=es_cluster_status,curl -sXGET http://10.11.117.18:9200/_cluster/health/?pretty | grep "status"|awk -F '[ "]+' '{print $4}'|grep -c 'green'
后续如果有其他方面的一些好的方法也会更新上来
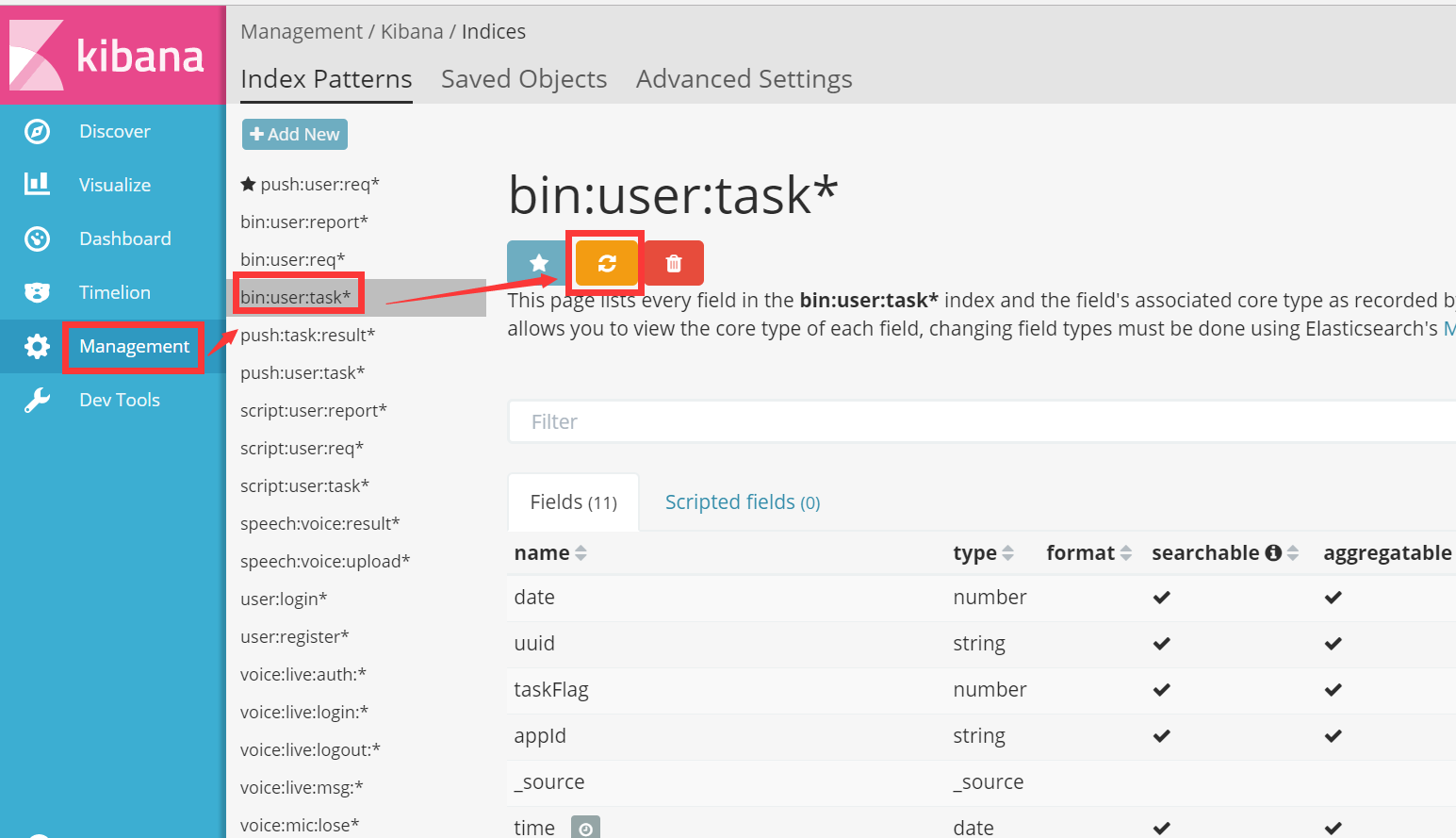
索引修改以后,需要刷新index表达式,否则无法正常识别
elasticsearch5.0.1集群排错的几个思路总结的更多相关文章
- elasticsearch5.0.1集群一次误删除kibana索引引发的血案
elasticsearch集群中一次删除kibana索引引发的血案 1.问题发生的过程: 早上的时候有某个索引无法看到报表数据,于是就点该报表多次,估计集群被点挂了,报错:Elasticsearch ...
- elasticsearch5.0.1集群索引分片丢失的处理
elasticdump命令安装 yum install npm npm install elasticdump -g 命令安装完毕,可以测试. 可能会报出nodejs的版本之类的错误,你需要升级一下版 ...
- ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决
说起来甚是惭愧,博主在写这篇文章的时候,还没有系统性的学习一下ES,只知道可以拿来做全文检索,功能很牛逼,但是接到了任务不想做也不行, leader让我搭建一下分布式的ES集群环境,用来支持企业信用数 ...
- Redis 3.0 Cluster集群配置
Redis 3.0 Cluster集群配置 安装环境依赖 安装gcc:yum install gcc 安装zlib:yum install zib 安装ruby:yum install ruby 安装 ...
- 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群(转载-2)
原文:http://www.cnblogs.com/PurpleDream/p/4510279.html 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群 前言: ...
- 菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章
菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章 cheungmine, 2014-10-26 在上一章中,我们准备好了计算机和软件.本章开始部署hadoop 高可用集群. 2 部署 ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- Redis-4.0.11集群配置
版本:redis-3.0.5 redis-3.2.0 redis-3.2.9 redis-4.0.11 参考:http://redis.io/topics/cluster-tutorial. 集群 ...
- Redis 5.0.5集群搭建
Redis 5.0.5集群搭建 一.概述 Redis3.0版本之后支持Cluster. 1.1.redis cluster的现状 目前redis支持的cluster特性: 1):节点自动发现 2):s ...
随机推荐
- c# 三种传参方式 in,out,ref
in:默认方式,传值不返回 out:不传值 但是会返回新值给予传参对象 ref:传存储地址,所以传参前必须赋值初始化,传值后的运算结果直接作用在传参上 Out和ref的效果差不多
- python之所以强大很大一部分原因在于他众多的取之不尽的库
GUI 的 自动任务用这个pyautogui库,web 页面的用 selenium + webdriver 同类型的还有 sikuli ,低配版 按键精灵 本教程译自大神Al Sweigart的PyA ...
- new
Android支持插件库,可以是由C/C++开发的JNI形式,也可以是由java代码开发的jar形式(也可以是android封包完成的apk文件).加载jar插件的方式可以分为 1.静态加载2.动态加 ...
- 五、文件IO——dup 函数
5.1 dup 函数---复制文件描述符 5.1.1 简单cat实现及输入输出重定向 io.c #include <sys/types.h> #include <sys/stat.h ...
- Play XML Entities
链接:https://pentesterlab.com/exercises/play_xxe/course Introduction This course details the exploitat ...
- alexnet- tensorflow
alexnet 在 imagenet上夺冠是卷积神经网络如今这么火热的起点. 虽然卷积神经网络很早就被提出来,但是由于计算能力和各方面原因,没有得到关注. alexnet 为什么能取得这么好的成绩,它 ...
- 第21月第9日 windows下使用vim+ctags+taglist
1. windows下使用vim+ctags+taglist 最近在公司的同事指导下,学会使用这个东西编写代码,效率提高了不少.所以记录下来,方便大家使用. 1. 下载gvim74.exe文件,并安装 ...
- 使用cross-env解决跨平台设置NODE_ENV的问题
使用方法: 安装cross-env:npm install cross-env --save-dev 在NODE_ENV=xxxxxxx前面添加cross-env就可以了.
- jquery禁用a标签
jquery禁用a标签方法1 01 02 03 04 05 06 07 08 09 10 11 12 $(document).ready(function () { $("a ...
- Css - 页面标签页图标
Css - 页面标签页图标 <head> <meta charset="utf-8" /> <title>京东(JD.COM)- ...