深度学习之GRU网络
1、GRU概述
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
在LSTM中引入了三个门函数:输入门、遗忘门和输出门来控制输入值、记忆值和输出值。而在GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:
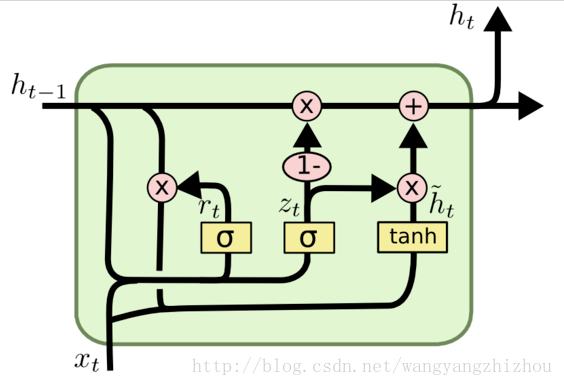
图中的zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 $\tilde{h}_t$ 上,重置门越小,前一状态的信息被写入的越少。
2、GRU前向传播
根据上面的GRU的模型图,我们来看看网络的前向传播公式:
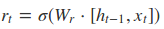
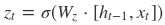
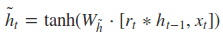
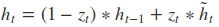
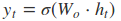
其中[]表示两个向量相连,*表示矩阵的乘积。
3、GRU的训练过程
从前向传播过程中的公式可以看出要学习的参数有Wr、Wz、Wh、Wo。其中前三个参数都是拼接的(因为后先的向量也是拼接的),所以在训练的过程中需要将他们分割出来:
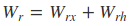
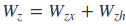
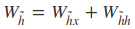
输出层的输入:
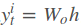
输出层的输出:
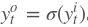
在得到最终的输出后,就可以写出网络传递的损失,单个样本某时刻的损失为:
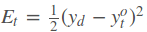
则单个样本的在所有时刻的损失为:
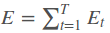
采用后向误差传播算法来学习网络,所以先得求损失函数对各参数的偏导(总共有7个):
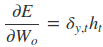
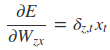
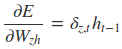
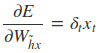
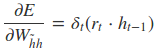
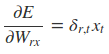
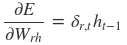
其中各中间参数为:
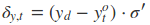
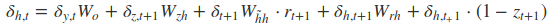
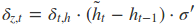
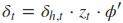
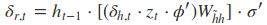
在算出了对各参数的偏导之后,就可以更新参数,依次迭代知道损失收敛。
概括来说,LSTM和CRU都是通过各种门函数来将重要特征保留下来,这样就保证了在long-term传播的时候也不会丢失。此外GRU相对于LSTM少了一个门函数,因此在参数的数量上也是要少于LSTM的,所以整体上GRU的训练速度要快于LSTM的。不过对于两个网络的好坏还是得看具体的应用场景。
参考文献:
***本文为参考各位大神博客的笔记*
深度学习之GRU网络的更多相关文章
- 深度学习图像分割——U-net网络
写在前面: 一直没有整理的习惯,导致很多东西会有所遗忘,遗漏.借着这个机会,养成一个习惯. 对现有东西做一个整理.记录,对新事物去探索.分享. 因此博客主要内容为我做过的,所学的整理记录以及新的算法. ...
- 调参侠的末日? Auto-Keras 自动搜索深度学习模型的网络架构和超参数
Auto-Keras 是一个开源的自动机器学习库.Auto-Keras 的终极目标是允许所有领域的只需要很少的数据科学或者机器学习背景的专家都可以很容易的使用深度学习.Auto-Keras 提供了一系 ...
- 深度学习|基于LSTM网络的黄金期货价格预测--转载
深度学习|基于LSTM网络的黄金期货价格预测 前些天看到一位大佬的深度学习的推文,内容很适用于实战,争得原作者转载同意后,转发给大家.之后会介绍LSTM的理论知识. 我把code先放在我github上 ...
- 深度学习之ResNet网络
介绍 Resnet分类网络是当前应用最为广泛的CNN特征提取网络. 我们的一般印象当中,深度学习愈是深(复杂,参数多)愈是有着更强的表达能力.凭着这一基本准则CNN分类网络自Alexnet的7层发展到 ...
- 深度学习-生成对抗网络GAN笔记
生成对抗网络(GAN)由2个重要的部分构成: 生成器G(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器 判别器D(Discriminator):判断这张图像是真实的 ...
- 深度学习之TCN网络
论文链接:https://arxiv.org/pdf/1803.01271.pdf TCN(Temporal Convolutional Networks) TCN特点: 可实现接收任意长度的输入序列 ...
- 深度学习之Seq_seq网络
知识点 """ 机器翻译: 历史: 1.逐字翻译 2.基于统计学的机器翻译 3.循环网络和编码 翻译过程: 输入 -- > encoder -->向量 --& ...
- 训练深度学习网络时候,出现Nan是什么原因,怎么才能避免?——我自己是因为data有nan的坏数据,clear下解决
from:https://www.zhihu.com/question/49346370 Harick 梯度爆炸了吧. 我的解决办法一般以下几条:1.数据归一化(减均值,除方差,或者加入n ...
- [译]深度学习(Yann LeCun)
深度学习 严恩·乐库 约书亚•本吉奥 杰弗里·希尔顿 摘要深度学习是计算模型,是由多个处理层学习多层次抽象表示的数据.这些方法极大地提高了语音识别.视觉识别.物体识别.目标检测和许多其他领域如药物 ...
随机推荐
- python基础学习(七)列表
列表的定义 List(列表) 是 Python 中使用 最频繁 的数据类型,在其他语言中通常叫做 数组(例如java.c) 专门用于存储 一串 信息 列表用 [] 定义,数据 之间使用 , 分隔 列表 ...
- JS中substring与substr的用法
substring方法用于提取字符串中介于两个指定下标之间的字符 substring(start,end) 开始和结束的位置,从零开始的索引javascript 参数 描述 start 必需.一个非负 ...
- vue-cli中安装方法
源:http://www.cnblogs.com/jn1223/p/6656956.html vue-cli中安装方法 vue-cli脚手架模板是基于node下的npm来完成安装的所以首先需要安装 ...
- php对二维数据排序
对于一维数组排序比较简单,像使用sort(),asort(),arsort()等函数进行排序,但是对于二维数组比较麻烦,所有借鉴网上的总结了一下 // 对二维数组进行指定key排序 $arr 二维数组 ...
- Sublime Text 2 JS 格式化插件 JsFormat
这里下载这插件包 https://github.com/jdc0589/JsFormat ,点油下角的zip就能下载插件包放到sublime安装目录的DataPackages目录中重新打开sublim ...
- angularJS中控制器和作用范围
$scope是$rootScope的子作用域控制对象,$rootScope的id为1,其他的为2,3,4... 不同的控制器之间,所对应的作用域控制对象$scope,之间是相互隔离的,如果要共享数据, ...
- 支持MPI的hdf5库的编译
作者:朱金灿 来源:http://blog.csdn.net/clever101 因为最近要研究并行I/O,据说hdf5文件格式可以支持并行I/O,深度学习框架Caffe用的是hdf格式,所以决定把h ...
- <自动化测试方案书>方案书目录排版
自动化测试方案书 一.介绍 QQ交流群:585499566 这篇是一个系列,用来给需要做自动化测试方案的人做个参考,文章的内容是我收集网上和自己工作经验所得,希望能够给你们有所帮助 背景:因为工作需要 ...
- html之head标签
本文内容: head标签 介绍 常用子标签 meta title link style script 首发时间:2018-02-12 修改: 2018-04-24:修改了标题名称,重新排版了内容,使得 ...
- L2-024. 部落
在一个社区里,每个人都有自己的小圈子,还可能同时属于很多不同的朋友圈.我们认为朋友的朋友都算在一个部落里,于是要请你统计一下,在一个给定社区中,到底有多少个互不相交的部落?并且检查任意两个人是否属于同 ...