Python图表数据可视化Seaborn:2. 分类数据可视化-分类散点图|分布图(箱型图|小提琴图|LV图表)|统计图(柱状图|折线图)
1. 分类数据可视化 - 分类散点图
stripplot( ) / swarmplot( )
sns.stripplot(x="day",y="total_bill",data=tips,jitter = True, size = 5, edgecolor = 'w',linewidth=1,marker = 'o')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
% matplotlib inline sns.set_style("whitegrid")
sns.set_context("paper")
# 设置风格、尺度 import warnings
warnings.filterwarnings('ignore')
# 不发出警告
# 1、stripplot()
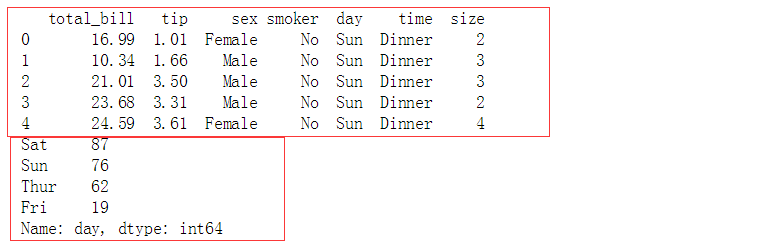
# 按照不同类别对样本数据进行分布散点图绘制 tips = sns.load_dataset("tips")
print(tips.head())
# 加载数据
print(tips['day'].value_counts())
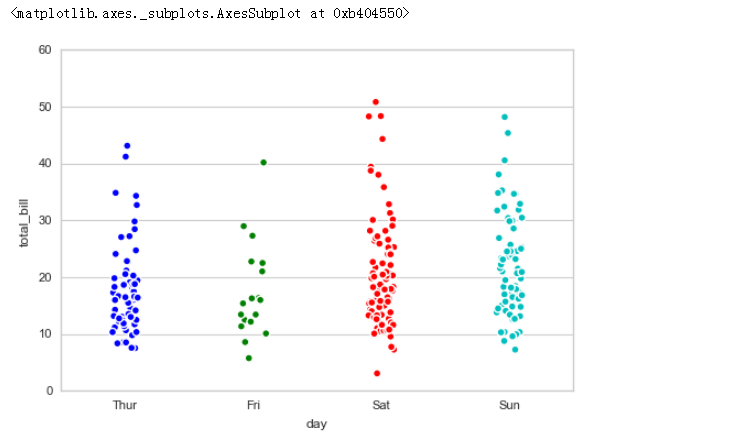
sns.stripplot(x="day", # x → 设置分组统计字段
y="total_bill", # y → 数据分布统计字段
# 这里xy数据对调,将会使得散点图横向分布
data=tips, # data → 对应数据
jitter = True, # jitter → 当点数据重合较多时,用该参数做一些调整,也可以设置间距如:jitter = 0.1
size = 5, edgecolor = 'w',linewidth=1,marker = 'o' # 设置点的大小、描边颜色或宽度、点样式
)
1.1 stripplot()
hue参数可再分类
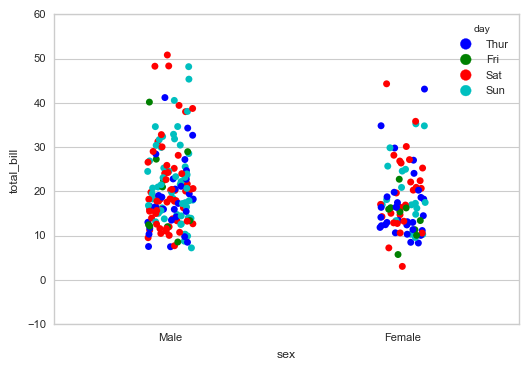
# 1、stripplot() 通过hue参数再分类 sns.stripplot(x="sex", y="total_bill", hue="day",
data=tips, jitter=True)
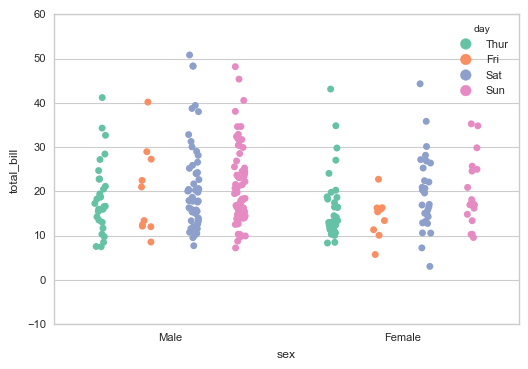
# 1、stripplot() 设置调色盘 sns.stripplot(x="sex", y="total_bill", hue="day",
data=tips, jitter=True,
palette="Set2", # 设置调色盘
dodge=True, # 是否拆分
)
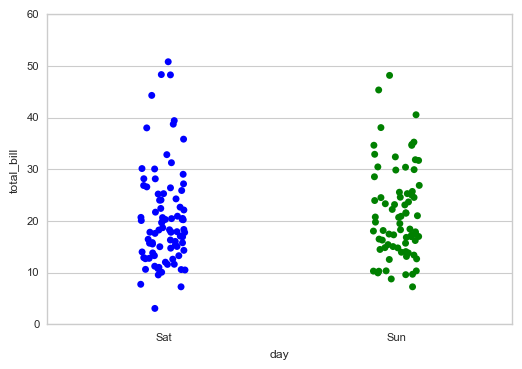
# 1、stripplot() 筛选分类类别 print(tips['day'].value_counts())
# 查看day字段的唯一值 sns.stripplot(x="day", y="total_bill", data=tips,jitter = True,
order = ['Sat','Sun'])
# order → 筛选类别

1.2 swarmplot()分簇散点图
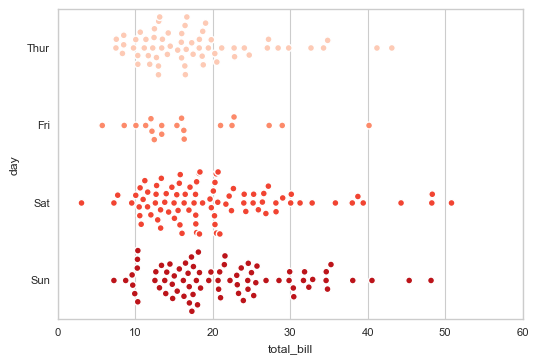
# 2、swarmplot()
# 分簇散点图 sns.swarmplot(x="total_bill", y="day", data=tips,
size = 5, edgecolor = 'w',linewidth=1,marker = 'o',
palette = 'Reds')
# 用法和stripplot类似
2. 分类数据可视化 - 分布图
boxplot( ) / violinplot( ) / lvplot( )
2.1 boxplot()箱型图
sns.boxplot(x="day", y="total_bill", data=tips,
linewidth = 2, # 线宽
width = 0.8, # 箱之间的间隔比例
fliersize = 3, # 异常点大小
palette = 'hls', # 设置调色板
whis = 1.5, # 设置IQR
notch = True, # 设置是否以中值做凹槽
order = ['Thur','Fri','Sat','Sun'], # 筛选类别
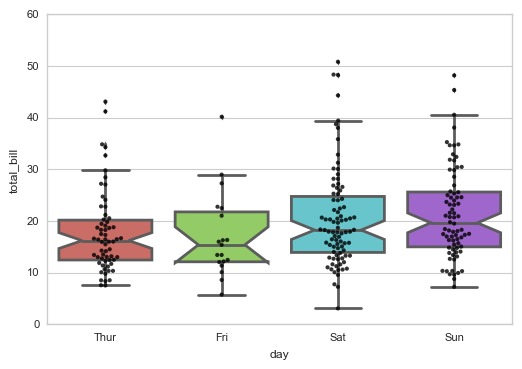
# 1、boxplot()
# 箱型图 sns.boxplot(x="day", y="total_bill", data=tips,
linewidth = 2, # 线宽
width = 0.8, # 箱之间的间隔比例
fliersize = 3, # 异常点大小
palette = 'hls', # 设置调色板
whis = 1.5, # 设置IQR
notch = True, # 设置是否以中值做凹槽
order = ['Thur','Fri','Sat','Sun'], # 筛选类别
)
# 绘制箱型图 sns.swarmplot(x="day", y="total_bill", data=tips,color ='k',size = 3,alpha = 0.8)
# 可以添加散点图
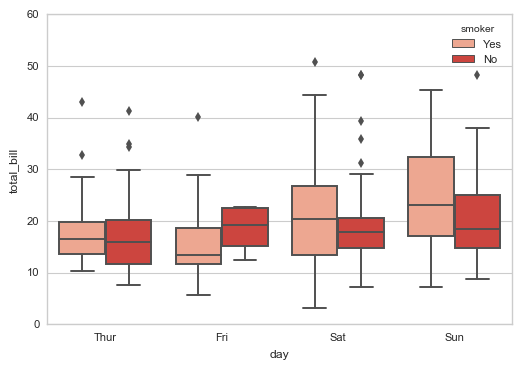
# 1、boxplot() 通过hue参数再分类 sns.boxplot(x="day", y="total_bill", data=tips,
hue = 'smoker', palette = 'Reds')
# 绘制箱型图 #sns.swarmplot(x="day", y="total_bill", data=tips,color ='k',size = 3,alpha = 0.8)
# 可以添加散点图
2.2 violinplot()小提琴图
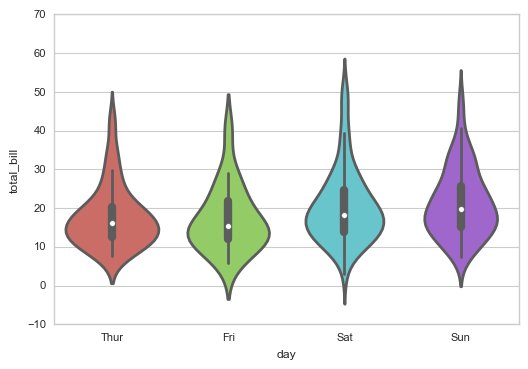
sns.violinplot(x="day", y="total_bill", data=tips,
linewidth = 2, # 线宽
width = 0.8, # 箱之间的间隔比例
palette = 'hls', # 设置调色板
order = ['Thur','Fri','Sat','Sun'], # 筛选类别
scale = 'area', # 测度小提琴图的宽度:area-面积相同,count-按照样本数量决定宽度,width-宽度一样
gridsize = 50, # 设置小提琴图边线的平滑度,越高越平滑
inner = 'box', # 设置内部显示类型 → “box”, “quartile”, “point”, “stick”, None
#bw = 0.8 # 控制拟合程度,一般可以不设置
)
# 2、violinplot() 小提琴图 sns.violinplot(x="day", y="total_bill", data=tips,
linewidth = 2, # 线宽
width = 0.8, # 箱之间的间隔比例
palette = 'hls', # 设置调色板
order = ['Thur','Fri','Sat','Sun'], # 筛选类别
scale = 'area', # 测度小提琴图的宽度:area-面积相同,count-按照样本数量决定宽度,width-宽度一样
gridsize = 50, # 设置小提琴图边线的平滑度,越高越平滑
inner = 'box', # 设置内部显示类型 → “box”, “quartile”, “point”, “stick”, None
#bw = 0.8 # 控制拟合程度,一般可以不设置
)
# 用法和boxplot类似
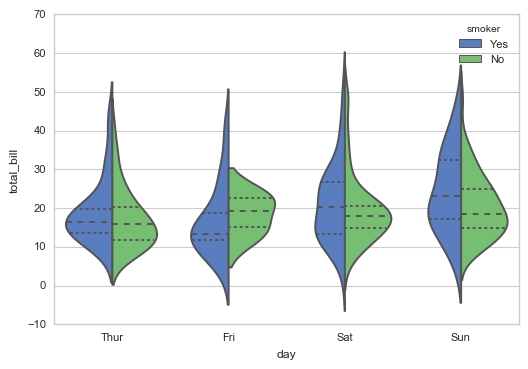
# 2、violinplot() 通过hue参数再分类 sns.violinplot(x="day", y="total_bill", data=tips,
hue = 'smoker', palette="muted",
split=True, # 设置是否拆分小提琴图
inner="quartile")
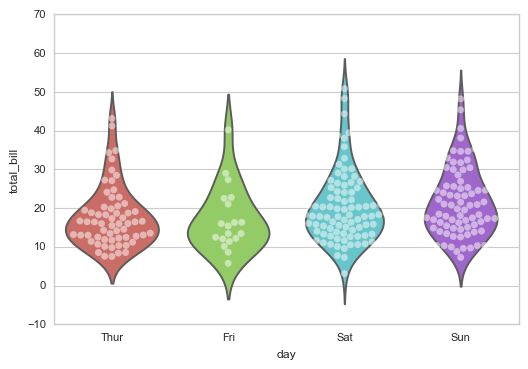
sns.violinplot()+ sns.swarmplot()小提琴图结合散点图
# 2、violinplot() 结合散点图 sns.violinplot(x="day", y="total_bill", data=tips, palette = 'hls', inner = None)
sns.swarmplot(x="day", y="total_bill", data=tips, color="w", alpha=.5)
# 插入散点图
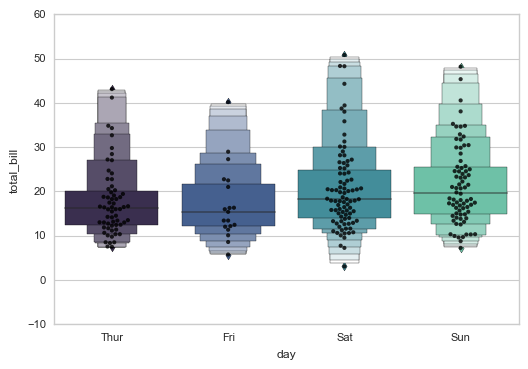
2.3 lvplot() LV图表
sns.lvplot(x="day", y="total_bill", data=tips, palette="mako",
#hue = 'smoker',
width = 0.8, # 箱之间间隔比例
linewidth = 12,
scale = 'area', # 设置框的大小 → “linear”、“exonential”、“area”
k_depth = 'proportion', # 设置框的数量 → “proportion”、“tukey”、“trustworthy”
)
# 3、lvplot() LV图表 sns.lvplot(x="day", y="total_bill", data=tips, palette="mako",
#hue = 'smoker',
width = 0.8, # 箱之间间隔比例
linewidth = 12,
scale = 'area', # 设置框的大小 → “linear”、“exonential”、“area”
k_depth = 'proportion', # 设置框的数量 → “proportion”、“tukey”、“trustworthy”
)
# 绘制LV图 sns.swarmplot(x="day", y="total_bill", data=tips,color ='k',size = 3,alpha = 0.8)
# 可以添加散点图
3. 分类数据可视化 - 统计图
barplot( ) / countplot( ) / pointplot( )
3.1 barplot()柱状图
sns.barplot(x="sex", y="survived", hue="class", data=titanic,
palette = 'hls',
order = ['male','female'], # 筛选类别
capsize = 0.05, # 误差线横向延伸宽度
saturation=.8, # 颜色饱和度
errcolor = 'gray',errwidth = 2, # 误差线颜色,宽度
ci = 'sd' # 置信区间误差 → 0-100内值、'sd'、None
)
# 1、barplot()
# 柱状图 - 置信区间估计
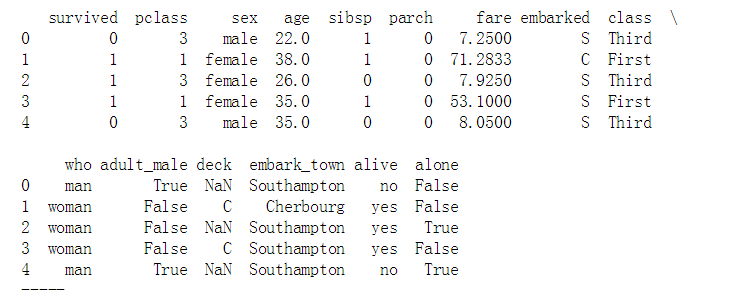
# 置信区间:样本均值 + 抽样误差 titanic = sns.load_dataset("titanic")
print(titanic.head())
print('-----')
# 加载数据
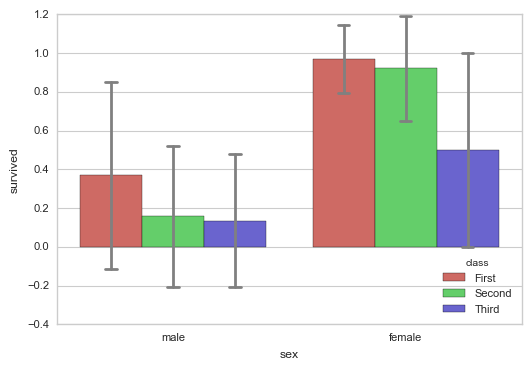
sns.barplot(x="sex", y="survived", hue="class", data=titanic,
palette = 'hls',
order = ['male','female'], # 筛选类别
capsize = 0.05, # 误差线横向延伸宽度
saturation=.8, # 颜色饱和度
errcolor = 'gray',errwidth = 2, # 误差线颜色,宽度
ci = 'sd' # 置信区间误差 → 0-100内值、'sd'、None
)
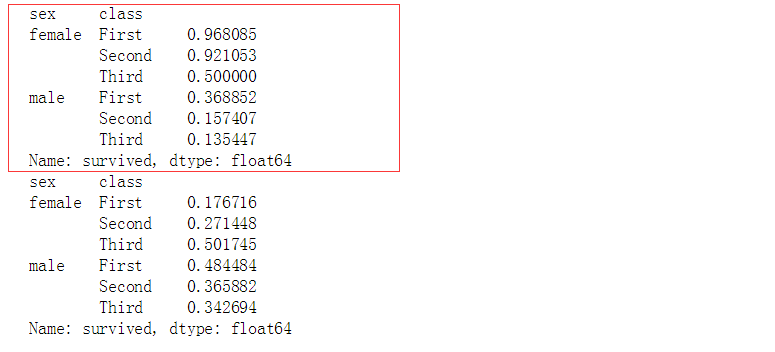
print(titanic.groupby(['sex','class']).mean()['survived'])
print(titanic.groupby(['sex','class']).std()['survived'])
# 计算数据
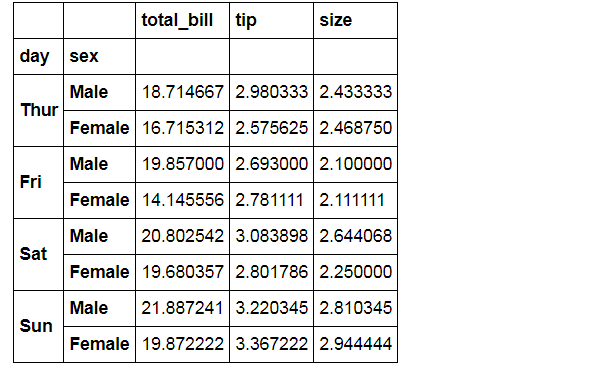
# 1、barplot()
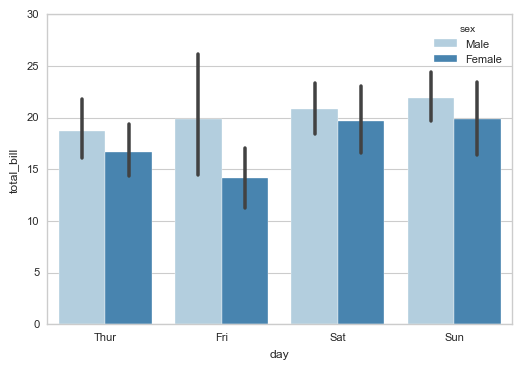
# 柱状图 - 置信区间估计 sns.barplot(x="day", y="total_bill", hue="sex", data=tips,
palette = 'Blues',edgecolor = 'w')
tips.groupby(['day','sex']).mean()
# 计算数据
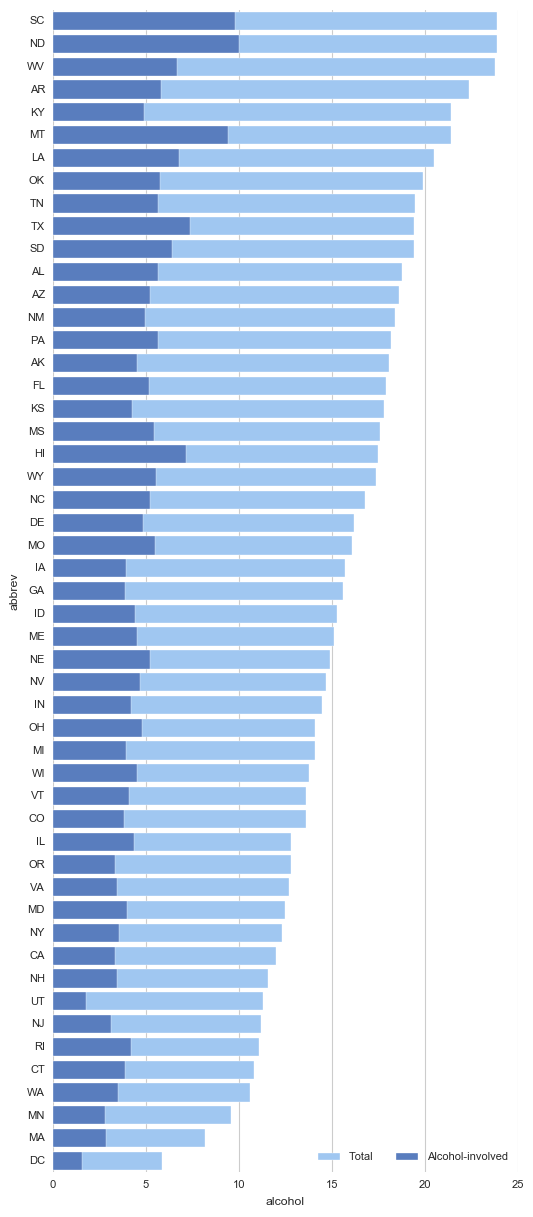
# 1、barplot()
# 柱状图 - 置信区间估计 crashes = sns.load_dataset("car_crashes").sort_values("total", ascending=False)
print(crashes.head())
# 加载数据 f, ax = plt.subplots(figsize=(6, 15))
# 创建图表 sns.set_color_codes("pastel")
sns.barplot(x="total", y="abbrev", data=crashes,
label="Total", color="b",edgecolor = 'w')
# 设置第一个柱状图 sns.set_color_codes("muted")
sns.barplot(x="alcohol", y="abbrev", data=crashes,
label="Alcohol-involved", color="b",edgecolor = 'w')
# 设置第二个柱状图 ax.legend(ncol=2, loc="lower right")
sns.despine(left=True, bottom=True)

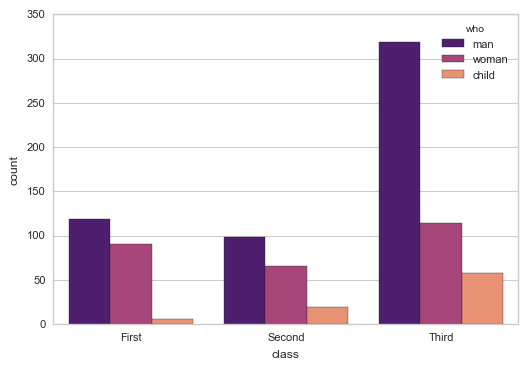
3.2 countplot()计数柱状图
sns.countplot(x="class", hue="who", data=titanic,palette = 'magma')
# 2、countplot() 计数柱状图 sns.countplot(x="class", hue="who", data=titanic,palette = 'magma')
#sns.countplot(y="class", hue="who", data=titanic,palette = 'magma')
# x/y → 以x或者y轴绘图(横向,竖向)
# 用法和barplot相似
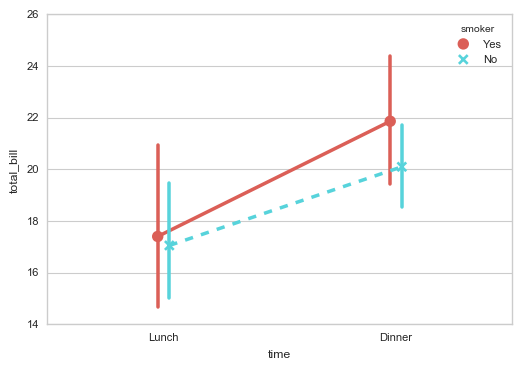
3.3 pointplot()折线图
# 3、pointplot()
# 折线图 - 置信区间估计 sns.pointplot(x="time", y="total_bill", hue = 'smoker',data=tips,
palette = 'hls',
dodge = True, # 设置点是否分开
join = True, # 是否连线
markers=["o", "x"], linestyles=["-", "--"], # 设置点样式、线型
)
tips.groupby(['time','smoker']).mean()['total_bill']
# 计算数据
# # 用法和barplot相似

Python图表数据可视化Seaborn:2. 分类数据可视化-分类散点图|分布图(箱型图|小提琴图|LV图表)|统计图(柱状图|折线图)的更多相关文章
- seaborn分类数据可视化:散点图|箱型图|小提琴图|lv图|柱状图|折线图
一.散点图stripplot( ) 与swarmplot() 1.分类散点图stripplot( ) 用法stripplot(x=None, y=None, hue=None, data=None, ...
- java利用JFreeChart实现各种数据统计图(柱形图,饼图,折线图)
最近在做数据挖掘的课程设计,需要将数据分析的结果很直观的展现给用户,这就要用到数据统计图,要实现这个功能就需要几个第三方包了: 1. jfreechart-1.0.13.jar 2. ...
- java实现各种数据统计图(柱形图,饼图,折线图)
近期在做数据挖掘的课程设计,须要将数据分析的结果非常直观的展现给用户,这就要用到数据统计图,要实现这个功能就须要几个第三方包了: 1. jfreechart-1.0.13.jar 2. ...
- java代码实现highchart与数据库数据结合完整案例分析(二)---折线图
作者原创:未经博主允许不许转载 在上一篇的博客中,展示和分析了如何做一个饼状图,有疑问可以参考上一篇博客. 现在分析和展示折线图的绘制和案例分析, 先展示效果图: 与饼状图不同的是,折线图展现更多的数 ...
- 报表应用系列——图表JFreeChart: 第 4 章 折线图
双击代码全选 1 2 3 4 5 DefaultCategoryDataset dataset = new DefaultCategoryDataset(); dataset.addValue(100 ...
- Python图表数据可视化Seaborn:3. 线性关系数据| 时间线图表| 热图
1. 线性关系数据可视化 lmplot( ) import numpy as np import pandas as pd import matplotlib.pyplot as plt import ...
- Python图表数据可视化Seaborn:1. 风格| 分布数据可视化-直方图| 密度图| 散点图
conda install seaborn 是安装到jupyter那个环境的 1. 整体风格设置 对图表整体颜色.比例等进行风格设置,包括颜色色板等调用系统风格进行数据可视化 set() / se ...
- seaborn分类数据可视化
转载:https://cloud.tencent.com/developer/article/1178368 seaborn针对分类型的数据有专门的可视化函数,这些函数可大致分为三种: 分类数据散点图 ...
- seaborn教程4——分类数据可视化
https://segmentfault.com/a/1190000015310299 Seaborn学习大纲 seaborn的学习内容主要包含以下几个部分: 风格管理 绘图风格设置 颜色风格设置 绘 ...
随机推荐
- 解决ftp客户端连接验证报错Server sent passive reply with unroutable address. Using server address instead
最近在linux服务器安装vsftp服务.经过一轮设置,终于可以连接上了,用winSCP连接,刷新目录就提示这个错误. 解决办法: vim /etc/vsftpd.conf ,编辑配置文件,最后加上 ...
- Json 文件中value的基本类型
在Json中,value的类型只能是以下几种: 1.字符串 2.数字 3.true 或者 false (注意,和字符串不同,没有双引号包裹) 4.null
- Codeforces 1107G Vasya and Maximum Profit [单调栈]
洛谷 Codeforces 我竟然能在有生之年踩标算. 思路 首先考虑暴力:枚举左右端点直接计算. 考虑记录\(sum_x=\sum_{i=1}^x c_i\),设选\([l,r]\)时那个奇怪东西的 ...
- 《JavaWeb从入门到精通》(明日科技,清华大学出版社)
<JavaWeb从入门到精通>(明日科技,清华大学出版社)
- Confluence 6 缓存性能示例
有关 Confluence 的缓存性能如何设置,让我们看看下面的表: 缓存(Caches) % 使用的缓存(Used) % 有效率(Effectiveness) 对象/大小(Objects/Size) ...
- mysql数据库之基本操作和存储引擎
一.知识储备 数据库服务器:一台计算机(对内存要求比较高) 数据库管理系统:如mysql,是一个软件 数据库:oldboy_stu,相当于文件夹 表:student,scholl,class_list ...
- 基于Form组件实现的增删改和基于ModelForm实现的增删改
一.ModelForm的介绍 ModelForm a. class Meta: model, # 对应Model的 fields=None, # 字段 exclude=None, # 排除字段 lab ...
- 论文阅读:Review of Visual Saliency Detection with Comprehensive Information
这篇文章目前发表在arxiv,日期:20180309. 这是一篇针对多种综合性信息的视觉显著性检测的综述文章. 注:有些名词直接贴原文,是因为不翻译更容易理解.也不会逐字逐句都翻译,重要的肯定不会错过 ...
- Python计算器实操
要求: 开发一个简单的python计算器 实现加减乘除及拓号优先级解析 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * ...
- MySQL数据库查询中的特殊命令
第一: MySQL的安装 下载MySQL软件,修改安装路径之后 安装数据库MySQL5.7.18 第一步:数据库MySQL5.7.18可以在官网上下载对应的版本,下载地址:http://www.f ...