Java 抓取网页中的内容【持续更新】
背景:前几天复习Java的时候看到URL类,当时就想写个小程序试试,迫于考试没有动手,今天写了下,感觉还不错
内容1. 抓取网页中的URL
知识点:Java URL+ 正则表达式
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class URLReader {
public static void main(String[] args) throws Exception {
System.out.println("开始!");
Pattern pattern = Pattern.compile("http(s)?://([\\w-]+\\.)+[\\w-]+(/[\\w- ./?%&=]*)?");
URL baidu = new URL("http://www.cnblogs.com/A--Q/");
BufferedReader br = new BufferedReader(new InputStreamReader(baidu.openStream(), "utf-8"));
String inputLine;
while ((inputLine = br.readLine()) != null) {
Matcher matcher = pattern.matcher(inputLine);
while (matcher.find()) {
System.out.println(matcher.group(0));
}
}
br.close();
System.out.println("程序执行结束!");
}
}
效果:
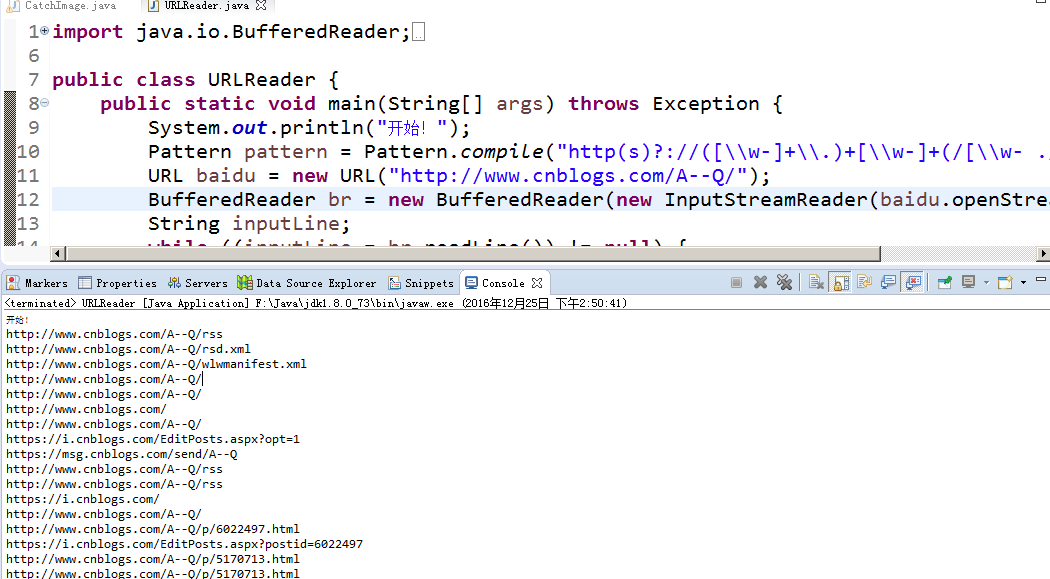
内容2. 抓取网页中的图片
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class CatchImage { private static final String URL = "http://www.cnblogs.com/A--Q/p/5170713.html";
private static final String ECODING = "UTF-8";
private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>";
private static final String IMGSRC_REG = "http:\"?(.*?)(\"|>|\\s+)"; public static void main(String[] args) throws Exception {
System.out.println("start");
CatchImage cm = new CatchImage();
String HTML = cm.getHTML(URL);
List<String> imgUrl = cm.getImageUrl(HTML);
List<String> imgSrc = cm.getImageSrc(imgUrl);
cm.Download(imgSrc);
System.out.println("END");
} private String getHTML(String url) throws Exception {
URL uri = new URL(url);
URLConnection connection = uri.openConnection();
InputStream in = connection.getInputStream();
byte[] buf = new byte[1024];
int length = 0;
StringBuffer sb = new StringBuffer();
while ((length = in.read(buf, 0, buf.length)) > 0) {
sb.append(new String(buf, ECODING));
}
in.close();
return sb.toString();
} private List<String> getImageUrl(String HTML) {
Matcher matcher = Pattern.compile(IMGURL_REG).matcher(HTML);
List<String> listImgUrl = new ArrayList<String>();
while (matcher.find()) {
listImgUrl.add(matcher.group());
}
return listImgUrl;
} private List<String> getImageSrc(List<String> listImageUrl) {
List<String> listImgSrc = new ArrayList<String>();
for (String image : listImageUrl) {
Matcher matcher = Pattern.compile(IMGSRC_REG).matcher(image);
while (matcher.find()) {
listImgSrc.add(matcher.group().substring(0, matcher.group().length() - 1));
}
}
return listImgSrc;
} private void Download(List<String> listImgSrc) {
try {
for (String url : listImgSrc) {
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File(imageName));
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
in.close();
fo.close();
System.out.println(imageName + "下载完成");
}
} catch (Exception e) {
System.out.println("下载失败");
}
} }
Java 抓取网页中的内容【持续更新】的更多相关文章
- php抓取网页中的内容
以下就是几种常用的用php抓取网页中的内容的方法.1.file_get_contentsPHP代码代码如下:>>>>>>>>>>>&g ...
- 走过路过不要错过~教你用java抓取网页中你想要的东东~~
学习了正则之后,打算用java玩一玩,所以就决定用它来实现一个好玩的idea import java.io.BufferedReader; import java.io.IOException; im ...
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
- Java抓取网页数据(原网页+Javascript返回数据)
有时候由于种种原因,我们需要采集某个网站的数据,但由于不同网站对数据的显示方式略有不同! 本文就用Java给大家演示如何抓取网站的数据:(1)抓取原网页数据:(2)抓取网页Javascript返回的数 ...
- Java抓取网页数据(原来的页面+Javascript返回数据)
转载请注明出处! 原文链接:http://blog.csdn.net/zgyulongfei/article/details/7909006 有时候因为种种原因,我们须要採集某个站点的数据,但因为不同 ...
- 浅谈如何使用python抓取网页中的动态数据
我们经常会发现网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的.所以也就引出了什么是动态数据的概念, 动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到 ...
- Python抓取网页中的图片到本地
今天在网上找了个从网页中通过图片URL,抓取图片并保存到本地的例子: #!/usr/bin/env python # -*- coding:utf- -*- # Author: xixihuang # ...
- python 解决抓取网页中的中文显示乱码问题
关于爬虫乱码有很多各式各样的问题,这里不仅是中文乱码,编码转换.还包括一些如日文.韩文 .俄文.藏文之类的乱码处理,因为解决方式是一致的,故在此统一说明. 网络爬虫出现乱码的原因 源网页编码和爬取下来 ...
- java 抓取网页图片
import java.io.File; import java.io.FileOutputStream; import java.io.InputStream; import java.io.Out ...
随机推荐
- Unity插件之Unity调用C#编译的DLL
Unity插件分为两种:托管插件(Managed Plugins)和本地插件(Native Plugins).本文先来说说Unity中的托管插件,本地插件的文章留到下一篇文章再说. 有时候我们会有这样 ...
- 在output 子句和 scope_identity() 混合使用的时候的注意事项
无意睹到一篇旧文档 SR0008:考虑使用 SCOPE_IDENTITY 代替 @@IDENTITY :https://msdn.microsoft.com/zh-cn/library/dd17212 ...
- java.lang.UnsatisfiedLinkError: %1 不是有效的 Win32 应用程序。
JNA 调用 dll 库时,保错: ///////////////// 通过 JNA 引入 DLL 库 //////////// /** * ID_FprCap.dll 负责指纹的采集, 指纹仪的初始 ...
- Linux工具快速教程
看到一linux中常用工具使用教程,非常好.猛击下面的地址 github:https://github.com/me115/linuxtools_rst 在线文档:http://linuxtools- ...
- ultraiso制作大于4GB的镜像的启动盘
ultraiso这个软件用来做启动盘很方便, 一般linux啦, windows啦, 神马的都用他来做, 但是, 因为ubuntu一般只有1-2GB, win桌面版一般也就3GB左右, 所以不必考虑这 ...
- NYOJ----776删除元素
删除元素 时间限制:1000 ms | 内存限制:65535 KB 描述 题意很简单,给一个长度为n的序列,问至少删除序列中多少个数,使得删除后的序列中的最大值<= 2*最小值 输入 多组测 ...
- kettle中变量的设置和使用介绍
有没有能统一管理一个参数,然后让所有的transformation和job都可以读到呢? 答案是有 1.首先,打开.kettle\kettle.properties(个人主机是:C:\Users\fo ...
- STL bind1st bind2nd详解
STL bind1st bind2nd详解 先不要被吓到,其实这两个配接器很简单.首先,他们都在头文件<functional>中定义.其次,bind就是绑定的意思,而1st就代表fir ...
- [LeetCode] Move Zeroes 移动零
Given an array nums, write a function to move all 0's to the end of it while maintaining the relativ ...
- [LeetCode] Insert Interval 插入区间
Given a set of non-overlapping intervals, insert a new interval into the intervals (merge if necessa ...