论文阅读(XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network)
XiangBai——【AAAI2017】TextBoxes:A Fast Text Detector with a Single Deep Neural Network
目录
- 作者和相关链接
- 方法概括
- 创新点和贡献
- 方法细节
- 实验结果
- 总结与收获点
作者和相关链接
- 作者

方法概括
文章核心:
- 改进版的SSD用来解决文字检测问题
端到端识别的pipeline:
- Step 1: 图像输入到修改版SSD网络中 + 非极大值抑制(NMS)→ 输出候选检测结果
- Step 2: 候选检测结果 + CRNN进行单词识别 → 新的检测结果 + 识别结果
方法的性能
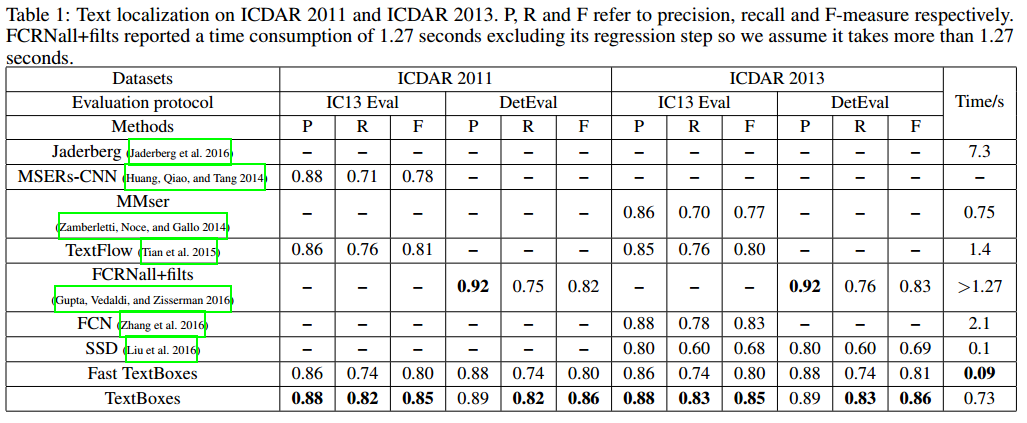
- 多尺度版本-定位:ICDAR2011-0.85(f),ICDAR2013-0.85(f),0.73s/per image
- 单尺度版本-定位:ICDAR2011-0.80(f),ICDAR2013-0.80(f),0.09s/per image
改进的SSD的地方:
- default box的长宽比进行修改(长条形),使其更适合文字检测(单词)
- 作为classifier的卷积滤波器大小从3*3变成1*5,更适合文字检测
- SSD原来为多类检测问题,现在转为单类检测问题
- 从输入图像为单尺度变为多尺度
- 利用识别来调整检测的结果(text spotting)
创新点和贡献
创新点
- 把SSD进行修改,使其适用于文字检测(SSD本身对小目标识别不鲁棒)
贡献
- 提出一个端到端可训练的非常简洁的文字检测框架(SSD本身是single stage的,不像普通方法需要有多步骤组成)
- 提出一个完整的端到端识别的文字检测+识别框架
- 实验方法结果好,速度快
方法细节
相关背景——文字识别的任务
- 文字检测
- 文字/单词识别
- 端到端文字识别 = 文字 + 识别
- text spotting:和文字检测不同的是,可以利用带字典的文字识别进行调整检测结果,最终是用文字检测的结果进行评判
相关背景——SSD
- SSD的网络结构

- SSD的default box
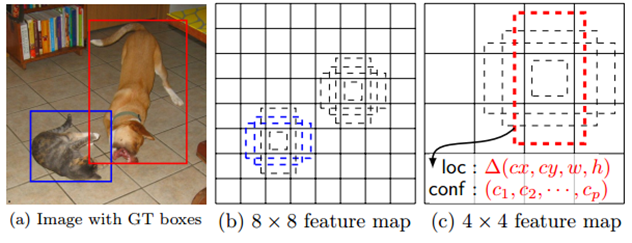
Fig. 1: SSD framework. (a) SSD only needs an input image and ground truth boxes for each object during training. In a convolutional fashion, we evaluate a small set (e.g. 4) of default boxes of different aspect ratios at each location in several feature maps with different scales (e.g. 8 × 8 and 4 × 4 in (b) and (c)). For each default box, we predict both the shape offsets and the confidences for all object categories ((c1; c2; · · · ; cp)). At training time, we first match these default boxes to the ground truth boxes. For example, we have matched two default boxes with the cat and one with the dog, which are treated as positives and the rest as negatives. The model loss is a weighted sum between localization loss (e.g. Smooth L1 [6]) and confidence loss (e.g. Softmax).
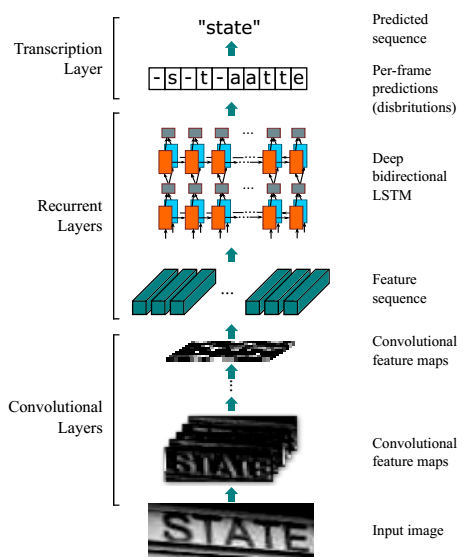
相关背景——CRNN
- CRNN的网络结构
TextBoxes与SSD网络结构对比
- TextBoxes网络结构
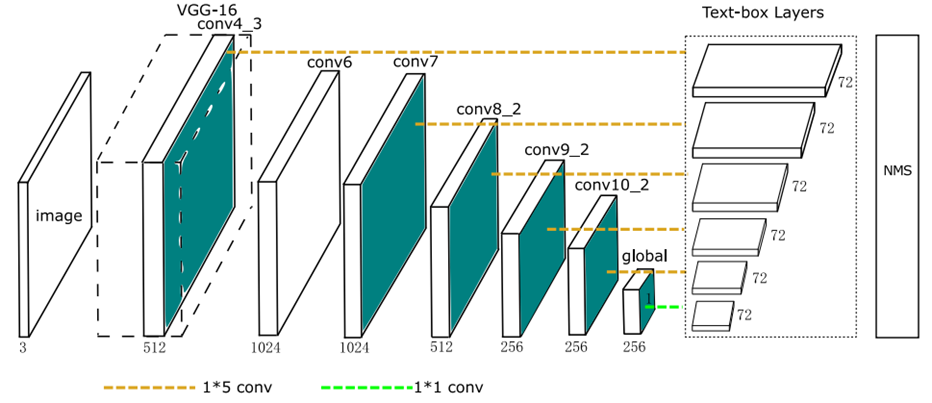
- SSD 网络结构

Text-box layers的输出
(与SSD一样)
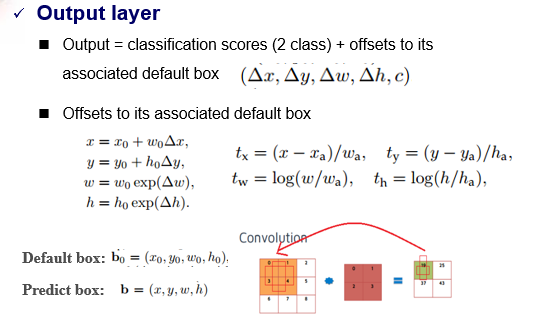
TextBoxes与SSD不同的修改细节
default box长宽比


(右边图)Figure 2: Illustration of default boxes for a 4*4 grid. For better visualization, only a column of default boxes whose aspect ratios 1 and 5 are plotted. The rest of the aspect ratios are 2,3,7 and 10, which are placed similarly. The black (aspect ratio: 5) and blue (ar: 1) default boxes are centered in their cells. The green (ar: 5) and red (ar: 1) boxes have the same aspect ratios and a vertical offset(half of the height of the cell) to the grid center respectively
卷积滤波器大小
损失函数
多尺度输入
TextBoxes+CRNN进行识别




实验结果
定位
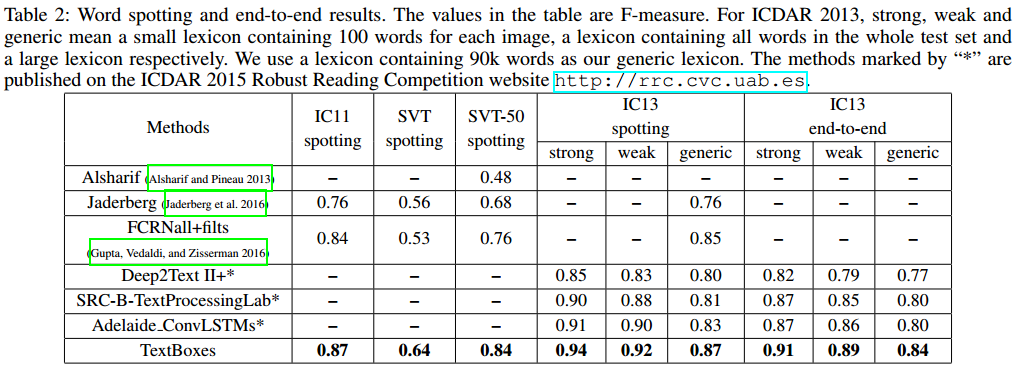
text spotting和端到端识别
效果展示

总结与收获点
- 原始的SSD是无法直接用在文字上的,需要进行许多修改才能达到比较好的效果,这一点作者在实验中也证明了
- 现在越来越多用Faster r-cnn,ssd,yolo,这类一般的目标检测方法进行修改后用在特定的目标检测上(例如文字,行人),这些方法不但速度快,而且鲁棒性也高,很重要一点,越来越倾向于端到端训练,这是因为single stage和传统的step-wise的方法相比有很多优势,例如,总体训练简单,没有stage衔接上的性能损耗,没有逐步的误差积累等等;
论文阅读(XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network)的更多相关文章
- XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network
XiangBai--[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- 论文阅读笔记三十:One pixel attack for fooling deep neural networks(CVPR2017)
论文源址:https://arxiv.org/abs/1710.08864 tensorflow代码: https://github.com/Hyperparticle/one-pixel-attac ...
- 论文翻译:2020_RESIDUAL ACOUSTIC ECHO SUPPRESSION BASED ON EFFICIENT MULTI-TASK CONVOLUTIONAL NEURAL NETWORK
论文翻译:https://arxiv.53yu.com/abs/2009.13931 基于高效多任务卷积神经网络的残余回声抑制 摘要 在语音通信系统中,回声会降低用户体验,需要对其进行彻底抑制.提出了 ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- Deep Learning 28:读论文“Multi Column Deep Neural Network for Traffic Sign Classification”-------MCDNN 简单理解
读这篇论文“ Multi Column Deep Neural Network for Traffic Sign Classification”是为了更加理解,论文“Multi-column Deep ...
- 论文翻译:2022_PACDNN: A phase-aware composite deep neural network for speech enhancement
论文地址:PACDNN:一种用于语音增强的相位感知复合深度神经网络 引用格式:Hasannezhad M,Yu H,Zhu W P,et al. PACDNN: A phase-aware compo ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文解读(GCC)《GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training》
论文信息 论文标题:GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training论文作者:Jiezhong Qiu, Qibi ...
随机推荐
- perl 里面如何写出阅读友好的代码提示
在我们使用别人写好的程序时,经常会使用-h 之类的东西查看一下简单的帮助手册或者说明信息: 对于perl 语言而言,写起来简单,经常随手一写,解决了当时的问题,但是过几天去看,你都不知道这个脚本该怎么 ...
- 深度讲解 .net session 过期机制
[参考]net session过期 原理及解决办法 [参考]深入理解session过期机制
- 蜕变成蝶~Linux设备驱动之异步通知和异步I/O
在设备驱动中使用异步通知可以使得对设备的访问可进行时,由驱动主动通知应用程序进行访问.因此,使用无阻塞I/O的应用程序无需轮询设备是否可访问,而阻塞访问也可以被类似“中断”的异步通知所取代.异步通知类 ...
- git报错You are not allowed to force push code to a protected branch on this project
当我们有时候回滚了代码,想强制push到远程仓库的时候, git push origin --force 会报如下错误: You are not allowed to force push code ...
- [原]Jenkins(十七) jenkins再出发之配置SVN
创建一个demo project 配置SVN: 配置build project
- I - The lazy programmer 贪心+优先队列
来源poj2970 A new web-design studio, called SMART (Simply Masters of ART), employs two people. The fir ...
- 萌新 学习 vuex
vuex官网文档 https://vuex.vuejs.org/zh-cn/ 注: Mutation事件使用commit触发, Actions事件使用dispatch触发 安装 npm install ...
- linux 的基本操作(编写shell 脚本)
终于到shell 脚本这章了,在以前笔者卖了好多关子说shell脚本怎么怎么重要,确实shell脚本在linux系统管理员的运维工作中非常非常重要.下面笔者就带你正式进入shell脚本的世界吧. 到现 ...
- Linux 的基本操作(系统用户及用户组的管理)
[认识/etc/passwd和/etc/shadow] 这两个文件可以说是linux系统中最重要的文件之一.如果没有这两个文件或者这两个文件出问题,则你是无法正常登录linux系统的. /etc/pa ...
- 向comboboxEdit中动态添加数据库中保存的用户自定义单位制的名称
if (radioGroup1.SelectedIndex == 2) { bool _Flag = true; sm.SetLciVisible(lciDelete, _Flag); sm.SetL ...