XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network
XiangBai——【AAAI2017】TextBoxes:A Fast Text Detector with a Single Deep Neural Network
目录
- 作者和相关链接
- 方法概括
- 创新点和贡献
- 方法细节
- 实验结果
- 总结与收获点
作者和相关链接
- 作者

方法概括
文章核心:
- 改进版的SSD用来解决文字检测问题
端到端识别的pipeline:
- Step 1: 图像输入到修改版SSD网络中 + 非极大值抑制(NMS)→ 输出候选检测结果
- Step 2: 候选检测结果 + CRNN进行单词识别 → 新的检测结果 + 识别结果
方法的性能
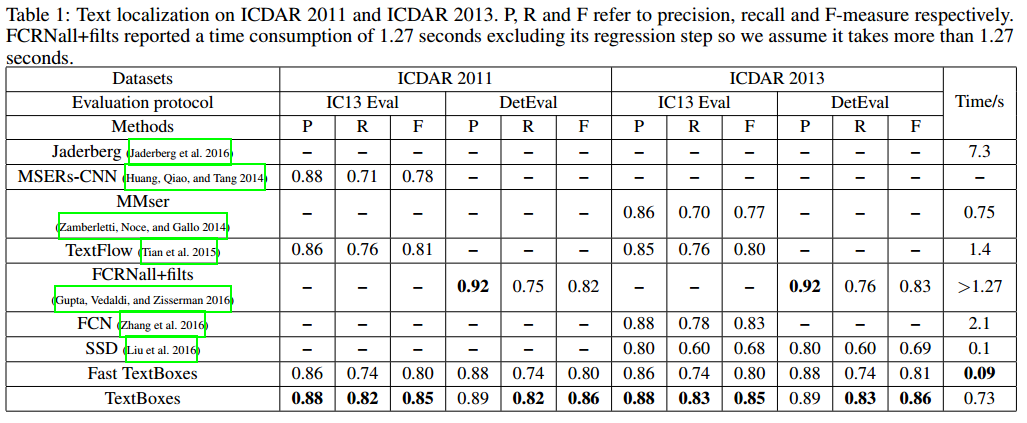
- 多尺度版本-定位:ICDAR2011-0.85(f),ICDAR2013-0.85(f),0.73s/per image
- 单尺度版本-定位:ICDAR2011-0.80(f),ICDAR2013-0.80(f),0.09s/per image
改进的SSD的地方:
- default box的长宽比进行修改(长条形),使其更适合文字检测(单词)
- 作为classifier的卷积滤波器大小从3*3变成1*5,更适合文字检测
- SSD原来为多类检测问题,现在转为单类检测问题
- 从输入图像为单尺度变为多尺度
- 利用识别来调整检测的结果(text spotting)
创新点和贡献
创新点
- 把SSD进行修改,使其适用于文字检测(SSD本身对小目标识别不鲁棒)
贡献
- 提出一个端到端可训练的非常简洁的文字检测框架(SSD本身是single stage的,不像普通方法需要有多步骤组成)
- 提出一个完整的端到端识别的文字检测+识别框架
- 实验方法结果好,速度快
方法细节
相关背景——文字识别的任务
- 文字检测
- 文字/单词识别
- 端到端文字识别 = 文字 + 识别
- text spotting:和文字检测不同的是,可以利用带字典的文字识别进行调整检测结果,最终是用文字检测的结果进行评判
相关背景——SSD
- SSD的网络结构

- SSD的default box
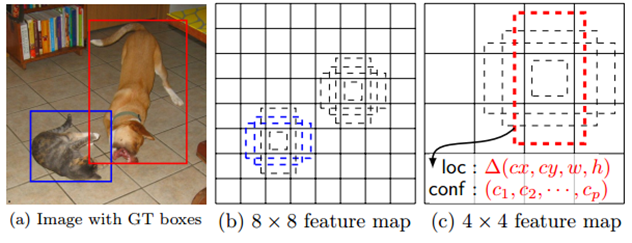
Fig. 1: SSD framework. (a) SSD only needs an input image and ground truth boxes for each object during training. In a convolutional fashion, we evaluate a small set (e.g. 4) of default boxes of different aspect ratios at each location in several feature maps with different scales (e.g. 8 × 8 and 4 × 4 in (b) and (c)). For each default box, we predict both the shape offsets and the confidences for all object categories ((c1; c2; · · · ; cp)). At training time, we first match these default boxes to the ground truth boxes. For example, we have matched two default boxes with the cat and one with the dog, which are treated as positives and the rest as negatives. The model loss is a weighted sum between localization loss (e.g. Smooth L1 [6]) and confidence loss (e.g. Softmax).
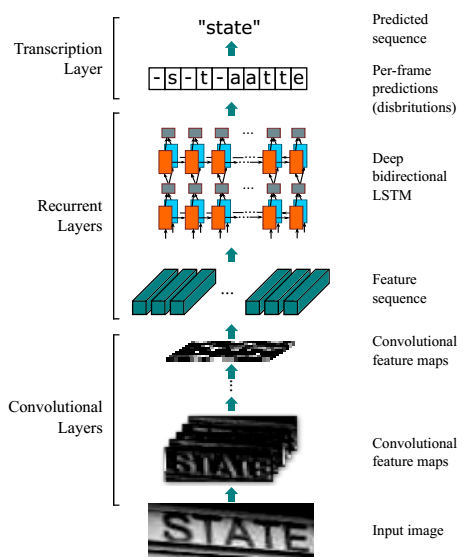
相关背景——CRNN
- CRNN的网络结构
TextBoxes与SSD网络结构对比
- TextBoxes网络结构
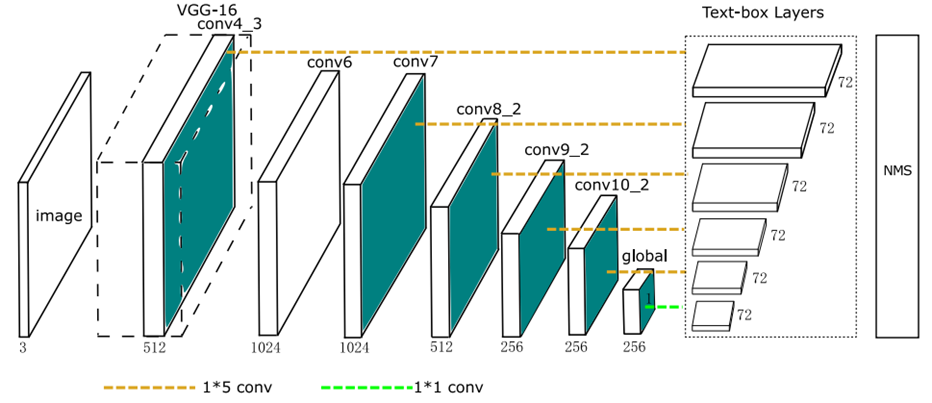
- SSD 网络结构

Text-box layers的输出
(与SSD一样)
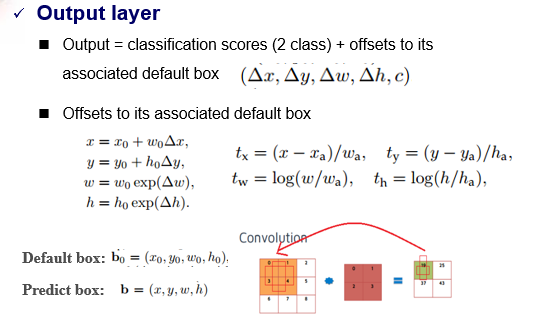
TextBoxes与SSD不同的修改细节
default box长宽比


(右边图)Figure 2: Illustration of default boxes for a 4*4 grid. For better visualization, only a column of default boxes whose aspect ratios 1 and 5 are plotted. The rest of the aspect ratios are 2,3,7 and 10, which are placed similarly. The black (aspect ratio: 5) and blue (ar: 1) default boxes are centered in their cells. The green (ar: 5) and red (ar: 1) boxes have the same aspect ratios and a vertical offset(half of the height of the cell) to the grid center respectively
卷积滤波器大小
损失函数
多尺度输入
TextBoxes+CRNN进行识别




实验结果
定位
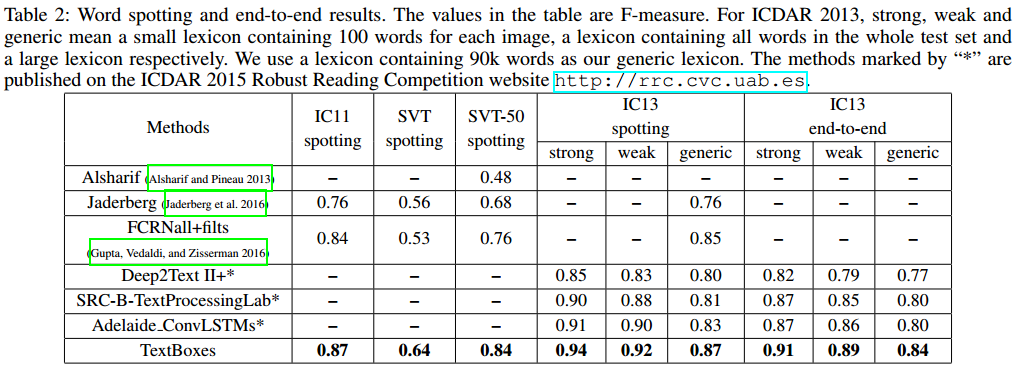
text spotting和端到端识别
效果展示

总结与收获点
- 原始的SSD是无法直接用在文字上的,需要进行许多修改才能达到比较好的效果,这一点作者在实验中也证明了
- 现在越来越多用Faster r-cnn,ssd,yolo,这类一般的目标检测方法进行修改后用在特定的目标检测上(例如文字,行人),这些方法不但速度快,而且鲁棒性也高,很重要一点,越来越倾向于端到端训练,这是因为single stage和传统的step-wise的方法相比有很多优势,例如,总体训练简单,没有stage衔接上的性能损耗,没有逐步的误差积累等等;
XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network的更多相关文章
- 论文阅读(XiangBai——【AAAI2017】TextBoxes_A Fast Text Detector with a Single Deep Neural Network)
XiangBai——[AAAI2017]TextBoxes:A Fast Text Detector with a Single Deep Neural Network 目录 作者和相关链接 方法概括 ...
- XiangBai——【CVPR2018】Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
XiangBai——[CVPR2018]Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentat ...
- 论文阅读(XiangBai——【CVPR2017】Detecting Oriented Text in Natural Images by Linking Segments)
XiangBai——[CVPR2017]Detecting Oriented Text in Natural Images by link Segments 目录 作者和相关链接 方法概括 方法细节 ...
- 【RS】Automatic recommendation technology for learning resources with convolutional neural network - 基于卷积神经网络的学习资源自动推荐技术
[论文标题]Automatic recommendation technology for learning resources with convolutional neural network ( ...
- 论文阅读(XiangBai——【PAMI2018】ASTER_An Attentional Scene Text Recognizer with Flexible Rectification )
目录 XiangBai--[PAMI2018]ASTER_An Attentional Scene Text Recognizer with Flexible Rectification 作者和论文 ...
- 论文阅读(Lukas Neuman——【ICDAR2015】Efficient Scene Text Localization and Recognition with Local Character Refinement)
Lukas Neuman--[ICDAR2015]Efficient Scene Text Localization and Recognition with Local Character Refi ...
- 论文阅读(Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences)
Weilin Huang--[AAAI2016]Reading Scene Text in Deep Convolutional Sequences 目录 作者和相关链接 方法概括 创新点和贡献 方法 ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 论文阅读笔记(三)【AAAI2017】:Learning Heterogeneous Dictionary Pair with Feature Projection Matrix for Pedestrian Video Retrieval via Single Query Image
Introduction (1)IVPR问题: 根据一张图片从视频中识别出行人的方法称为 image to video person re-id(IVPR) 应用: ① 通过嫌犯照片,从视频中识别出嫌 ...
随机推荐
- JS:XML
一 IE中的XML //1.创建XMLDOM对象 //创建XMLDOM对象 var xmlDom = new ActiveXObject("MSXML2.DOMDocument.6.0&qu ...
- C# DataTable 行转列
#region 根据datatable获得列名 /// <summary> /// 根据datatable获得列名 /// </summary> /// <param n ...
- Docking Windows Phone controls to the bottom of a StackPanel
<Grid> <Grid.RowDefinitions> <RowDefinition Height="*" /> <RowDefinit ...
- *HDU1251 字典树
统计难题 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131070/65535 K (Java/Others)Total Submi ...
- 解决IE(IE6/IE7/IE8)不兼容HTML5标签的方法
方式一:Coding JavaScript <!--[if lt IE9]> <script> (function() { var e = "abbr, articl ...
- C#的7个原则
C#的七个原则如下: 1.单一职责原则(Single Responsibility Principle, SRP):一个类只负责一个功能领域中的相应职责. 2.开闭原则(Open-Closed Pri ...
- 【5集iCore3_ADP演示视频】5-5 iCore3应用开发平台示波器和信号源校准
iCore3双核心应用开发平台基于iCore3双核心板,包含ARM.FPGA.7寸液晶屏.双通道数字示波器.任意波发生器.电压表等模块,是一款专为电子爱好者设计的综合性电子学习系统. [视频简介]本视 ...
- 百钱买百鸡问题 php版本
/* * 百钱买百鸡问题 * * 我国古代数学家张丘建在<算经>一书中曾提出过著名的“百钱买百鸡”问题,该问题叙述如下:鸡翁一,值钱五:鸡母一,值钱三:鸡雏三,值钱一:百钱买百鸡,则翁.母 ...
- android删除无用资源文件的python脚本
随着android项目的进行,如果没有及时删除无用的资源时安装包会越来越大,是时候整理一下废弃资源缩小压缩包了,少年! 其实判断一个资源(drawable,layout)是否没有被使用很简单,文件名( ...
- Java命令行解析:apache commons-cli
http://commons.apache.org/proper/commons-cli/usage.html Apache Commons CLI用于解析命令行选项,也可以输出详细的选项说明信息. ...