Word2vec之CBOW
一、Word2vec
word2vec是Google与2013年开源推出的一个用于获取word vecter的工具包,利用神经网络为单词寻找一个连续向量看空间中的表示。word2vec是将单词转换为向量的算法,该算法使得具有相似含义的单词表示为相互靠近的向量。
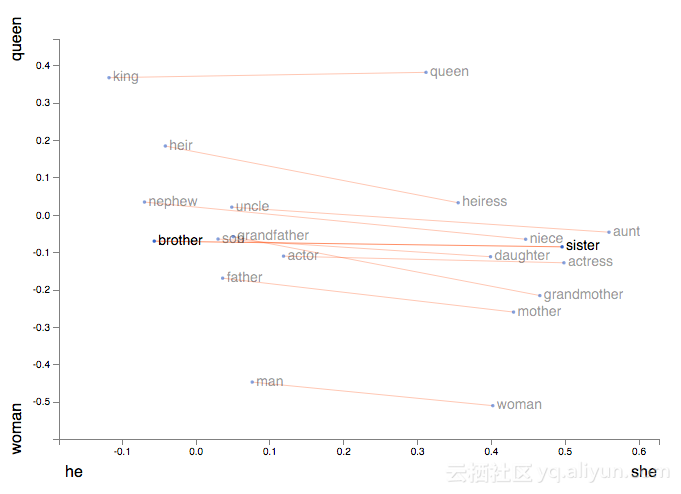
此外,它能让我们使用向量算法来处理类别,例如着名等式King−Man+Woman=Queen。
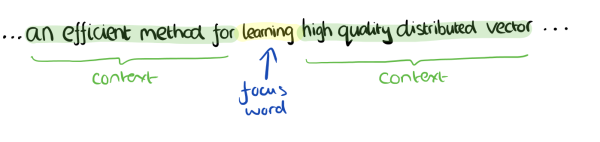
word2vec一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型:
1、CBOW:根据中心词周围的词来预测中心词,有negative sample和Huffman两种加速算法;
2、Skip-Gram:根据中心词来预测周围词;
二者的结构十分相似,理解了CBOW,对于Skip-Gram也就基本理解了。下面主要来讲讲CBOW。
来源:word2vec原理(一) CBOW与Skip-Gram模型基础
二、CBOW

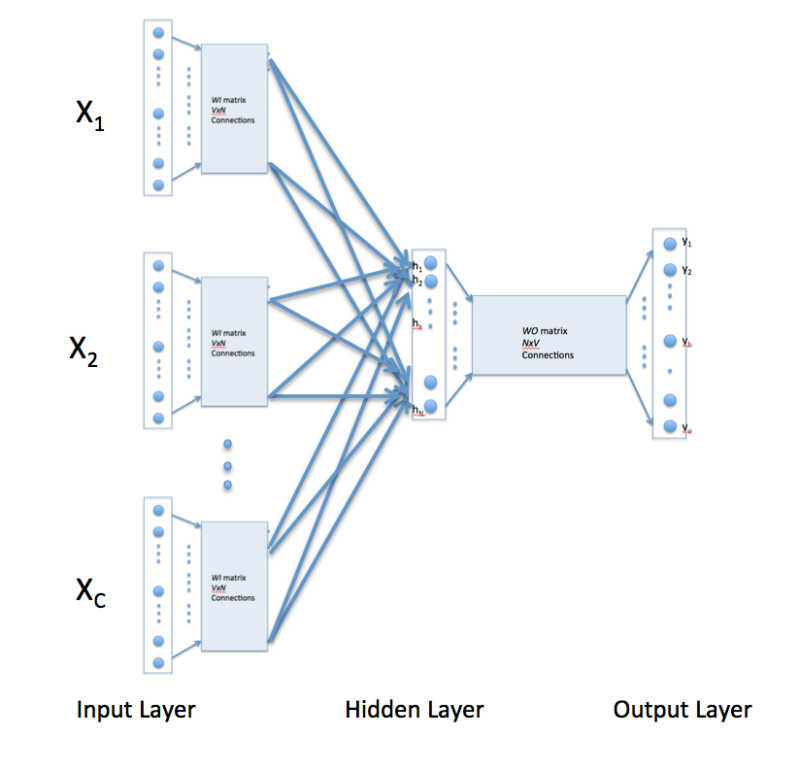
上图为CBOW的主要结构形式。对于上图,假设单词的向量空间维度为V,上下文单词个数为C,求解两个权重均值W和W'。对于上图的解释如下:
1、输入层:上下文单词的onehot形式;
2、隐藏层:将输入层所有onehot后的向量乘以第一个权重矩阵W(所有的权重矩阵相同,即共享权重矩阵),然后相加求平均作为隐藏层向量,该向量的大小与输入层的每一个样本大小相同;
3、输出层:将隐藏层向量乘以第二权重矩阵W‘,得到一个V维的向量,然后再通过激活函数(softmax)得到每一维词的概率分布,概率最大的位置所指示的单词为预测出的中间词;
4、一般使用使用的损失函数为交叉熵损失函数,采用梯度下降的方式来更新W和W’;这实际上是一个假任务,即我们需要的只是第一个权重矩阵W。得到第一个矩阵W之后,我们就能得到每个单词的词向量了。
更具体的结构以及流程如下:
来源:究竟什么是Word2vec ? Skip-Gram模型和Continuous Bag of Words(CBOW)模型 ?
I drink coffee everyday
我们使用的window size设为2。
三、word2vec的python使用
可以使用python中的gensim库。
具体可以见谈谈Word2Vec的CBOW模型最后一个部分,以及官网https://radimrehurek.com/gensim/models/word2vec.html
Word2vec之CBOW的更多相关文章
- DL4NLP——词表示模型(二)基于神经网络的模型:NPLM;word2vec(CBOW/Skip-gram)
本文简述了以下内容: 神经概率语言模型NPLM,训练语言模型并同时得到词表示 word2vec:CBOW / Skip-gram,直接以得到词表示为目标的模型 (一)原始CBOW(Continuous ...
- word2vec原理CBOW与Skip-Gram模型基础
转自http://www.cnblogs.com/pinard/p/7160330.html刘建平Pinard word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量 ...
- DL4NLP——词表示模型(三)word2vec(CBOW/Skip-gram)的加速:Hierarchical Softmax与Negative Sampling
上篇博文提到,原始的CBOW / Skip-gram模型虽然去掉了NPLM中的隐藏层从而减少了耗时,但由于输出层仍然是softmax(),所以实际上依然“impractical”.所以接下来就介绍一下 ...
- word2vec模型cbow与skip-gram的比较
cbow和skip-gram都是在word2vec中用于将文本进行向量表示的实现方法,具体的算法实现细节可以去看word2vec的原理介绍文章.我们这里大体讲下两者的区别,尤其注意在使用当中的不同特点 ...
- 词表征 2:word2vec、CBoW、Skip-Gram、Negative Sampling、Hierarchical Softmax
原文地址:https://www.jianshu.com/p/5a896955abf0 2)基于迭代的方法直接学 相较于基于SVD的方法直接捕获所有共现值的做法,基于迭代的方法一次只捕获一个窗口内的词 ...
- word2vec (CBOW、分层softmax、负采样)
本文介绍 wordvec的概念 语言模型训练的两种模型CBOW+skip gram word2vec 优化的两种方法:层次softmax+负采样 gensim word2vec默认用的模型和方法 未经 ...
- NLP中word2vec的CBOW模型和Skip-Gram模型
参考:tensorflow_manual_cn.pdf Page83 例子(数据集): the quick brown fox jumped over the lazy dog. (1)CBO ...
- word2vec原理(一) CBOW与Skip-Gram模型基础
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec原理(一) CBOW与Skip-Gram模型基础——转载自刘建平Pinard
转载来源:http://www.cnblogs.com/pinard/p/7160330.html word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与 ...
随机推荐
- 微信小程序【消息推送服务器认证C# WebAPI】
参考微信开发文档: https://developers.weixin.qq.com/miniprogram/dev/api/custommsg/callback_help.html 代码可用 /// ...
- Angularjs实例应用
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- dedecms基础整理,
需求3: 在添加某个商品的时候,我们希望多一个信息,就是付费方式,还希望多一个邮资信息,我们又该怎样处理? 引出修改内容模型的问题 每个模型的字段管理的所有信息 都属于附加表. 步骤: 点击 核心-& ...
- fastRPC升级
根据fastRPC的应用测试,用DB操作发布服务测试,对已经存在的问题进行升级; 主要修改内容: 1.添加自定义加载器,根据配置文件,允许设置目录,放置第三方jar包,解决打包问题 2.默认情况,服务 ...
- linux运维、架构之路-shell编程(二)
一.流程控制语句 1.if语句 ①if单分支:一个条件一个结果 1 2 3 4 if 条件 then 命令 fi ②if双分支:一个条件两个结果 1 2 3 4 5 6 if 条件 ...
- navicat for MySQL连接本地数据库时报1045错误的解决方法
navicat for MySQL 连接本地数据库出现1045错误 如下图: 说明连接mysql时数据库密码错误,需要修改密码后才可解决问题: 解决步骤如下: 1.首先打开命令行:开始->运行- ...
- vue服务端渲染添加缓存
缓存 虽然 Vue 的服务器端渲染(SSR)相当快速,但是由于创建组件实例和虚拟 DOM 节点的开销,无法与纯基于字符串拼接(pure string-based)的模板的性能相当.在 SSR 性能至关 ...
- 发布django项目
supervisor需要用到的技术 1. nginx反向代理 2. nginx负载均衡 3. uwsgi 4. supervisor 5. virtualenv 安装nginx 详情参考 https: ...
- MySQL学习路线图
- PLC编码规范
PC在编码规范方面比PLC要好很多.既然它们都是编程语言,那么PC方面的规范是否可以用与PLC呢?答案是肯定的,但需要作取舍.下面规范中的大部分可以用于一般PLC,其中有些只是针对西门子博途,使用时需 ...