python爬虫:爬取链家深圳全部二手房的详细信息
1、问题描述:
爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文件中
2、思路分析:
(1)目标网址:https://sz.lianjia.com/ershoufang/
(2)代码结构:
class LianjiaSpider(object):
def __init__(self):
def getMaxPage(self, url): # 获取maxPage
def parsePage(self, url): # 解析每个page,获取每个huose的Link
def parseDetail(self, url): # 根据Link,获取每个house的详细信息
(3) init(self)初始化函数
· hearders用到了fake_useragent库,用来随机生成请求头。
· datas空列表,用于保存爬取的数据。
def __init__(self):
self.headers = {"User-Agent": UserAgent().random}
self.datas = list()
(4) getMaxPage()函数
主要用来获取二手房页面的最大页数.
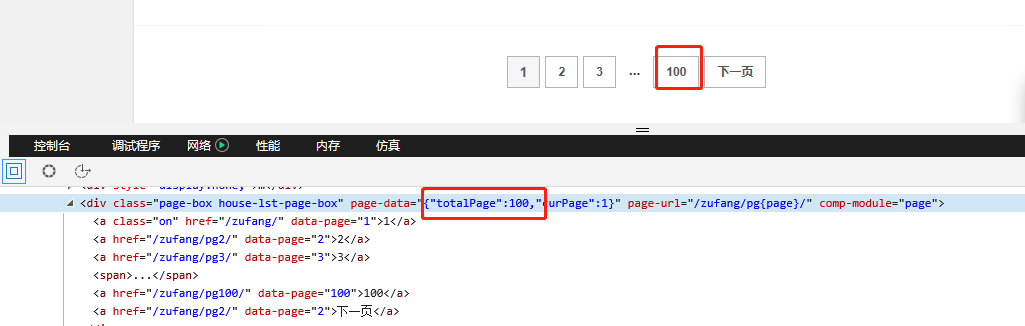
def getMaxPage(self, url):
response = requests.get(url, headers = self.headers)
if response.status_code == 200:
source = response.text
soup = BeautifulSoup(source, "html.parser")
pageData = soup.find("div", class_ = "page-box house-lst-page-box")["page-data"]
# pageData = '{"totalPage":100,"curPage":1}',通过eval()函数把字符串转换为字典
maxPage = eval(pageData)["totalPage"]
return maxPage
else:
print("Fail status: {}".format(response.status_code))
return None
(5)parsePage()函数
主要是用来进行翻页的操作,得到每一页的所有二手房的Links链接。它通过利用一个for循环来重构 url实现翻页操作,而循环最大页数就是通过上面的 getMaxPage() 来获取到。
def parsePage(self, url):
maxPage = self.getMaxPage(url)
# 解析每个page,获取每个二手房的链接
for pageNum in range(1, maxPage+1 ):
url = "https://sz.lianjia.com/ershoufang/pg{}/".format(pageNum)
print("当前正在爬取: {}".format(url))
response = requests.get(url, headers = self.headers)
soup = BeautifulSoup(response.text, "html.parser")
links = soup.find_all("div", class_ = "info clear")
for i in links:
link = i.find("a")["href"] #每个<info clear>标签有很多<a>,而我们只需要第一个,所以用find
detail = self.parseDetail(link)
self.datas.append(detail)
(6)parseDetail()函数
根据parsePage()函数获取的二手房Link链接,向该链接发送请求,获取出详细页面信息。
def parseDetail(self, url):
response = requests.get(url, headers = self.headers)
detail = {}
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
detail["价格"] = soup.find("span", class_ = "total").text
detail["单价"] = soup.find("span", class_ = "unitPriceValue").text
detail["小区"] = soup.find("div", class_ = "communityName").find("a", class_ = "info").text
detail["位置"] = soup.find("div", class_="areaName").find("span", class_="info").text
detail["地铁"] = soup.find("div", class_="areaName").find("a", class_="supplement").text
base = soup.find("div", class_ = "base").find_all("li") # 基本信息
detail["户型"] = base[0].text[4:]
detail["面积"] = base[2].text[4:]
detail["朝向"] = base[6].text[4:]
detail["电梯"] = base[10].text[4:]
return detail
else:
return None
(7)将数据存储到CSV文件中
这里用到了 pandas 库的 DataFrame() 方法,它默认的是按照列名的字典顺序排序的。想要自定义列的顺序,可以加columns字段。
# 将所有爬取的二手房数据存储到csv文件中
data = pd.DataFrame(self.datas)
# columns字段:自定义列的顺序(DataFrame默认按列名的字典序排序)
columns = ["小区", "户型", "面积", "价格", "单价", "朝向", "电梯", "位置", "地铁"]
data.to_csv(".\Lianjia_II.csv", encoding='utf_8_sig', index=False, columns=columns)
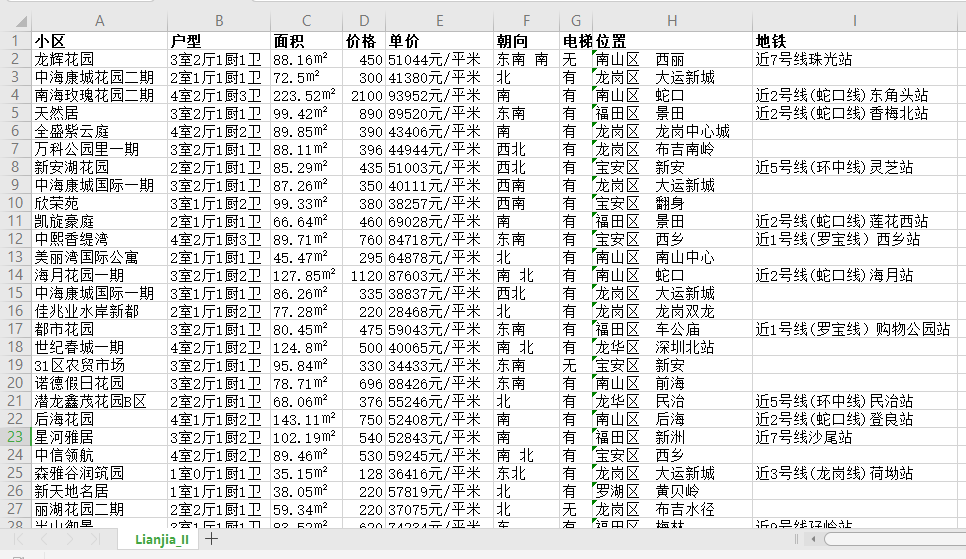
3、效果展示
4、完整代码:
# -* coding: utf-8 *-
#author: wangshx6
#data: 2018-11-07
#descriptinon: 爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文
import requests
from bs4 import BeautifulSoup
import pandas as pd
from fake_useragent import UserAgent
class LianjiaSpider(object):
def __init__(self):
self.headers = {"User-Agent": UserAgent().random}
self.datas = list()
def getMaxPage(self, url):
response = requests.get(url, headers = self.headers)
if response.status_code == 200:
source = response.text
soup = BeautifulSoup(source, "html.parser")
pageData = soup.find("div", class_ = "page-box house-lst-page-box")["page-data"]
# pageData = '{"totalPage":100,"curPage":1}',通过eval()函数把字符串转换为字典
maxPage = eval(pageData)["totalPage"]
return maxPage
else:
print("Fail status: {}".format(response.status_code))
return None
def parsePage(self, url):
maxPage = self.getMaxPage(url)
# 解析每个page,获取每个二手房的链接
for pageNum in range(1, maxPage+1 ):
url = "https://sz.lianjia.com/ershoufang/pg{}/".format(pageNum)
print("当前正在爬取: {}".format(url))
response = requests.get(url, headers = self.headers)
soup = BeautifulSoup(response.text, "html.parser")
links = soup.find_all("div", class_ = "info clear")
for i in links:
link = i.find("a")["href"] #每个<info clear>标签有很多<a>,而我们只需要第一个,所以用find
detail = self.parseDetail(link)
self.datas.append(detail)
# 将所有爬取的二手房数据存储到csv文件中
data = pd.DataFrame(self.datas)
# columns字段:自定义列的顺序(DataFrame默认按列名的字典序排序)
columns = ["小区", "户型", "面积", "价格", "单价", "朝向", "电梯", "位置", "地铁"]
data.to_csv(".\Lianjia_II.csv", encoding='utf_8_sig', index=False, columns=columns)
def parseDetail(self, url):
response = requests.get(url, headers = self.headers)
detail = {}
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
detail["价格"] = soup.find("span", class_ = "total").text
detail["单价"] = soup.find("span", class_ = "unitPriceValue").text
detail["小区"] = soup.find("div", class_ = "communityName").find("a", class_ = "info").text
detail["位置"] = soup.find("div", class_="areaName").find("span", class_="info").text
detail["地铁"] = soup.find("div", class_="areaName").find("a", class_="supplement").text
base = soup.find("div", class_ = "base").find_all("li") # 基本信息
detail["户型"] = base[0].text[4:]
detail["面积"] = base[2].text[4:]
detail["朝向"] = base[6].text[4:]
detail["电梯"] = base[10].text[4:]
return detail
else:
return None
if __name__ == "__main__":
Lianjia = LianjiaSpider()
Lianjia.parsePage("https://sz.lianjia.com/ershoufang/")
python爬虫:爬取链家深圳全部二手房的详细信息的更多相关文章
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
- Python爬虫项目--爬取链家热门城市新房
本次实战是利用爬虫爬取链家的新房(声明: 内容仅用于学习交流, 请勿用作商业用途) 环境 win8, python 3.7, pycharm 正文 1. 目标网站分析 通过分析, 找出相关url, 确 ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- 【nodejs 爬虫】使用 puppeteer 爬取链家房价信息
使用 puppeteer 爬取链家房价信息 目录 使用 puppeteer 爬取链家房价信息 页面结构 爬虫库 pupeteer 库 实现 打开待爬页面 遍历区级页面 方法一 方法二 遍历街道页面 遍 ...
- Python爬取链家二手房源信息
爬取链家网站二手房房源信息,第一次做,仅供参考,要用scrapy. import scrapy,pypinyin,requests import bs4 from ..items import L ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
随机推荐
- broadcastemit
http://code.angularjs.org/1.0.2/docs/api/ng.$rootScope.Scope#$broadcast scope可以以类似于DOM事件的方式进行事件传播.事件 ...
- MySQL命令行导入导出sql文件
linux下 一.导出数据库用mysqldump命令(注意mysql的安装路径,即此命令的路径):1.导出数据和表结构(常用):mysqldump -u用户名 -p密码 数据库名 > 数据库名. ...
- (二)svn服务端安装配置
两种服务端安装包 官方安装包 官方网站:http://subversion.apache.org/ 下载:http://subversion.apache.org/download.cgi 官方提供的 ...
- 安装OUD报错,unsupported classversion 51.0
查找,错误代码,在一篇博客中看到:补充:后经实例证明,在eclipse中进行开发的时候,build path 中JDK进行类库的编译(就是你使用类在不在这个JDK中),java compiler co ...
- June 08th 2017 Week 23rd Thursday
Life is like a beautiful melody, only the lyrics are messed up. 生命是首美丽的曲子,虽然歌词有些纠结. Now that we get ...
- May 12th 2017 Week 19th Friday
Love asks faith, and faith asks firmness. 爱情要求忠诚,而忠诚要求坚贞. Love, as well as many other relations amon ...
- js原型链继承及调用父类方法
方法1: var Parent= function () { }; Parent.prototype.process = function(){ alert('parent method'); }; ...
- CSP
CSP(Content-Security-Policy): 内容安全策略 作用: .限制资源获取 .报告资源获取越权 限制方式: .default-src限制全局 跟链接请求有关的东西,限制他 ...
- GetClassLoader和GetCallerClass的使用
GetClassLoader是JAVA中用来得到ClassLoader的 JAVA中有以下几种ClassLoader. 1. Bootstrap ClassLoader - GetClassLoad ...
- eclipse集成tomcat 部署项目设置
============================================================= 1. 下载安装tomcat插件 ====================== ...