移动端数据爬取(fidlde)
一.什么是Fiddler?
1 什么是Fiddler?
Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 HTTP请求,
可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是web调试的利器。 既然是代理,也就是说:客户端的所有请求都要先经过Fiddler,然后转发到相应的服务器,反之,服务器端的所有响应,也都会先经过Fiddler
然后发送到客户端,基于这个原因,Fiddler支持所有可以设置http代理为127.0.0.1:8888的浏览器和应用程序。
二.手机APP抓包设置
1. Fiddler设置
打开Fiddler软件,打开工具的设置。(Fiddler软件菜单栏:Tools->Options)
在HTTPS中设置如下:
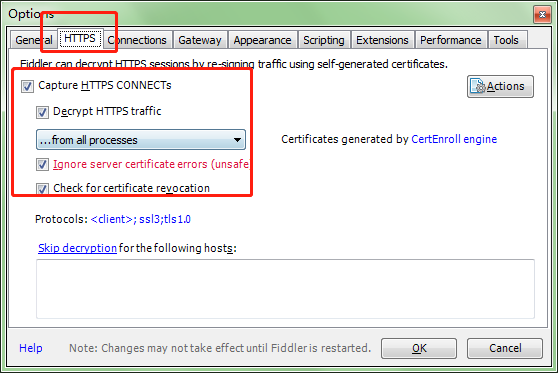
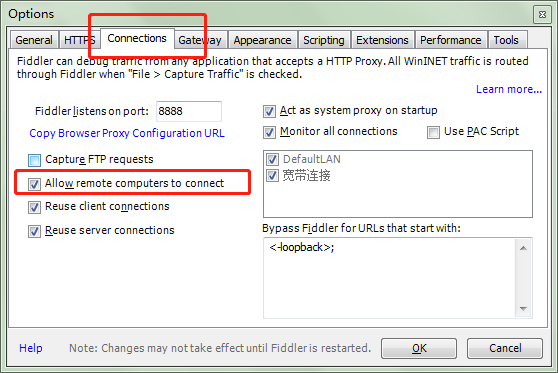
2.在Connections中设置如下,这里使用默认8888端口,当然也可以自己更改,但是注意不要与已经使用的端口冲突:
Allow remote computers to connect:允许别的机器把请求发送到fiddler上来
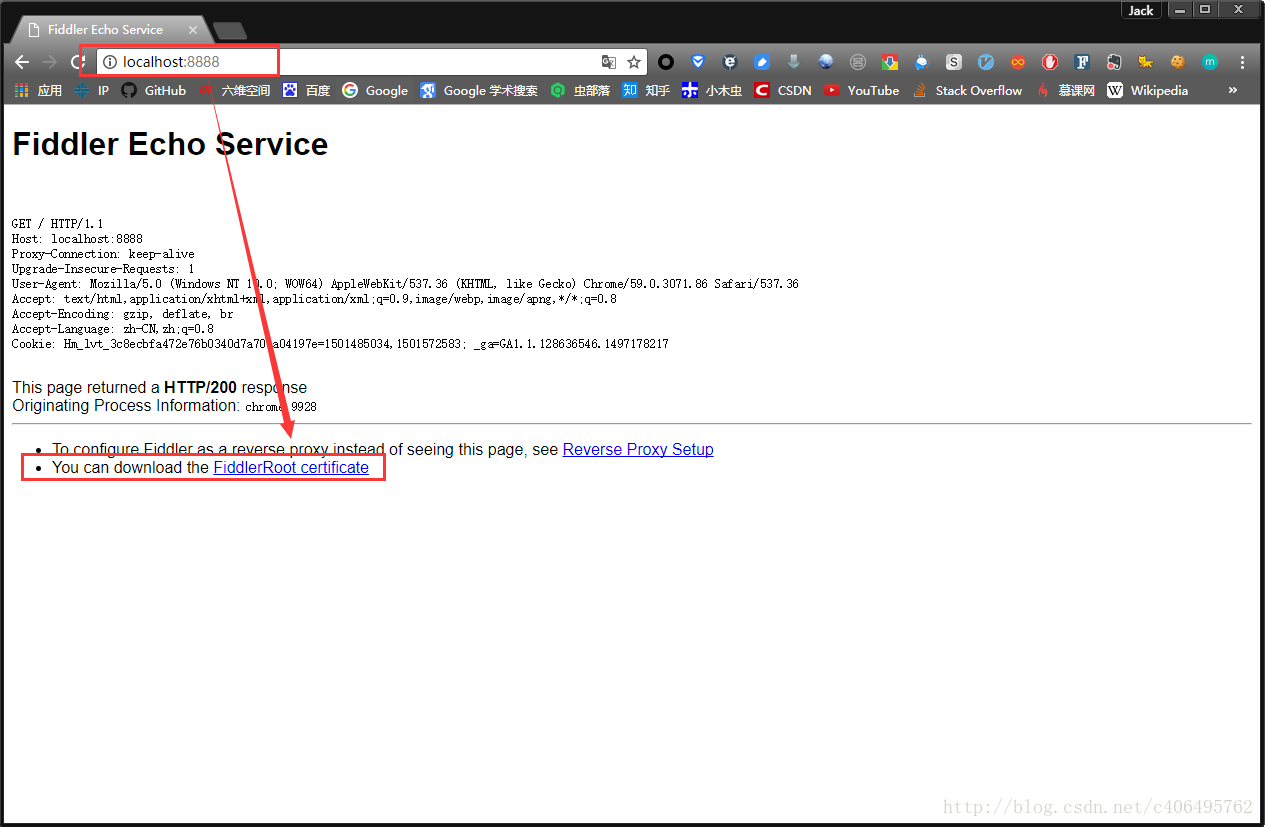
3. 安全证书下载
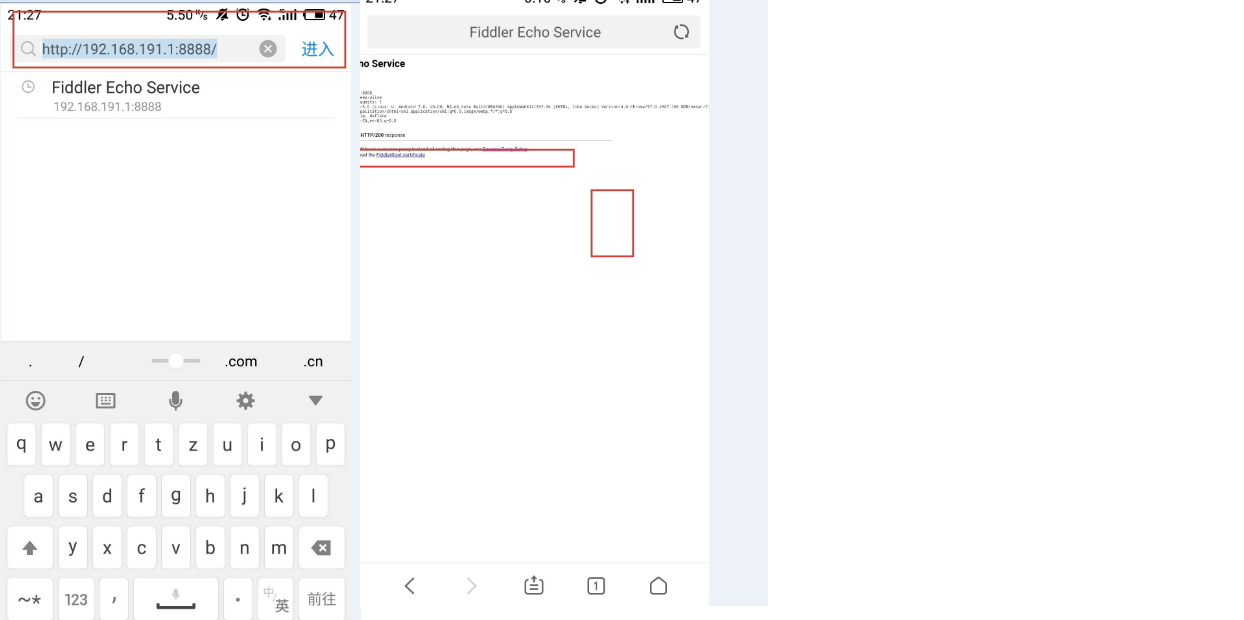
在电脑浏览器中输入地址:http://localhost:8888/,点击FiddlerRoot certificate,下载安全证书:
或者这样:查看本机ip
ipconfig
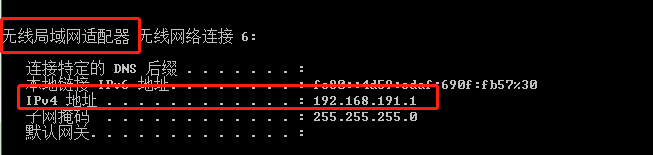
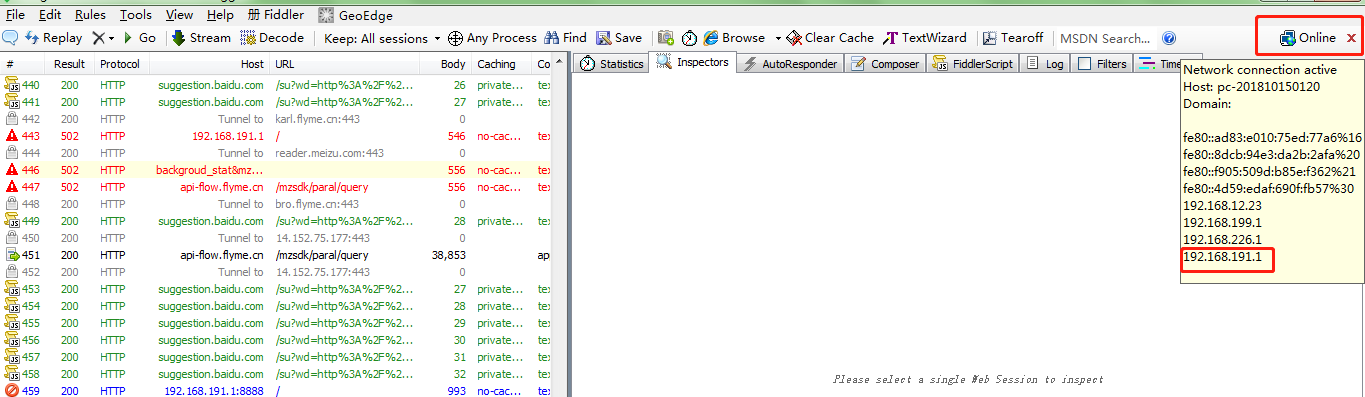
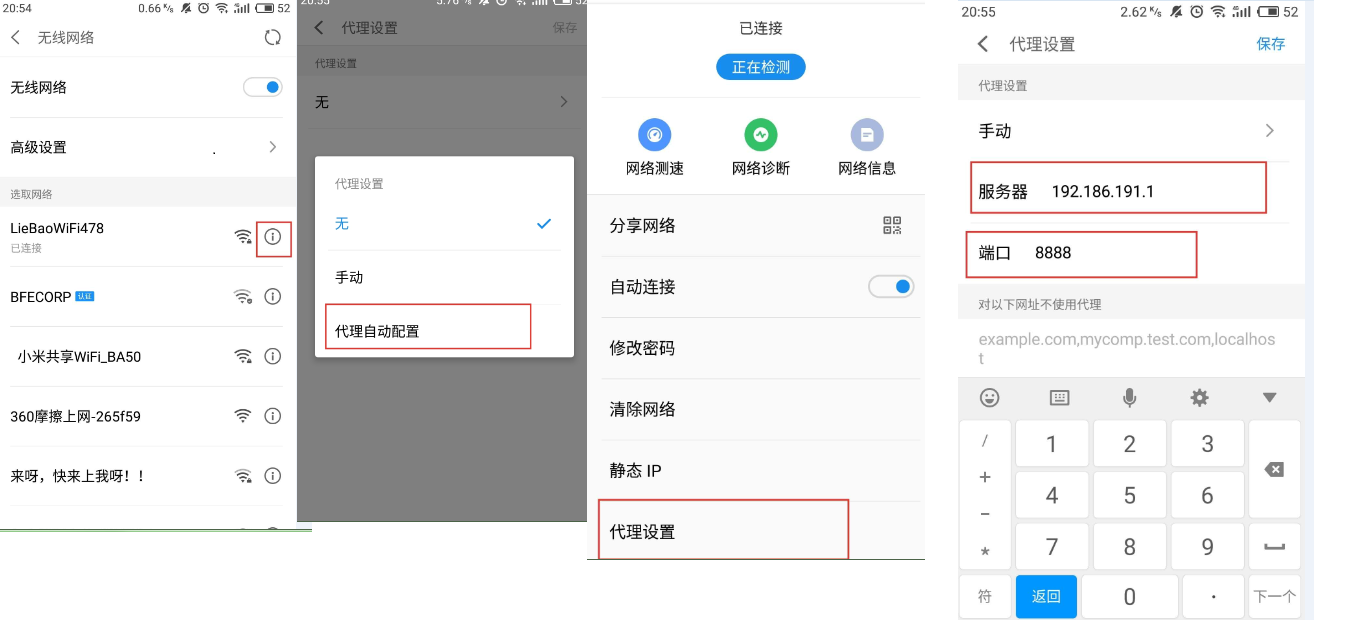
然后在手机上的无线局域网中设置代理ip
4. 安全证书安装
证书是需要在手机上进行安装的,这样在电脑Fiddler软件抓包的时候,手机使用电脑的网卡上网才不会报错。
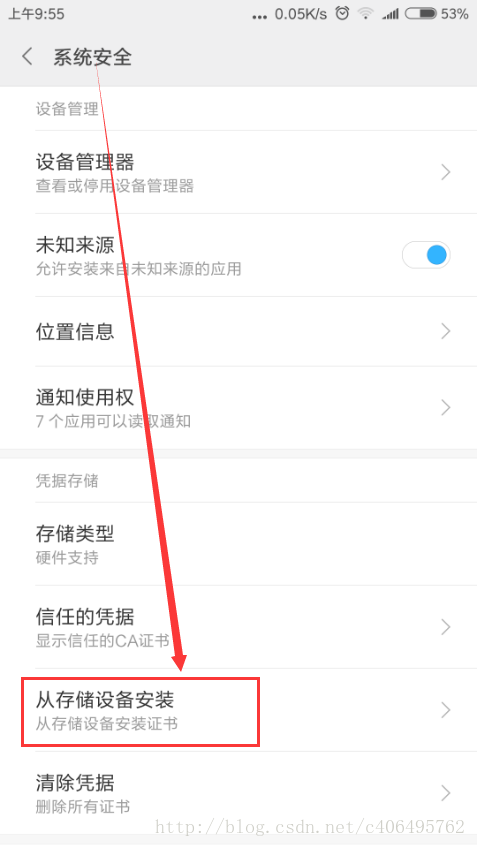
Android手机安装:把证书放入手机的内置或外置存储卡上,然后通过手机的"系统安全-》从存储设备安装"菜单安装证书。
然后找到拷贝的FiddlerRoot.cer进行安装即可。安装好之后,可以在信任的凭证中找到我们已经安装好的安全证
苹果手机安装:
- 保证手机网络和fiddler所在机器网络是同一个网段下的
- 在safari中访问http://fiddle机器ip:fiddler端口,进行证书下载。然后进行安装证书操作。
- 在手机中的设置-》通用-》关于本机-》证书信任设置-》开启fiddler证书信任
5.局域网设置
想要使用Fiddler进行手机抓包,首先要确保手机和电脑的网络在一个内网中,可以使用让电脑和手机都连接同一个路由器。
当然,也可以让电脑开放WIFI热点,手机连入。这里,我使用的方法是,让手机和电脑同时连入一个路由器中。最后,让手机使用电脑的代理IP进行上网。
在手机上,点击连接的WIFI进行网络修改,添加代理。进行手动设置,ip和端口号都是fiddler机器的ip和fiddler上设置的端口号。
6.Fiddler手机抓包测试
使用网页测试抓包
移动端数据爬取(fidlde)的更多相关文章
- 移动端数据爬取和Scrapy框架
移动端数据爬取 注:抓包工具:青花瓷 1.配置fiddler 2.移动端安装fiddler证书 3.配置手机的网络 - 给手机设置一个代理IP:port a. Fiddler设置 打开Fiddler软 ...
- 小爬爬5:重点回顾&&移动端数据爬取1
1. ()什么是selenium - 基于浏览器自动化的一个模块 ()在爬虫中为什么使用selenium及其和爬虫之间的关联 - 可以便捷的获取动态加载的数据 - 实现模拟登陆 ()列举常见的sele ...
- 爬虫05 /js加密/js逆向、常用抓包工具、移动端数据爬取
爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 目录 爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 1. js加密.js逆向:案例1 2. js加密.js逆向:案例2 3 ...
- requests模块session处理cookie 与基于线程池的数据爬取
引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如: #!/usr/bin/ ...
- Python3,x:如何进行手机APP的数据爬取
Python3,x:如何进行手机APP的数据爬取 一.简介 平时我们的爬虫多是针对网页的,但是随着手机端APP应用数量的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来 ...
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- 芝麻HTTP:JavaScript加密逻辑分析与Python模拟执行实现数据爬取
本节来说明一下 JavaScript 加密逻辑分析并利用 Python 模拟执行 JavaScript 实现数据爬取的过程.在这里以中国空气质量在线监测分析平台为例来进行分析,主要分析其加密逻辑及破解 ...
- Python爬虫 股票数据爬取
前一篇提到了与股票数据相关的可能几种数据情况,本篇接着上篇,介绍一下多个网页的数据爬取.目标抓取平安银行(000001)从1989年~2017年的全部财务数据. 数据源分析 地址分析 http://m ...
- quotes 整站数据爬取存mongo
安装完成scrapy后爬取部分信息已经不能满足躁动的心了,那么试试http://quotes.toscrape.com/整站数据爬取 第一部分 项目创建 1.进入到存储项目的文件夹,执行指令 scra ...
随机推荐
- oracle数据库列的操作
本章和大家分享一下如何在数据库中进行列的一些相关操作. 1.增加列名 (我们先来看一个原始版本) 下面我们增加一个列名tel 记住,增加列时需要把列对应的数据类型要说明,不然会报错. alter t ...
- wpf控件开发基础
wpf控件开发基础(3) -属性系统(2) http://www.cnblogs.com/Clingingboy/archive/2010/02/01/1661370.html 这个有必要看看 wpf ...
- C#英文面试常见问题[转]
I was reading a post about some common C# interview questions, and thought I'd share some of mine. T ...
- [转]Marshaling a SAFEARRAY of Managed Structures by P/Invoke Part 5.
1. Introduction. 1.1 In part 4, I have started to discuss how to interop marshal a managed array tha ...
- JVM锁实现探究2:synchronized深探
本文来自网易云社区 作者:马进 这里我们来聊聊synchronized,以及wait(),notify()的实现原理. 在深入介绍synchronized原理之前,先介绍两种不同的锁实现. 一.阻塞锁 ...
- (原创)数据结构之利用KMP算法解决串的模式匹配问题
给定一个主串S(长度<=10^6)和一个模式T(长度<=10^5),要求在主串S中找出与模式T相匹配的子串,返回相匹配的子串中的第一个字符在主串S中出现的位置. 输入格式: 输入有两行 ...
- 简单使用postman
一.get请求 获取学生信息接口文档内容: 简要描述: 获取学生信息接口 请求URL: http://ip/api/user/stu_info 请求方式: get 参数: 参数名 必选 类型 说明 s ...
- 题解 UVA10212 【The Last Non-zero Digit.】
题目链接 这题在学长讲完之后和看完题解之后才明白函数怎么构造. 这题构造一个$f(n)$ $f(n)$ $=$ $n$除以 $2^{a}$ $*$ $5^{b}$ ,$a$ , $b$ 分别是 $n$ ...
- 基于python-opencv3的图像显示和保存操作
import cv2 as cv import numpy as np #导入库 print("------------------------ ...
- iOS APP日志写入文件(日志收集)
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launc ...