大数据【六】ZooKeeper部署
这是一个分布式服务框架,阿帕奇的一个子项目。关于ZooKeeper我只简单的部署一下,以便后面的HBase。
一 概述
ZooKeeper 分布式服务框架是 Apache Hadoop 的一个子项目,主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
ZooKeeper是以Fast Paxos算法为基础的。
ZooKeeper集群的初始化过程:集群中所有机器以投票的方式(少数服从多数)选取某一台机器作为leader(领导者),其余机器作为follower(追随者)。如果集群中只有一台机器,那么就这台机器就是leader,没有follower。
ZooKeeper集群与客户端的交互:客户端可以在任意情况下ZooKeeper集群中任意一台机器上进行读操作;但是写操作必须得到leader的同意后才能执行。
ZooKeeper选取leader的核心算法思想:如果某服务器获得N/2 + 1票,则该服务器成为leader。N为集群中机器数量。为了避免出现两台服务器获得相同票数(N/2),应该确保N为奇数。因此构建ZooKeeper集群最少需要3台机器。
二 ZooKeeper部署
1’ 安装JDK(最先的博客早就说明配置了)
因为 ZooKeeper 服务器在 JVM 上运行。
2‘ 修改ZooKeeper配置文件
>首先配置slave1,slave2,slave3之间的免密和各个机器的/etc/hosts文件
修改ZooKeeper的配置文件,步骤如下:
进入解压目录下,把conf目录下的zoo_sample.cfg 复制成zoo.cfg文件。

3’ 打开zoo.cfg并修改和添加配置项目,如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the port at which the clients will connect
clientPort=2181
# the directory where the snapshot is stored.
dataDir=/usr/cstor/zookeeper/data
dataLogDir=/usr/cstor/zookeeper/log
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888
4‘ 新建两个目录。
mkdir /usr/cstor/zookeeper/data
mkdir /usr/cstor/zookeeper/log

将/usr/cstor/zookeeper目录传到另外两台机器上。
scp -r /usr/cstor/zookeeper root@slave2:/usr/cstor
scp -r /usr/cstor/zookeeper root@slave3:/usr/cstor
分别在三个节点上的/usr/local/zookeeper/data目录下创建一个文件:myid。
vi /usr/cstor/zookeeper/data/myid
分别在myid上按照配置文件的server.<id>中id的数值,在不同机器上的该文 件中填写相应过的值,如下:
slave1 的myid内容为1
slave2 的myid内容为2
slave3 的myid内容为3
5’ 启动ZooKeeper集群
然后,启动ZooKeeper集群,进入客户端验证部署完成。
分别在三个节点进入bin目录,启动ZooKeeper服务进程:
cd /usr/cstor/zookeeper/bin
./zkServer.sh start

在各机器上依次执行脚本,查看ZooKeeper状态信息,两个节点是follower状态,一个节点是leader状态:
./zkServer.sh status
在其中一台机器上执行客户端脚本:
./zkCli.sh -server slave1:2181,slave2:2181,slave3:2181
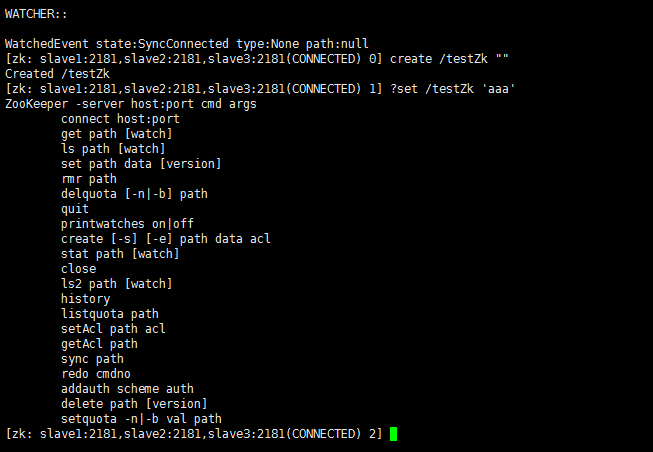
在客户端shell下执行创建目录命令:
create /testZk ""
向/testZk目录写数据:
set /testZk 'aaa'
读取/testZk目录数据:
get /testZk
删除/testZk目录:
rmr /testZk
在客户端shell下用quit命令退出客户端:
quit

大数据【六】ZooKeeper部署的更多相关文章
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 大数据之 ZooKeeper原理及其在Hadoop和HBase中的应用
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现.分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知. ...
- 大数据~说说ZooKeeper
一些概念 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase和Kafka重要组件.它是一个为分布式应用提供一致性 ...
- 大数据(7) - zookeeper的安装与使用
简介 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提 ...
- Redis安装,mongodb安装,hbase安装,cassandra安装,mysql安装,zookeeper安装,kafka安装,storm安装大数据软件安装部署百科全书
伟大的程序员版权所有,转载请注明:http://www.lenggirl.com/bigdata/server-sofeware-install.html 一.安装mongodb 官网下载包mongo ...
- 【大数据】Zookeeper学习笔记
第1章 Zookeeper入门 1.1 概述 Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目. 1.2 特点 1.3 数据结构 1.4 应用场景 提供的服务包括:统 ...
- 最新版大数据平台安装部署指南,HDP-2.6.5.0,ambari-2.6.2.0
一.服务器环境配置 1 系统要求 名称 地址 操作系统 root密码 Master1 10.1.0.30 Centos 7.7 Root@bidsum1 Master2 10.1.0.105 Cent ...
- 大数据之Zookeeper概述
Zookeeper概述 Zookeeper是一个开放源码的分布式应用程序协调服务,是 Google的Chubby一个开源的实现,是 Hadoop和 HBASE的重要组件.主要解决分布式应用一致性问题. ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
随机推荐
- Centos 7 快速搭建IOS可用IPsec
安装 strongswan yum install -y http://ftp.nluug.nl/pub/os/Linux/distr/fedora-epel/7/x86_64/Packages/e/ ...
- Java动态代理总结
在之前的代码调用阶段,我们用action调用service的方法实现业务即可. 由于之前在service中实现的业务可能不能够满足当先客户的要求,需要我们重新修改service中的方法,但是servi ...
- Storm的acker确认机制
Storm的acker消息确认机制... ack/fail消息确认机制(确保一个tuple被完全处理) 在spout中发射tuple的时候需要同时发送messageid,这样才相当于开启了消息确认机制 ...
- gvim配置相关
用 vundle 来管理 vim 插件(包含配置文件vimrc和gvimrc) gvim插件管理神器:vundle的安装与使用 Vim插件管理Vundle Linux 下VIM的配置 Vim配置系列( ...
- Error:Could not determine the class-path for interface com.android.builder.model.AndroidProject.
Android Studio导入Eclipse项目报错Error:Could not determine the class-path for interface com.android.builde ...
- Vue中使用watch来监听数据变化
写法一: methods:{ //监听isMD upProp(){ if(this.isMD){//如果isMD等于true 就把storeManagerName赋值给isStoreManagerNa ...
- 轻量级web富文本框——wangEditor使用手册(4)——配置下拉菜单 demo
最新版wangEditor: 配置说明:http://www.wangeditor.com/doc.html demo演示:http://www.wangeditor.com/wangEditor/d ...
- Leetcode 746. Min Cost Climbing Stairs
思路:动态规划. class Solution { //不能对cost数组进行写操作,因为JAVA中参数是引用 public int minCostClimbingStairs(int[] cost) ...
- CentOS6.5 QT5.3 找不到GLIBCXX3.4.15解决方法
下载安装后 启动的时候提示 GLIBCXX_3.4.15,发现libstdc++.so.6的版本过, 在安装qt-creator的时候运行这个IDE就出现了这个问题,是由于libstdc++.so.6 ...
- 3D转弯保护区长啥样?
3D转弯保护区长啥样? 2015-12-06 刘崇军 风螺旋线 在课本中.规范中看到的转弯保护区一直是平面化的样子.我们知道副区是由主区外扩而成,但具体怎样精确外扩无从知晓:我们知道主区边界至副区边界 ...