入门大数据---基于Zookeeper搭建Kafka高可用集群
一、Zookeeper集群搭建
为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群。
1.1 下载 & 解压
下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/
# 下载
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
# 解压
tar -zxvf zookeeper-3.4.14.tar.gz
1.2 修改配置
拷贝三份 zookeeper 安装包。分别进入安装目录的 conf 目录,拷贝配置样本 zoo_sample.cfg 为 zoo.cfg 并进行修改,修改后三份配置文件内容分别如下:
zookeeper01 配置:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/01
dataLogDir=/usr/local/zookeeper-cluster/log/01
clientPort=2181
# server.1 这个1是服务器的标识,可以是任意有效数字,标识这是第几个服务器节点,这个标识要写到dataDir目录下面myid文件里
# 指名集群间通讯端口和选举端口
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
如果是多台服务器,则集群中每个节点通讯端口和选举端口可相同,IP 地址修改为每个节点所在主机 IP 即可。
zookeeper02 配置,与 zookeeper01 相比,只有 dataLogDir、dataLogDir 和 clientPort 不同:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/02
dataLogDir=/usr/local/zookeeper-cluster/log/02
clientPort=2182
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
zookeeper03 配置,与 zookeeper01,02 相比,也只有 dataLogDir、dataLogDir 和 clientPort 不同:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper-cluster/data/03
dataLogDir=/usr/local/zookeeper-cluster/log/03
clientPort=2183
server.1=127.0.0.1:2287:3387
server.2=127.0.0.1:2288:3388
server.3=127.0.0.1:2289:3389
配置参数说明:
- tickTime:用于计算的基础时间单元。比如 session 超时:N*tickTime;
- initLimit:用于集群,允许从节点连接并同步到 master 节点的初始化连接时间,以 tickTime 的倍数来表示;
- syncLimit:用于集群, master 主节点与从节点之间发送消息,请求和应答时间长度(心跳机制);
- dataDir:数据存储位置;
- dataLogDir:日志目录;
- clientPort:用于客户端连接的端口,默认 2181
1.3 标识节点
分别在三个节点的数据存储目录下新建 myid 文件,并写入对应的节点标识。Zookeeper 集群通过 myid 文件识别集群节点,并通过上文配置的节点通信端口和选举端口来进行节点通信,选举出 leader 节点。
创建存储目录:
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/01
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/02
# dataDir
mkdir -vp /usr/local/zookeeper-cluster/data/03
创建并写入节点标识到 myid 文件:
#server1
echo "1" > /usr/local/zookeeper-cluster/data/01/myid
#server2
echo "2" > /usr/local/zookeeper-cluster/data/02/myid
#server3
echo "3" > /usr/local/zookeeper-cluster/data/03/myid
1.4 启动集群
分别启动三个节点:
# 启动节点1
/usr/app/zookeeper-cluster/zookeeper01/bin/zkServer.sh start
# 启动节点2
/usr/app/zookeeper-cluster/zookeeper02/bin/zkServer.sh start
# 启动节点3
/usr/app/zookeeper-cluster/zookeeper03/bin/zkServer.sh start
1.5 集群验证
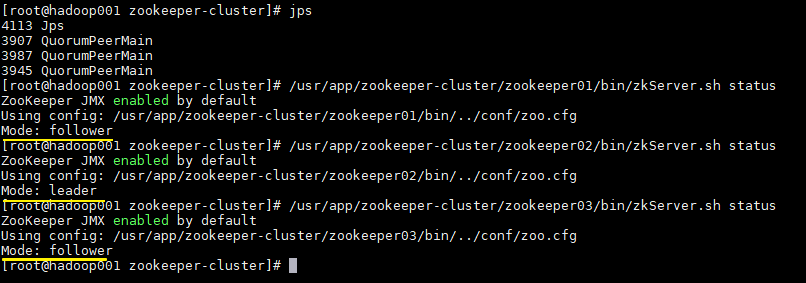
使用 jps 查看进程,并且使用 zkServer.sh status 查看集群各个节点状态。如图三个节点进程均启动成功,并且两个节点为 follower 节点,一个节点为 leader 节点。
二、Kafka集群搭建
2.1 下载解压
Kafka 安装包官方下载地址:http://kafka.apache.org/downloads ,本用例下载的版本为 2.2.0,下载命令:
# 下载
wget https://www-eu.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
# 解压
tar -xzf kafka_2.12-2.2.0.tgz
这里 j 解释一下 kafka 安装包的命名规则:以
kafka_2.12-2.2.0.tgz为例,前面的 2.12 代表 Scala 的版本号(Kafka 采用 Scala 语言进行开发),后面的 2.2.0 则代表 Kafka 的版本号。
2.2 拷贝配置文件
进入解压目录的 config 目录下 ,拷贝三份配置文件:
# cp server.properties server-1.properties
# cp server.properties server-2.properties
# cp server.properties server-3.properties
2.3 修改配置
分别修改三份配置文件中的部分配置,如下:
server-1.properties:
# The id of the broker. 集群中每个节点的唯一标识
broker.id=0
# 监听地址
listeners=PLAINTEXT://hadoop001:9092
# 数据的存储位置
log.dirs=/usr/local/kafka-logs/00
# Zookeeper连接地址
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183
server-2.properties:
broker.id=1
listeners=PLAINTEXT://hadoop001:9093
log.dirs=/usr/local/kafka-logs/01
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183
server-3.properties:
broker.id=2
listeners=PLAINTEXT://hadoop001:9094
log.dirs=/usr/local/kafka-logs/02
zookeeper.connect=hadoop001:2181,hadoop001:2182,hadoop001:2183
这里需要说明的是 log.dirs 指的是数据日志的存储位置,确切的说,就是分区数据的存储位置,而不是程序运行日志的位置。程序运行日志的位置是通过同一目录下的 log4j.properties 进行配置的。
2.4 启动集群
分别指定不同配置文件,启动三个 Kafka 节点。启动后可以使用 jps 查看进程,此时应该有三个 zookeeper 进程和三个 kafka 进程。
bin/kafka-server-start.sh config/server-1.properties
bin/kafka-server-start.sh config/server-2.properties
bin/kafka-server-start.sh config/server-3.properties
2.5 创建测试主题
创建测试主题:
bin/kafka-topics.sh --create --bootstrap-server hadoop001:9092 \
--replication-factor 3 \
--partitions 1 --topic my-replicated-topic
创建后可以使用以下命令查看创建的主题信息:
bin/kafka-topics.sh --describe --bootstrap-server hadoop001:9092 --topic my-replicated-topic
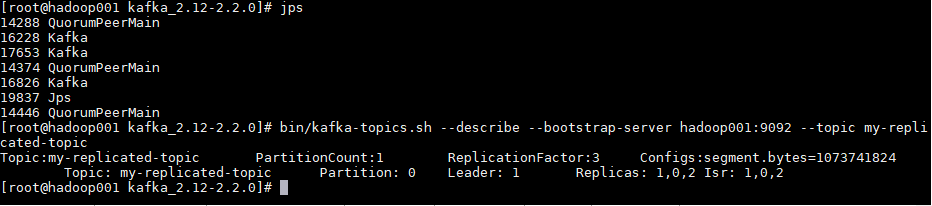
可以看到分区 0 的有 0,1,2 三个副本,且三个副本都是可用副本,都在 ISR(in-sync Replica 同步副本) 列表中,其中 1 为首领副本,此时代表集群已经搭建成功。
入门大数据---基于Zookeeper搭建Kafka高可用集群的更多相关文章
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- Kafka —— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 学习之路(二)—— 基于ZooKeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本Zookeep ...
- Kafka 系列(二)—— 基于 ZooKeeper 搭建 Kafka 高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 二.前置条件 三.Spark集群搭建 3.1 下载解压 3.2 配置环境变量 3.3 集群配置 3.4 安装包分发 四.启 ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Spark 系列(七)—— 基于 ZooKeeper 搭建 Spark 高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
随机推荐
- Javascript中target事件属性,事件的目标节点的获取。
window.event.srcElement与window.event.target 都是指向触发事件的元素,它是什么就有什么样的属性 srcElement是事件初始化目标html元素对象引用,因为 ...
- 数据库之 MySQL --- 下载、安装 及 概述(一)
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一 . MySql数据库的安装 1.图解MySQL程序结构 2.双击运行安装程序:以Win32位为例 ...
- EntityFramework数据持久化 Linq介绍
一.LINQ概述与查询语法 二.LINQ方法语法基础(重点) 三.LINQ聚合操作与元素操作(重点) 四.数据类型转换(重点) 一.LINQ概述与查询语法 1.LINQ(Language Integr ...
- Java实现 蓝桥杯 基础练习 查找整数
基础练习 查找整数 时间限制:1.0s 内存限制:256.0MB 提交此题 锦囊1 锦囊2 问题描述 给出一个包含n个整数的数列,问整数a在数列中的第一次出现是第几个. 输入格式 第一行包含一个整数n ...
- Java实现蓝桥杯VIP算法训练 自行车停放
试题 算法训练 自行车停放 资源限制 时间限制:1.0s 内存限制:256.0MB 问题描述 有n辆自行车依次来到停车棚,除了第一辆自行车外,每辆自行车都会恰好停放在已经在停车棚里的某辆自行车的左边或 ...
- Java中Iterator类的详细介绍
迭代器模式:就是提供一种方法对一个容器对象中的各个元素进行访问,而又不暴露该对象容器的内部细节. 概述 Java集合框架的集合类,我们有时候称之为容器.容器的种类有很多种,比如ArrayList.Li ...
- Java实现 蓝桥杯 基因牛的繁殖
基因牛的繁殖 张教授采用基因干预技术成功培养出一头母牛,三年后,这头母牛每年会生出1头母牛, 生出来的母牛三年后,又可以每年生出一头母牛.如此循环下去,请问张教授n年后有多少头母牛? 以下程序模拟了这 ...
- Linux网络命令详解
命令write,功能是给指定用户发信息(接收信息的用户要处于登录状态,相当于QQ的私聊),例如:用户xbb给用户liuyifei发消息:I want to eat together!(发送消息以CRT ...
- Java多线程之深入解析ThreadLocal和ThreadLocalMap
ThreadLocal概述 ThreadLocal是线程变量,ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的.ThreadLocal为变量在每个线程中都创建了一个副本,那 ...
- 滴滴数据驱动利器:AB实验之分组提效
桔妹导读:在各大互联网公司都提倡数据驱动的今天,AB实验是我们进行决策分析的一个重要利器.一次实验过程会包含多个环节,今天主要给大家分享滴滴实验平台在分组环节推出的一种提升分组均匀性的新方法.本文首先 ...