python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
觉得有用的话,欢迎一起讨论相互学习~Follow Me
参考文献
python操作txt文件中数据教程[1]-使用python读写txt文件
python操作txt文件中数据教程[2]-python提取txt文件
- 原始txt文件

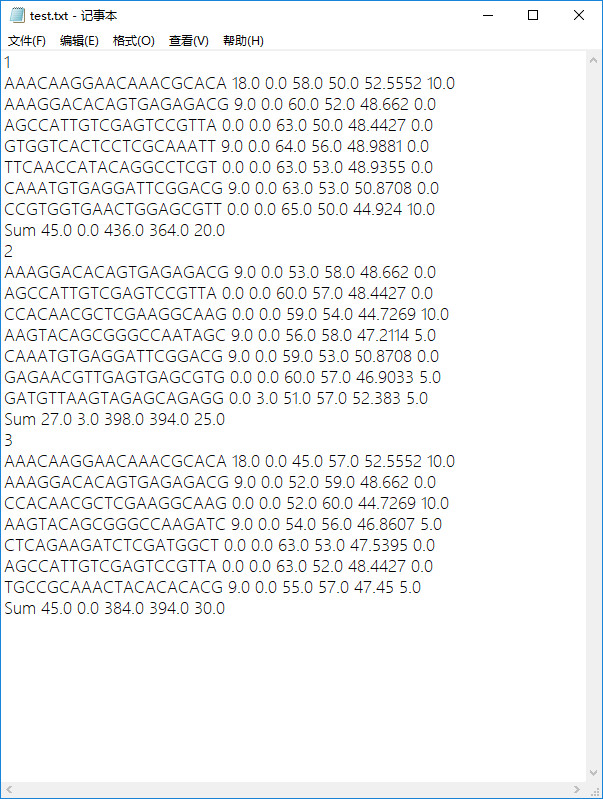
- 程序实现后结果

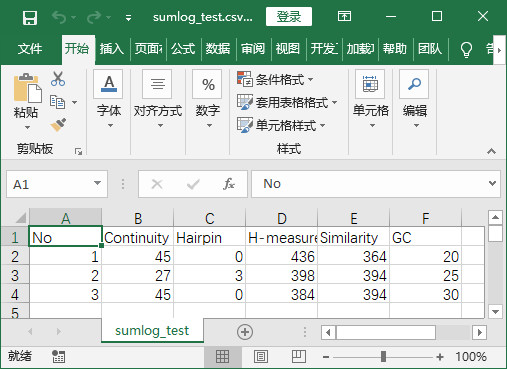
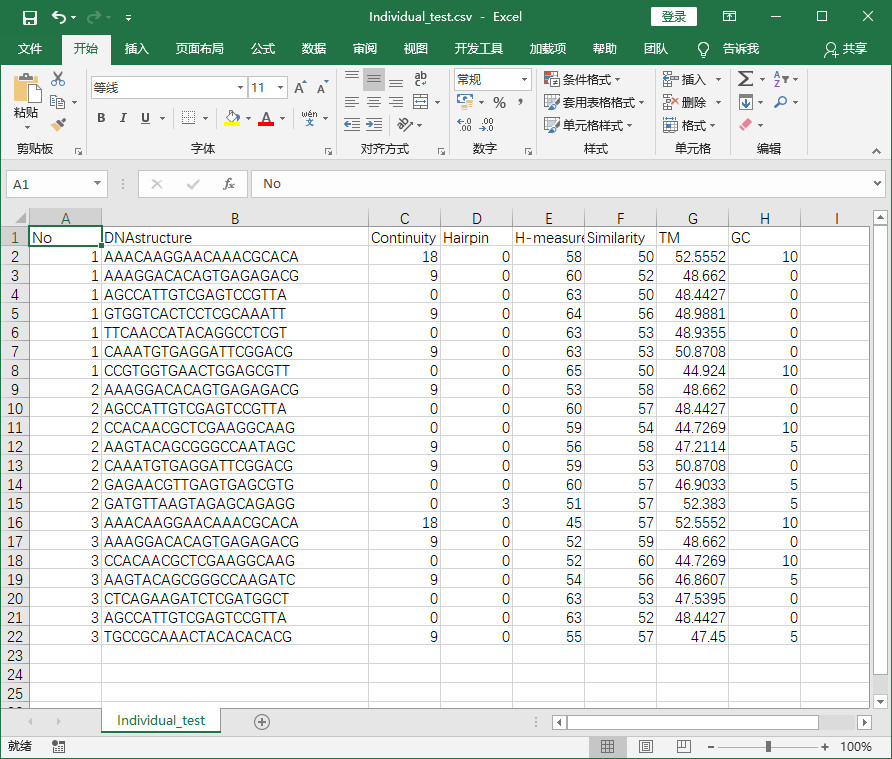
程序实现
import csv
import os
SUM_LOG_FILE = [] # sum_csv文件名
INDIVIDUAL_LOG_FILE = [] # individual_csv文件名
File_Name = [] # txt_文件名
DNA_Group = 7 # 表示每7条DNA组成一个组
Sum_log_file_header = ["No", "Continuity", "Hairpin", "H-measure", "Similarity", "GC"]
Individual_log_file_header = ["No", "DNAstructure", "Continuity", "Hairpin", "H-measure", "Similarity", "TM", "GC"]
def Read_Files(filename):
DNA_log = [] # 精英种群个体日志mod9=1-8
Sum_log = [] # 精英种群总体日志mod9=0
sum_evaindex = [[] for i in range(6)]
Individual_evaindex = [[] for i in range(8)]
with open(filename, 'r') as f:
i = 1
for line in f.readlines():
if i%9 == 0:
Sum_log.append(line)
else:
DNA_log.append(line)
i = i + 1
f.close()
Sum_no = 1
dna_log_no = 0
for Sum in Sum_log:
sum_eva_index = Sum.split("\n")[0].split(" ")[1:]
sum_evaindex[0].append(int(Sum_no))
sum_evaindex[1].append(float(sum_eva_index[0])) # Con
sum_evaindex[2].append(float(sum_eva_index[1])) # HP
sum_evaindex[3].append(float(sum_eva_index[2])) # Hm
sum_evaindex[4].append(float(sum_eva_index[3])) # Si
sum_evaindex[5].append(float(sum_eva_index[4])) # GC
Sum_no = Sum_no + 1
for dna_log in DNA_log:
# 获取序号值
if (dna_log_no + 1)%8 == 1:
for i in range(DNA_Group):
Individual_evaindex[0].append(int(dna_log.split("\n")[0]))
else:
# 获取各项指标
Individual_evaindex[1].append(dna_log.split("\n")[0].split(" ")[0]) # 所有DNA序列全部记载,使用原有的str字符串类型记载
Individual_evaindex[2].append(float(dna_log.split("\n")[0].split(" ")[1])) # DNA序列的连续值Con,注意要转换为浮点数类型
Individual_evaindex[3].append(float(dna_log.split("\n")[0].split(" ")[2])) # Hp茎区匹配
Individual_evaindex[4].append(float(dna_log.split("\n")[0].split(" ")[3])) # H-measure
Individual_evaindex[5].append(float(dna_log.split("\n")[0].split(" ")[4])) # Similarity
Individual_evaindex[6].append(float(dna_log.split("\n")[0].split(" ")[5])) # TM
Individual_evaindex[7].append(float(dna_log.split("\n")[0].split(" ")[6])) # GC
dna_log_no = dna_log_no + 1
return sum_evaindex, Individual_evaindex
# 将数据写入csv日志文件中
def Write_SumFiles(filename, sum_evaindex):
with open(filename, "w", newline='') as f:
writer = csv.writer(f)
writer.writerow(Sum_log_file_header) # 注意,此处使用writerow而不是使用writerows
for i in range(sum_evaindex[0][-1]):
writer.writerow(
[sum_evaindex[0][i], sum_evaindex[1][i], sum_evaindex[2][i], sum_evaindex[3][i], sum_evaindex[4][i],
sum_evaindex[5][i]])
f.close()
def Write_IndividualFiles(filename, sum_evaindex, Individual_evaindex):
with open(filename, "w", newline='') as f:
writer = csv.writer(f)
writer.writerow(Individual_log_file_header) # 注意,此处使用writerow而不是使用writerows
for i in range(sum_evaindex[0][-1]*DNA_Group):
writer.writerow(
[Individual_evaindex[0][i], Individual_evaindex[1][i], Individual_evaindex[2][i],
Individual_evaindex[3][i],
Individual_evaindex[4][i], Individual_evaindex[5][i], Individual_evaindex[6][i],
Individual_evaindex[7][i]])
f.close()
def file_name(file_dir):
for files in os.listdir(file_dir):
if os.path.splitext(files)[1] == '.txt':
File_Name.append(files)
SUM_LOG_FILE.append("./test/sumlog_" + os.path.splitext(files)[0] + ".csv")
INDIVIDUAL_LOG_FILE.append("./test/Individual_" + os.path.splitext(files)[0] + ".csv")
# 获取当前目录下所有txt文件名
file_name(".")
for i, j, k in zip(File_Name, SUM_LOG_FILE, INDIVIDUAL_LOG_FILE):
print(i)
print(j)
print(k)
Sum_Evaindex, Individual_Evaindex = Read_Files(i)
Write_SumFiles(filename=j, sum_evaindex=Sum_Evaindex)
Write_IndividualFiles(filename=k, sum_evaindex=Sum_Evaindex, Individual_evaindex=Individual_Evaindex)
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件的更多相关文章
- python操作txt文件中数据教程[4]-python去掉txt文件行尾换行
python操作txt文件中数据教程[4]-python去掉txt文件行尾换行 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文章 python操作txt文件中数据教程[1]-使用pyt ...
- python操作txt文件中数据教程[2]-python提取txt文件
python操作txt文件中数据教程[2]-python提取txt文件中的行列元素 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原始txt文件 程序实现后结果-将txt中元素提取并保存在c ...
- Jar中的Java程序如何读取Jar包中的资源文件
Jar中的Java程序如何读取Jar包中的资源文件 比如项目的组织结构如下(以idea中的项目为例): |-ProjectName |-.idea/ //这个目录是idea中项目的属性文件夹 |-s ...
- Python操作MySQL数据库(步骤教程)
我们经常需要将大量数据保存起来以备后续使用,数据库是一个很好的解决方案.在众多数据库中,MySQL数据库算是入门比较简单.语法比较简单,同时也比较实用的一个.在这篇博客中,将以MySQL数据库为例,介 ...
- 将Excel文件转为csv文件的python脚本
#!/usr/bin/env python __author__ = "lrtao2010" ''' Excel文件转csv文件脚本 需要将该脚本直接放到要转换的Excel文件同级 ...
- javaSE中的输入输出流---一个读取流,相应多个输出流。并且生成的碎片文件都有有序的编号
<span style="font-size:18px;">package com.io.other.split; import java.io.File; impor ...
- Java 在PPT中创建SmartArt图形、读取SmartArt图形中的文本
一.概述及环境准备 SmartArt 图形通过将文字.图形从多种不同布局.组合来表现内容和观点的逻辑关系,能够快速.有效地传达设计者的意图和信息.这种图文表达的视觉表示形式常用于PPT,Word,Ex ...
- [Asp.net]通过uploadify将文件上传到B服务器的共享文件夹中
写在前面 客户有这样的一个需求,针对项目中文档共享的模块,客户提出如果用户上传特别的大,或者时间久了硬盘空间就会吃满,能不能将这些文件上传到其他的服务器?然后就稍微研究了下这方面的东西,上传到网络中的 ...
- 安卓中級教程(9):pathbutton中的animation.java研究(2)
src/geniuz/myPathbutton/composerLayout.java package geniuz.myPathbutton; import com.nineoldandroids. ...
随机推荐
- python常用算法实现
排序是计算机语言需要实现的基本算法之一,有序的数据结构会带来效率上的极大提升. 1.插入排序 插入排序默认当前被插入的序列是有序的,新元素插入到应该插入的位置,使得新序列仍然有序. def inser ...
- SSIS 更新变量
在Package中声明一个variable,在package运行的过程中,SSIS如何update Variable? 第一种方法:使用 Script Task 来更新Variable的值 1,创建一 ...
- C#杂乱知识汇总
:first-child{margin-top:0!important}.markdown-body>:last-child{margin-bottom:0!important}.markdow ...
- Js_特效II
字号缩放 让文字大点,让更多的用户看的更清楚.(也可以把字体变为百分比来实现)<script type="text/javascript"> function doZ ...
- Ubuntu 开机自动启动
# 开机启动 2018-12-13在etc目录下建立loraserver.sh文件,[**注意**:设置脚本的运行属性]其内容为 #!/bin/bash cd /home/zqkj/loraserve ...
- 物理机通过http访问eNSP虚拟Server
由于测试需要,本文主要通过一个简单的例子介绍通过物理机的浏览器访问华为eNSP虚拟Server,访问网页. 1.首先配置虚拟网卡的地址 2.通过华为的eNSP模拟软件,做出如下拓扑结构图,配置地址如图 ...
- 给Android Studio 设置背景图片
初用Android Studio的我 看见这么帅的事情,肯定自己要设置试试(又可以边看女神边打代码了,想想都刺激)由于这不是AS的原始功能所以需要下载插件 先看看效果图吧: 1.下载插件 Sexy E ...
- [沈航软工教学] 学生项目Coding地址汇总
同学们把自己的coding主页链接贴在评论里,要求格式"班号+学号+coding主页链接",如: "1301+13061193 + https://coding.net/ ...
- Alpha阶段_团队分数分配
小组成员 分数分配 薄霖 74 徐越 65 赵庶宏 65 赵铭 41 武鑫 39 卞忠昊 36 叶能端 30
- wordpress学习四: 一个简单的自定义主题
在学习三里分析了自带的一个例子,本节我们就自己仿照他做个简单的吧,重点是调用wordpress封装好的函数和类,css和html可以稍好在调整. 将wp带的例子复制一份处理,重新名个名字. 清空ind ...