使用Kubeflow构建机器学习流水线
在此前的文章中,我已经向你介绍了Kubeflow,这是一个为团队设置的机器学习平台,需要构建机器学习流水线。
在本文中,我们将了解如何采用现有的机器学习详细并将其变成Kubeflow的机器学习流水线,进而可以部署在Kubernetes上。在进行本次练习的时候,请考虑你该如何将现有的机器学习项目转换到Kubeflow上。
我将使用Fashion MNIST作为例子,因为在本次练习中模型的复杂性并不是我们需要解决的主要目标。对于这一简单的例子,我将流水线分为3个阶段:
Git clone代码库
下载并重新处理训练和测试数据
训练评估
当然,你可以根据自己的用例将流水线以任意形式拆分,并且可以随意扩展流水线。
获取代码
你可以从Github上获取代码:
% git clone https://github.com/benjamintanweihao/kubeflow-mnist.git
以下是我们用来创建流水线的完整清单。实际上,你的代码很可能跨多个库和文件。在我们的例子中,我们将代码分为两个脚本,preprocessing.py和train.py。
from tensorflow import keras
import argparse
import os
import pickle
def preprocess(data_dir: str):
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
os.makedirs(data_dir, exist_ok=True)
with open(os.path.join(data_dir, 'train_images.pickle'), 'wb') as f:
pickle.dump(train_images, f)
with open(os.path.join(data_dir, 'train_labels.pickle'), 'wb') as f:
pickle.dump(train_labels, f)
with open(os.path.join(data_dir, 'test_images.pickle'), 'wb') as f:
pickle.dump(test_images, f)
with open(os.path.join(data_dir, 'test_labels.pickle'), 'wb') as f:
pickle.dump(test_labels, f)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Kubeflow MNIST training script')
parser.add_argument('--data_dir', help='path to images and labels.')
args = parser.parse_args()
preprocess(data_dir=args.data_dir)
处理脚本采用单个参数data_dir。它下载并预处理数据,并将pickled版本保存在data_dir中。在生产代码中,这可能是TFRecords的存储目录。
train.py
import calendar
import os
import time
import tensorflow as tf
import pickle
import argparse
from tensorflow import keras
from constants import PROJECT_ROOT
def train(data_dir: str):
# Training
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
with open(os.path.join(data_dir, 'train_images.pickle'), 'rb') as f:
train_images = pickle.load(f)
with open(os.path.join(data_dir, 'train_labels.pickle'), 'rb') as f:
train_labels = pickle.load(f)
model.fit(train_images, train_labels, epochs=10)
with open(os.path.join(data_dir, 'test_images.pickle'), 'rb') as f:
test_images = pickle.load(f)
with open(os.path.join(data_dir, 'test_labels.pickle'), 'rb') as f:
test_labels = pickle.load(f)
# Evaluation
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print(f'Test Loss: {test_loss}')
print(f'Test Acc: {test_acc}')
# Save model
ts = calendar.timegm(time.gmtime())
model_path = os.path.join(PROJECT_ROOT, f'mnist-{ts}.h5')
tf.saved_model.save(model, model_path)
with open(os.path.join(PROJECT_ROOT, 'output.txt'), 'w') as f:
f.write(model_path)
print(f'Model written to: {model_path}')
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Kubeflow FMNIST training script')
parser.add_argument('--data_dir', help='path to images and labels.')
args = parser.parse_args()
train(data_dir=args.data_dir)
在train.py中,将建立模型,并使用data_dir指定训练和测试数据的位置。模型训练完毕并且开始执行评估后,将模型写入带有时间戳的路径。请注意,该路径也已写入output.txt。稍后将对此进行引用。
开发Kubeflow流水线
为了开始创建Kubeflow流水线,我们需要拉取一些依赖项。我准备了一个environment.yml,其中包括了kfp 0.5.0、tensorflow以及其他所需的依赖项。
你需要安装Conda,然后执行以下步骤:
% conda env create -f environment.yml
% source activate kubeflow-mnist
% python preprocessing.py --data_dir=/path/to/data
% python train.py --data_dir=/path/to/data
现在我们来回顾一下我们流水线中的几个步骤:
Git clone代码库
下载并预处理训练和测试数据
训练并进行评估
在我们开始写代码之前,需要从宏观上了解Kubeflow流水线。
流水线由连接组件构成。一个组件的输出成为另一个组件的输入,每个组件实际上都在容器中执行(在本例中为Docker)。将发生的情况是,我们会执行一个我们稍后将要指定的Docker镜像,它包含了我们运行preprocessing.py和train.py所需的一切。当然,这两个阶段会有它们的组件。
我们还需要额外的一个镜像以git clone项目。我们需要将项目bake到Docker镜像,但在实际项目中,这可能会导致Docker镜像的大小膨胀。
说到Docker镜像,我们应该先创建一个。
Step0:创建一个Docker镜像
如果你只是想进行测试,那么这个步骤不是必须的,因为我已经在Docker Hub上准备了一个镜像。这是Dockerfile的全貌:
FROM tensorflow/tensorflow:1.14.0-gpu-py3
LABEL MAINTAINER "Benjamin Tan <benjamintanweihao@gmail.com>"
SHELL ["/bin/bash", "-c"]
# Set the locale
RUN echo 'Acquire {http::Pipeline-Depth "0";};' >> /etc/apt/apt.conf
RUN DEBIAN_FRONTEND="noninteractive"
RUN apt-get update && apt-get -y install --no-install-recommends locales && locale-gen en_US.UTF-8
ENV LANG en_US.UTF-8
ENV LANGUAGE en_US:en
ENV LC_ALL en_US.UTF-8
RUN apt-get install -y --no-install-recommends \
wget \
git \
python3-pip \
openssh-client \
python3-setuptools \
google-perftools && \
rm -rf /var/lib/apt/lists/*
# install conda
WORKDIR /tmp
RUN wget --quiet https://repo.anaconda.com/miniconda/Miniconda3-4.7.12-Linux-x86_64.sh -O ~/miniconda.sh && \
/bin/bash ~/miniconda.sh -b -p /opt/conda && \
rm ~/miniconda.sh && \
ln -s /opt/conda/etc/profile.d/conda.sh /etc/profile.d/conda.sh && \
echo ". /opt/conda/etc/profile.d/conda.sh" >> ~/.bashrc
# build conda environments
COPY environment.yml /tmp/kubeflow-mnist/conda/
RUN /opt/conda/bin/conda update -n base -c defaults conda
RUN /opt/conda/bin/conda env create -f /tmp/kubeflow-mnist/conda/environment.yml
RUN /opt/conda/bin/conda clean -afy
# Cleanup
RUN rm -rf /workspace/{nvidia,docker}-examples && rm -rf /usr/local/nvidia-examples && \
rm /tmp/kubeflow-mnist/conda/environment.yml
# switch to the conda environment
RUN echo "conda activate kubeflow-mnist" >> ~/.bashrc
ENV PATH /opt/conda/envs/kubeflow-mnist/bin:$PATH
RUN /opt/conda/bin/activate kubeflow-mnist
# make /bin/sh symlink to bash instead of dash:
RUN echo "dash dash/sh boolean false" | debconf-set-selections && \
DEBIAN_FRONTEND=noninteractive dpkg-reconfigure dash
# Set the new Allocator
ENV LD_PRELOAD /usr/lib/x86_64-linux-gnu/libtcmalloc.so.
关于Dockerfile值得关注的重要一点是Conda环境是否设置完成并准备就绪。要构建镜像:
% docker build -t your-user-name/kubeflow-mnist . -f Dockerfile
% docker push your-user-name/kubeflow-mnist
那么,现在让我们来创建第一个组件!
在pipeline.py中可以找到以下代码片段。
Step1:Git Clone
在这一步中,我们将从远程的Git代码库中执行一个git clone。特别是,我想要向你展示如何从私有仓库中进行git clone,因为这是大多数企业的项目所在的位置。当然,这也是一个很好的机会来演示Rancher中一个很棒的功能,它能简单地添加诸如SSH密钥之类的密钥。
使用Rancher添加密钥
访问Rancher界面。在左上角,选择local,然后选择二级菜单的Default:
然后,选择Resources下的Secrets
你应该看到一个密钥的列表,它们正在被你刚刚选择的集群所使用。点击Add Secret:
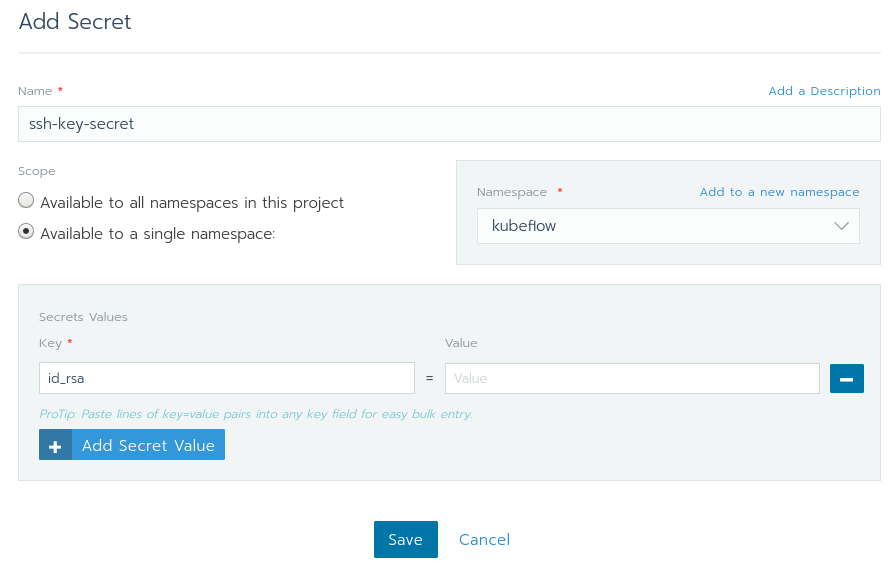
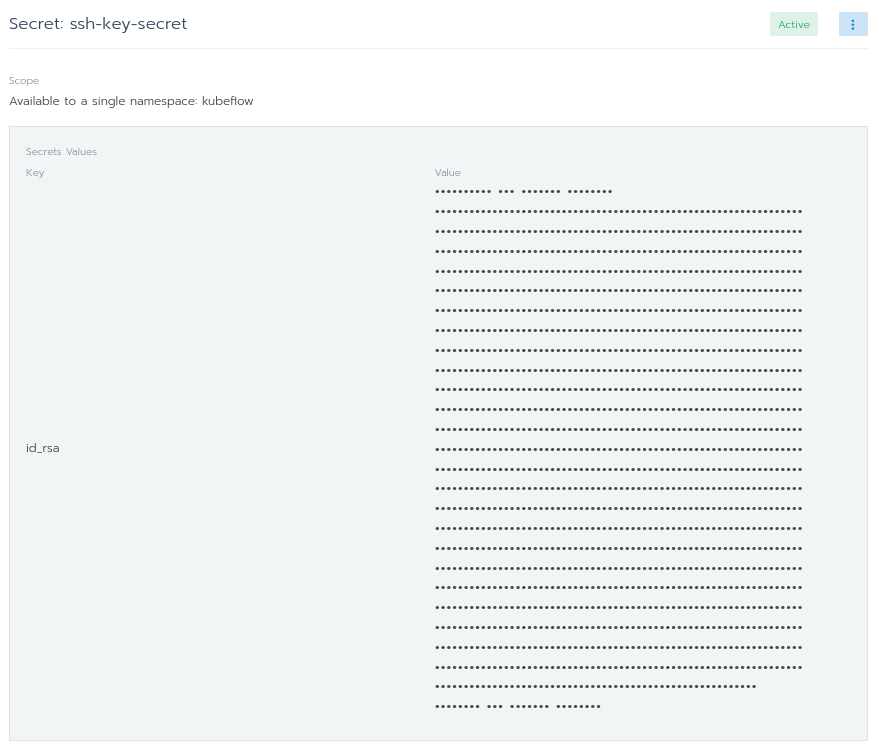
使用你在下图中所看到的值来填写该页面。如果kubeflow没有在命名空间栏下展示出来,你可以通过选择Add to a new namespace并且输入kubeflow简单地创建一个。
确保Scope仅是个命名空间。如果将Scope设置为所有命名空间,那么将使得在Default项目中的任意工作负载都能够使用你的ssh密钥。
在Secret Values中,key是id_rsa,值是id_rsa的内容。完成之后,点击Save。
如果一些进展顺利,你将会看到下图的内容。现在你已经成功地在kubeflow命名空间中添加了你的SSH密钥,并且无需使用kubectl!
既然我们已经添加了我们的SSH key,那么是时候回到代码。我们如何利用新添加的SSH密钥来访问私有git仓库?
def git_clone_darkrai_op(repo_url: str):
volume_op = dsl.VolumeOp(
name="create pipeline volume",
resource_name="pipeline-pvc",
modes=["ReadWriteOnce"],
size="3Gi"
)
image = 'alpine/git:latest'
commands = [
"mkdir ~/.ssh",
"cp /etc/ssh-key/id_rsa ~/.ssh/id_rsa",
"chmod 600 ~/.ssh/id_rsa",
"ssh-keyscan bitbucket.org >> ~/.ssh/known_hosts",
f"git clone {repo_url} {PROJECT_ROOT}",
f"cd {PROJECT_ROOT}"]
op = dsl.ContainerOp(
name='git clone',
image=image,
command=['sh'],
arguments=['-c', ' && '.join(commands)],
container_kwargs={'image_pull_policy': 'IfNotPresent'},
pvolumes={"/workspace": volume_op.volume}
)
# Mount Git Secrets
op.add_volume(V1Volume(name='ssh-key-volume',
secret=V1SecretVolumeSource(secret_name='ssh-key-secret')))
op.add_volume_mount(V1VolumeMount(mount_path='/etc/ssh-key', name='ssh-key-volume', read_only=True))
return op
首先,创建一个Kubernetes volume,预定义大小为3Gi。其次,将image变量指定为我们将要使用的alpine/git Docker镜像。之后是在Docker容器中执行的命令列表。这些命令实质上是设置SSH密钥的,以便于流水线可以从私有仓库git clone,或者使用git://URL来代替 https://。
该函数的核心是下面一行,返回一个dsl.ContainerOp。
command和arguments指定了执行镜像之后需要执行的命令。
最后一个变量十分有趣,是pvolumes,它是Pipeline Volumes简称。它创建一个Kubernetes volume并允许流水线组件来共享单个存储。该volume被挂载在/workspace上。那么这个组件要做的就是把仓库git clone到/workspace中。
使用Secrets
再次查看命令和复制SSH密钥的位置。
流水线volume在哪里创建呢?当我们将所有组件都整合到一个流水线中时,就会看到创建好的volume。我们在/etc/ssh-key/上安装secrets:
op.add_volume_mount(V1VolumeMount(mount_path='/etc/ssh-key', name='ssh-key-volume', read_only=True))
请记得我们将secret命名为ssh-key-secret:
op.add_volume(V1Volume(name='ssh-key-volume',
secret=V1SecretVolumeSource(secret_name='ssh-key-secret')))
通过使用相同的volume名称ssh-key-volume,我们可以把一切绑定在一起。
Step2:预处理
def preprocess_op(image: str, pvolume: PipelineVolume, data_dir: str):
return dsl.ContainerOp(
name='preprocessing',
image=image,
command=[CONDA_PYTHON_CMD, f"{PROJECT_ROOT}/preprocessing.py"],
arguments=["--data_dir", data_dir],
container_kwargs={'image_pull_policy': 'IfNotPresent'},
pvolumes={"/workspace": pvolume}
)
正如你所看到的, 预处理步骤看起来十分相似。
image指向我们在Step0中创建的Docker镜像。
这里的command使用指定的conda python简单地执行了preprocessing.py脚本。变量data_dir被用于执行preprocessing.py脚本。
在这一步骤中pvolume将在/workspace里有仓库,这意味着我们所有的脚本在这一阶段都是可用的。并且在这一步中预处理数据会存储在/workspace下的data_dir中。
Step3:训练和评估
def train_and_eval_op(image: str, pvolume: PipelineVolume, data_dir: str, ):
return dsl.ContainerOp(
name='training and evaluation',
image=image,
command=[CONDA_PYTHON_CMD, f"{PROJECT_ROOT}/train.py"],
arguments=["--data_dir", data_dir],
file_outputs={'output': f'{PROJECT_ROOT}/output.txt'},
container_kwargs={'image_pull_policy': 'IfNotPresent'},
pvolumes={"/workspace": pvolume}
)
最后,是时候进行训练和评估这一步骤。这一步唯一的区别在于file_outputs变量。如果我们再次查看train.py,则有以下代码段:
with open(os.path.join(PROJECT_ROOT, 'output.txt'), 'w') as f:
f.write(model_path)
print(f'Model written to: {model_path}')
我们正在将模型路径写入名为output.txt的文本文件中。通常,可以将其发送到下一个流水线组件,在这种情况下,该参数将包含模型的路径。
将一切放在一起
要指定流水线,你需要使用dsl.pipeline来注释流水线功能:
@dsl.pipeline(
name='Fashion MNIST Training Pipeline',
description='Fashion MNIST Training Pipeline to be executed on KubeFlow.'
)
def training_pipeline(image: str = 'benjamintanweihao/kubeflow-mnist',
repo_url: str = 'https://github.com/benjamintanweihao/kubeflow-mnist.git',
data_dir: str = '/workspace'):
git_clone = git_clone_darkrai_op(repo_url=repo_url)
preprocess_data = preprocess_op(image=image,
pvolume=git_clone.pvolume,
data_dir=data_dir)
_training_and_eval = train_and_eval_op(image=image,
pvolume=preprocess_data.pvolume,
data_dir=data_dir)
if __name__ == '__main__':
import kfp.compiler as compiler
compiler.Compiler().compile(training_pipeline, __file__ + '.tar.gz')
还记得流水线组件的输出是另一个组件的输入吗?在这里,git clone、container_op的pvolume将传递到preprocess_cp。
最后一部分将pipeline.py转换为可执行脚本。最后一步是编译流水线:
% dsl-compile --py pipeline.py --output pipeline.tar.gz
上传并执行流水线
现在要进行最有趣的部分啦!第一步,上传流水线。点击Upload a pipeline:
接下来,填写Pipeline Name和Pipeline Description,然后选择Choose file并且指向pipeline.tar.gz以上传流水线。
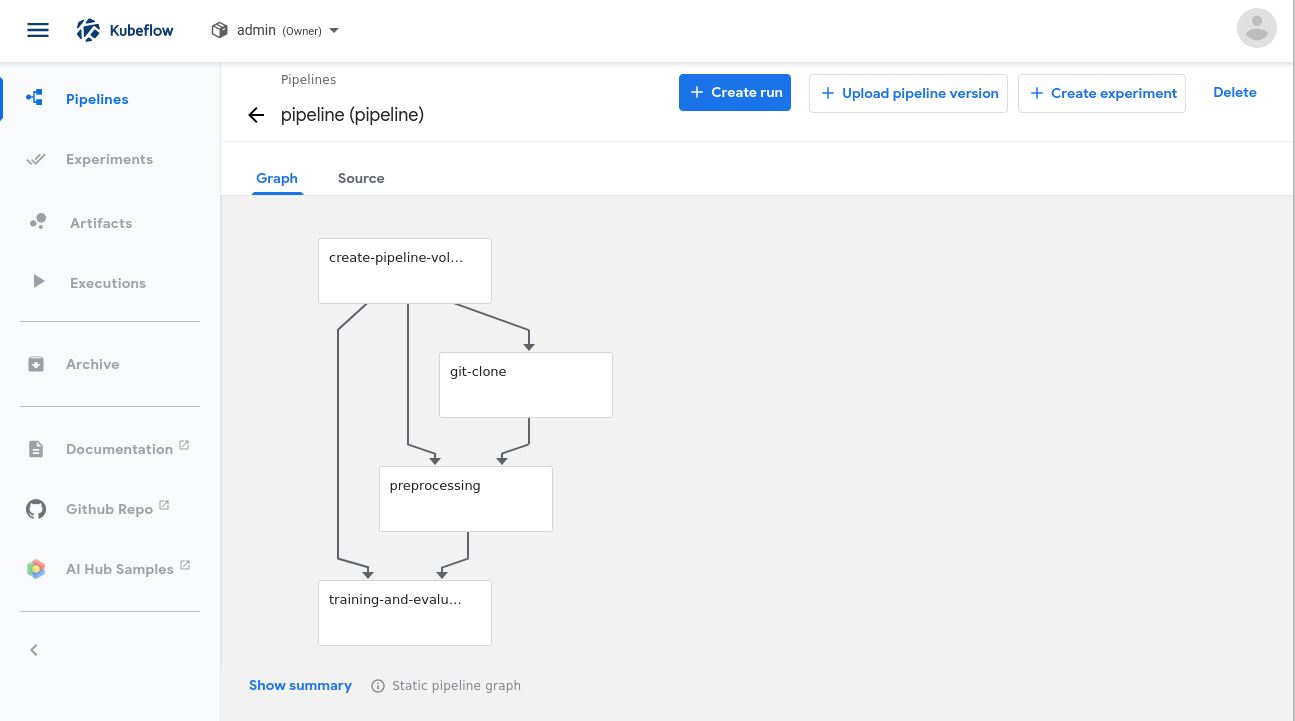
下一页将会展示完整的流水线。我们所看到的是一个流水线的有向无环图,在本例中这意味着依赖项会通往一个方向并且它不包含循环。点击蓝色按钮Create run 以开始训练。
大部分字段已经已经填写完毕。请注意,Run parameters与使用@ dsl.pipeline注释的training_pipeline函数中指定的参数相同:
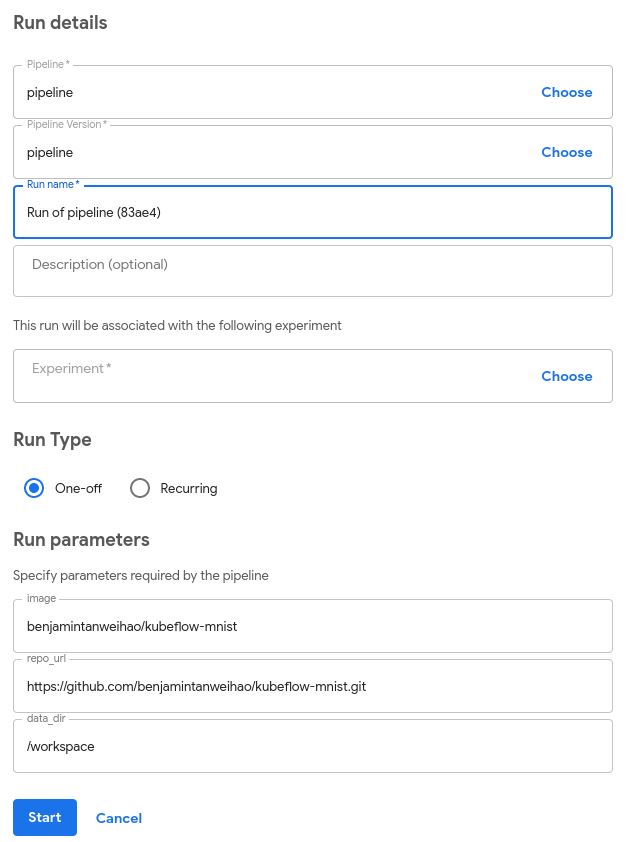
最后,当你点击蓝色的Start按钮时,整个流水线就开始运转了!你点击每个组件并查看日志就能够知道发生了什么。当整个流水线执行完毕时,在所有组件的右方会有一个绿色的确认标志,如下所示:
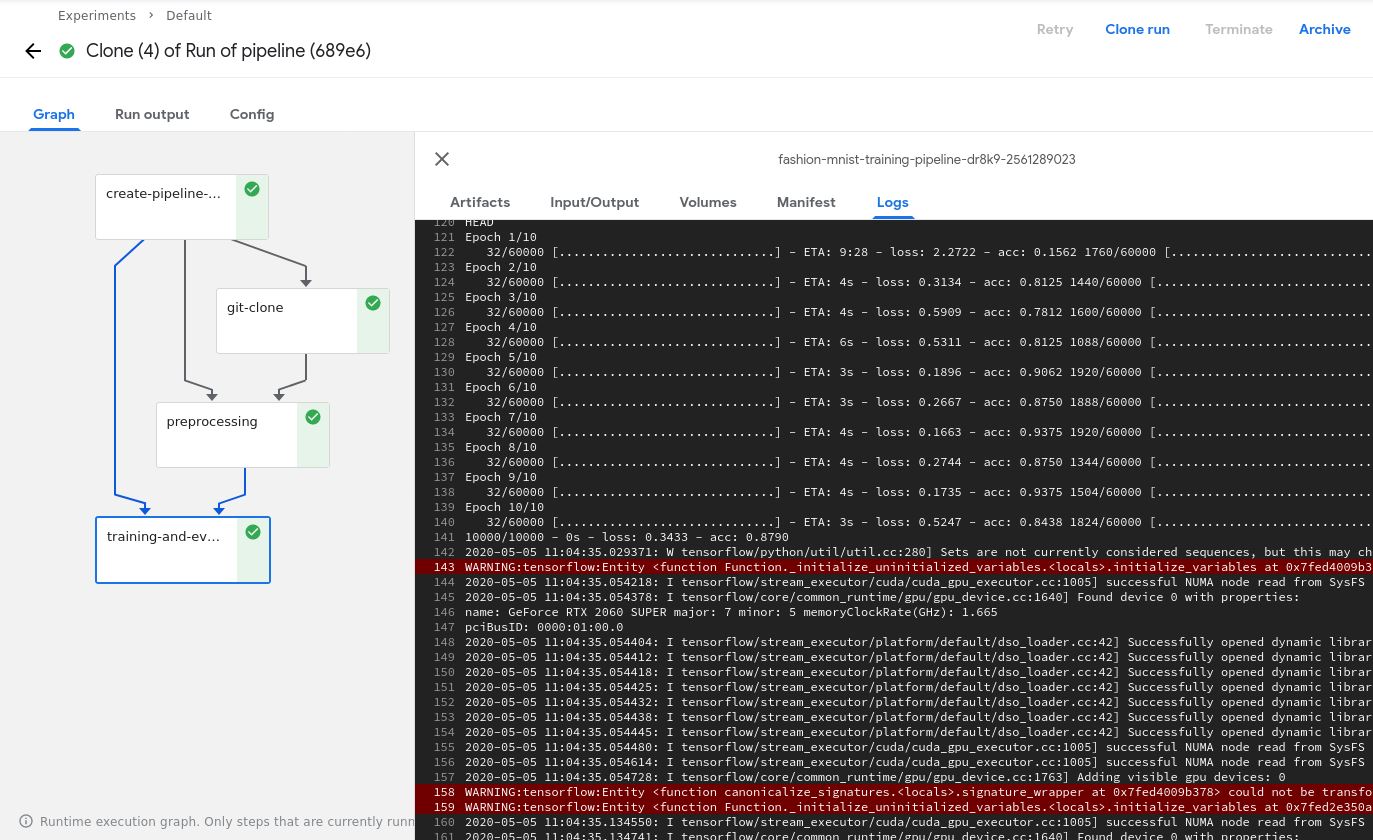
结论
如果你从上一篇文章开始就一直在关注,那么你应该已经安装了Kubeflow,并且应该能体会到大规模管理机器学习项目的复杂性。
在这篇文章中,我们先介绍了为Kubeflow准备一个机器学习项目的过程,然后是构建一个Kubeflow流水线,最后是使用Kubeflow接口上传并执行流水线。这种方法的奇妙之处在于,你的机器学习项目可以是简单的,也可以是复杂的,只要你愿意,你就可以使用相同的技术。
因为Kubeflow使用Docker容器作为组件,你可以自由地加入任何你喜欢的工具。而且由于Kubeflow运行在Kubernetes上,你可以让Kubernetes处理机器学习工作负载的调度。
我们还了解了一个我喜欢的Rancher功能,它十分方便,可以轻松添加secrets。立刻,你就可以轻松地组织secrets(如SSH密钥),并选择将其分配到哪个命名空间,而无需为Base64编码而烦恼。就像Rancher的应用商店一样,这些便利性使Kubernetes的工作更加愉快,更不容易出错。
当然,Rancher提供的服务远不止这些,我鼓励你自己去做一些探索。我相信你会偶然发现一些让你大吃一惊的功能。Rancher作为一个开源的企业级Kubernetes管理平台,Run Kubernetes Everywhere一直是我们的愿景和宗旨。开源和无厂商锁定的特性,可以让用户轻松地在不同的基础设施部署和使用Rancher。此外,Rancher极简的操作体验也可以让用户在不同的场景中利用Rancher提升效率,帮助开发人员专注于创新,而无需在繁琐的小事中浪费精力。
使用Kubeflow构建机器学习流水线的更多相关文章
- 解锁云原生 AI 技能|在 Kubernetes 上构建机器学习系统
本系列将利用阿里云容器服务,帮助您上手 Kubeflow Pipelines. 介绍 机器学习的工程复杂度,除了来自于常见的软件开发问题外,还和机器学习数据驱动的特点相关.而这就带来了其工作流程链路更 ...
- spark ml pipeline构建机器学习任务
一.关于spark ml pipeline与机器学习一个典型的机器学习构建包含若干个过程 1.源数据ETL 2.数据预处理 3.特征选取 4.模型训练与验证 以上四个步骤可以抽象为一个包括多个步骤的流 ...
- 入门系列之Scikit-learn在Python中构建机器学习分类器
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由信姜缘 发表于云+社区专栏 介绍 机器学习是计算机科学.人工智能和统计学的研究领域.机器学习的重点是训练算法以学习模式并根据数据进行预 ...
- 使用Flask构建机器学习模型API
1. Python环境设置和Flask基础 使用"Anaconda"创建一个虚拟环境.如果你需要在Python中创建你的工作流程,并将依赖项分离出来,或者共享环境设置," ...
- 使用 TensorFlow 构建机器学习项目中文版·翻译完成
原文:Building Machine Learning Projects with TensorFlow 协议:CC BY-NC-SA 4.0 不要担心自己的形象,只关心如何实现目标.--<原 ...
- 【Scala-ML】使用Scala构建机器学习工作流
引言 在这一小节中.我将介绍基于数据(函数式)的方法来构建数据应用.这里会介绍monadic设计来创建动态工作流,利用依赖注入这种高级函数式特性来构建轻便的计算工作流. 建模过程 在统计学和概率论中, ...
- openshift 持续集成与部署 -- 构建部署流水线
Jenkins持续构建说得更直白点,就是各种项目的"自动化"编译.打包.分发部署.j跟svn.git能无缝集成,也支持直接与知名源代码托管网站,比如github.bitbucket ...
- Docker+Rancher构建部署流水线
工作多年,在项目部署方面, 1:以前用ftp或者rz上传更新的,每次更新算上打包.目录切换.更新遗漏.备份.出错还原.启动等工作都得搞上一来小时甚至更长,要是多两台服务器那心都凉了: 2:后来有用sv ...
- 像Google一样构建机器学习系统3 - 利用MPIJob运行ResNet101
本系列将利用阿里云容器服务,帮助您上手Kubeflow Pipelines. 第一篇:在阿里云上搭建Kubeflow Pipelines 第二篇:开发你的机器学习工作流 第三篇:利用MPIJob运行R ...
随机推荐
- Istio VirtualService 虚拟服务
概念及示例 VirtualService 描述了一个或多个用户可寻址目标到网格内实际工作负载之间的映射 . 虚拟服务让您配置如何在服务网格内将请求路由到服务,这基于 Istio 和平台提供的基本的连通 ...
- MySQL递归查询
MySQL8.0已经支持CTE递归查询,举例说明 CREATE TABLE EMP (EMPNO integer NOT NULL, ENAME ), JOB ), MGR integer, HIRE ...
- MvvmLight + Microsoft.Extensions.DependencyInjection + WpfApp(.NetCore3.1)
git clone MvvmLight失败,破网络, 就没有直接修改源码的方式来使用了 Nuget安装MvvmLightLibsStd10 使用GalaSoft.MvvmLight.Command命名 ...
- Xilinx ISE多功能移位寄存器仿真及Basys2实验板实验
移位寄存器实现Verilog代码: `timescale 1ns / 1ps module add( input clk, input reset, input [1:0] s, input dl, ...
- 01 . HAProxy原理使用和配置
HaProxy简介 HaProxy是什么? HAProxy是一个免费的负载均衡软件,可以运行于大部分主流的Linux操作系统上. HAProxy提供了L4(TCP)和L7(HTTP)两种负载均衡能力, ...
- 附021.Traefik-ingress部署及使用
一 Helm部署 1.1 获取资源 [root@master01 ~]# mkdir ingress [root@master01 ~]# cd ingress/ [root@master01 ing ...
- Rocket - diplomacy - ValName
https://mp.weixin.qq.com/s/so-2x5KLfYF0IMCCqNThwQ 简单调试ValName实现: 1. 使用 Desugar之后如下: ...
- 【Springboot HBase】遇到的一些问题
想要运行的代码需要在application中运行 使用@Component并实现CommandLineRunner接口.重写方法@Override run( ) @Component public c ...
- Spring Boot笔记(三) springboot 集成 Quartz 定时任务
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1. 在 pom.xml 中 添加 Quartz 所需要 的 依赖 <!--定时器 quartz- ...
- golang内存逃逸
golang程序变量会携带油一组校验数据,用来证明它的整个生命周期是否在运行时完全可知.如果变量通过了这些校验,它就可以在栈上分配.否则就说它逃逸了,必须在堆上分配 能引起变量逃逸到堆上的典型 ...