Python之TestLink篇
如何让时间变慢?
你们不知道吧,这个时候翻开书,时间又变慢了一倍,可以这样延年益寿,哈哈哈
—————————————————————————————————————————————————————————————————————————
回归正题
TestLink是一款基于web的测试用例管理系统,功能对于测试来讲挺齐全,例如
*测试项目管理
*产品需求管理
*测试用例管理
*测试计划管理
*测试用例的创建、管理和执行
*测试报告
好奇怪,讲那么多有点干嘛,我又不是卖软件的。
1.安装testlink第三方模块
`pip3 install -i https://pypi.doubanio.com/simple/ TestLink-API-Python-client`
2.Python连接上testlink
获取testlink秘钥,用于做python和testlink之间进行连接。
1.登陆testlink
2.点击我的设置
3.找到api接口,点击生成,复制下来即可,替换到下方代码中
import testlink
# 此处请将192.168.0.233/testlink替换为自己TestLink的访问地址即可
url = "http://192.168.0.233/testlink/lib/api/xmlrpc/v1/xmlrpc.php"
# 此处将密钥更换为个人秘钥即可
key = "6250b9d9cb5fc7c982c4c35adffaaf52"
tlc = testlink.TestlinkAPIClient(url, key)
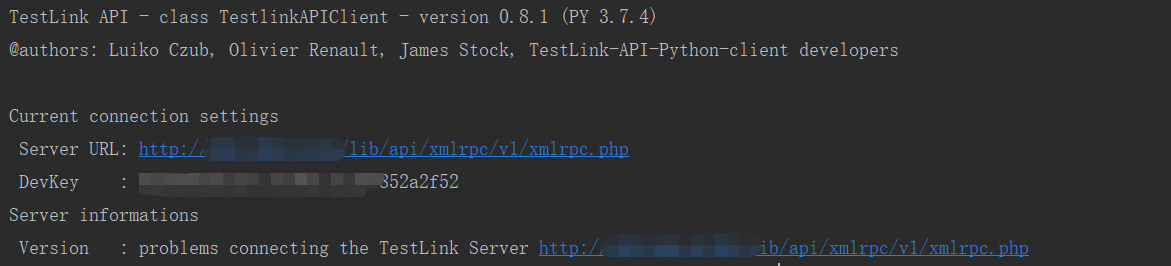
print(tlc)
此时打印出的tlc就能看到作者和版本的一些信息
3.获取Testlink中的内容及执行测试
此处要注意,在TestLink中创建的工程必须要将工程的活动和公共勾选上,不然你会发现你的代码获取不到TestLink中的数据
下方代码中的所有参数,例如id,url,秘钥,projectname都要替换成自己testlink中真是存在的参数
一下仅为演示
import testlink
import re
# 此处请将192.168.0.233替换为自己TestLink的访问地址即可
url = "http://192.168.0.233/testlink/lib/api/xmlrpc/v1/xmlrpc.php"
# 此处将密钥更换为个人秘钥即可
key = "6250b9d9cb5fc7c982c4c35adffaaf52"
tlc = testlink.TestlinkAPIClient(url, key)
# 获取TestLink下所有的项目 返回为包含字典的列表
projects = tlc.getProjects()
print("projects.....%s" % projects)
# 通过项目名称获取项目id 项目名称存在返回项目id,不存在则返回-1
ProjectID = tlc.getProjectIDByName("BB04Pfpga")
print("ProjectID.....%s" % ProjectID)
# 通过项目id获取项目下的测试计划 返回嵌套字典的列表 如果工程id不存在 则抛出TLResponseError异常
ProjectTestPlans = tlc.getProjectTestPlans("40753")
print("ProjectTestPlans.....%s" % ProjectTestPlans)
# 通过测试计划id返回 该计划下的所有套件
# 此处要将计划设置为活动和打开
TestSuite = tlc.getTestSuitesForTestPlan("56327")
print("TestSuite.....%s" % TestSuite)
"""
getTestCasesForTestSuite:获取测试套件下的用例
testsuiteid:测试套件id
deep:默认为True,为True时会返回子级套件下的用例
details:默认为simple,当更改参数为full时,会返回用例的详细内容
return:返回嵌套字典的列表,用例的详细内容
"""
Cases = tlc.getTestCasesForTestSuite(testsuiteid="42960", deep=True, details="simple")
print("Cases.....%s" % Cases)
# 获取测试计划下的版本信息 返回为嵌套字典的列表
version = tlc.getBuildsForTestPlan("56327")
print("version.....%s" % version)
"""
getTestCasesForTestPlan:获取测试计划下对应版本的caseID
testplanid:测试计划id
buildid:测试计划下版本id
return:用例一些主要信息,例如caseID,case_name,external_id等
"""
TestCases = tlc.getTestCasesForTestPlan(testplanid="56327", buildid="85")
# 此时获取到了用例的所有信息,取出用例ID
"""
此时获取到了用例的所有信息,获取到的结果中,
execution_type值为1表示手工
execution_type值为2表示自动
此时取出所有自动的caseID,保存下来
"""
auto_caseID = []
for case_id, describe in TestCases.items():
if describe[0]['execution_type'] == '2':
auto_caseID.append(case_id)
# 通过getTestCase方法获取所有自动的用例的详细信息
# 传入参数为用例的ID
for ID in auto_caseID:
detailed_cases = tlc.getTestCase(ID)
# print(detailed_cases)
"""
获取一条用例的详细信息,用例中包含用例的每一个步骤,用例
的编写者,状态,期望结果,名称等信息
此时获取所有自动的步骤,及期望结果
execution_type值为1表示手工
execution_type值为2表示自动
"""
detailed_cases = tlc.getTestCase("42811")
print(detailed_cases)
for item in detailed_cases:
for step in item['steps']:
if step['execution_type'] == '2':
print(f"actions:{step['actions']}......expected_results:{step['expected_results']}")
# 发送测试结果到TestLink中
"""
参数为
caseID
测试计划ID
第4个参数 p为通过,f为不通过
最后一个参数为版本id
"""
tlc.reportTCResult("52191", "56001", None, 'p', "", guess=True, platformname="", buildid="66")
——————————————————————————————————————————————————————————————————————
在上方获取用例步骤初打印出来的信息你会发现包含一些html的标签
使用re和replace进行替换即可
def data_handle(data):
"""
用于处理从testlink中获取的数据进行处理
:param data: 传入的数据
:return: 返回数据为处理后的数据
"""
data = data.replace('\r', '')
data = data.replace('\t', '')
data = data.replace('\n', '')
data = data.replace(' ', ' ') # 替换空格
data = data.replace('’', '"') # 转换中文单引号 ’为英文的 "
data = data.replace('‘', '"') # 转换中文单引号‘ 为英文的 "
data = data.replace('“', '"') # 转换中文双引号“ 为英文的 "
data = data.replace('”', '"') # 转换中文双引号 ” 为英文的 "
data = data.replace(':', ":") # 转换中文的冒号 :为英文的冒号 :
data = data.replace(',', ',') # 转换中文的逗号 ,为英文的逗号 ,
data = data.replace('"', '\"') # 转换 " 为双引号
data = data.replace(''', '\'') # 转换 ' 为单引号
data = data.replace('{', '{') # 转换中文{ 为英文的 {
data = data.replace('}', '}') # 转换中文 } 为英文的 }
data = data.replace('<', '<') # 转换 < 为 <
data = data.replace('>', '>') # 转换 >为 >
data = data.replace('&', '&')
data = data.replace('【', '[')
data = data.replace('】', ']')
# 查找类似这类内容 </pre>、</div> 并替换为空
result_list = re.findall('</.?>', data)
if result_list:
for item in result_list:
data = data.replace(item, '')
# 查找类似这类内容 <pre style="background-color:#ffffff;color:#000000;font-family:'宋体';font-size:12pt;"> 并替换为空
result_list = re.findall('<.?[^<]*>', data)
if result_list:
for item in result_list:
data = data.replace(item, '')
data = data.lstrip()
return data
# 此处整理了一下 没有进行封装,只是单纯的获取所有的用例步骤及期望结果
url = "http://192.168.0.233/testlink/lib/api/xmlrpc/v1/xmlrpc.php"
key = "6250b9d9cb5fc7c982c4c35adffaaf52"
tlc = testlink.TestlinkAPIClient(url, key)
TestCases = tlc.getTestCasesForTestPlan(testplanid="56327", buildid="85")
auto_caseID = []
for case_id, describe in TestCases.items():
if describe[0]['execution_type'] == '2':
auto_caseID.append(case_id)
for ID in auto_caseID:
detailed_cases = tlc.getTestCase(ID)
for item in detailed_cases:
for step in item['steps']:
if step['execution_type'] == '2':
action = data_handle(step['actions'])
expected_result = data_handle(step['expected_results'])
print(f"action:{action}......expected_result:{expected_result}")
tlc.reportTCResult("52191", "56001", None, 'p', "", guess=True, platformname="", buildid="66")
此时已经建立连接TestLink,获取项目,计划,套件,版本,筛选出自动的用例数据和期望结果,以及执行测试,发送测试结果。
每一层都是嵌套的关系,一个项目可以有多个计划,一个计划下又可以有多个版本。
我们已经拿到了数据,期望结果能做什么事呢?
- ui自动化
它就很适合用这个结构,每一步可以有期望结果,可以没有,查找到对应的元素后,在界面中找到一些关
键字等信息,进行验证,验证这条是否成功。 - 接口自动化
将接口地址,请求参数,请求方式,返回结果,定义一个固定的步骤,第一步放url,第二步放请求参数,
第三部放请求方式,第四步放期望结果,和拿到的数据进行对比。
当然这些都是个人想法,还没有真正的拿去实践,是否合理等,欢迎补充。
Python之TestLink篇的更多相关文章
- Python+Selenium练习篇之1-摘取网页上全部邮箱
前面已经介绍了Python+Selenium基础篇,通过前面几篇文章的介绍和练习,Selenium+Python的webUI自动化测试算是入门了.接下来,我计划写第二个系列:练习篇,通过一些练习,了解 ...
- Python人工智能第一篇:语音合成和语音识别
Python人工智能第一篇:语音合成和语音识别 此篇是人工智能应用的重点,只用现成的技术不做底层算法,也是让初级程序员快速进入人工智能行业的捷径.目前市面上主流的AI技术提供公司有很多,比如百度, ...
- Python人工智能第二篇:人脸检测和图像识别
Python人工智能第二篇:人脸检测和图像识别 人脸检测 详细内容请看技术文档:https://ai.baidu.com/docs#/Face-Python-SDK/top from aip impo ...
- 第六篇:Python函数进阶篇
在了解完了 Python函数基础篇之后,本篇的存在其实是为了整合知识,由于该篇的知识是否杂乱,故大家可以通过点开点连接直接进入其详细介绍,该篇主要大致的介绍一下几个知识点: 一.Python的迭代器 ...
- pyinstaller打包的exe太大?你需要嵌入式python玄学 探索篇
上篇我们讲到pip的安装以及普通库用pip的安装方法 CodingDog:pyinstaller打包的exe太大?你需要嵌入式python玄学 拓展篇zhuanlan.zhihu.com 问题纷沓而 ...
- pyinstaller打包的exe太大?你需要嵌入式python玄学 拓展篇
上篇我们讲到embedded版本的基础操作 CodingDog:pyinstaller打包的exe太大?你需要嵌入式python玄学 惊喜篇zhuanlan.zhihu.com 可是却没有办法用pi ...
- pyinstaller打包的exe太大?你需要嵌入式python玄学 惊喜篇
上篇讲到 pyinstaller打包exe太大的问题 CodingDog:pyinstaller打包的exe太大?你需要嵌入式python玄学 前提篇zhuanlan.zhihu.com 那既然py ...
- Python+Selenium中级篇之8-Python自定义封装一个简单的Log类《转载》
Python+Selenium中级篇之8-Python自定义封装一个简单的Log类: https://blog.csdn.net/u011541946/article/details/70198676
- 《python开发技术详解》|百度网盘免费下载|Python开发入门篇
<python开发技术详解>|百度网盘免费下载|Python开发入门篇 提取码:2sby 内容简介 Python是目前最流行的动态脚本语言之一.本书共27章,由浅入深.全面系统地介绍了利 ...
随机推荐
- STL之内存管理
STL以泛型思维为基础,提供了6大组件:容器(containers).算法(algorithms).迭代器(iterators).仿函数(functors).适配器(adapters).分配器(all ...
- MES系统的模型结构和主要功能(二)
上一节,我们主要说了Mes系统是什么,以及它的特点和难点,本节,再来讨论一下一个合格的MES系统的模型结构和基本功能. 现代工厂的快速发展,对MES系统提出了更高的要求,其必须满足范围广泛的任务要求, ...
- P1191 矩形
------------恢复内容开始------------ 题意 给出一个\(n*n\)的矩阵,矩阵中,有些格子被染成白色,有些格子被染成黑色,现要求矩阵中白色矩形的数量 分割线 Ⅰ.暴力出奇迹!! ...
- C. Helga Hufflepuff's Cup 树形dp 难
C. Helga Hufflepuff's Cup 这个题目我感觉挺难的,想了好久也写了很久,还是没有写出来. dp[i][j][k] 代表以 i 为根的子树中共选择了 j 个特殊颜色,且当前节点 i ...
- 初识Java和JDK下载安装
故事:Java帝国的诞生 对手: C&C++ ◆1972年C诞生 ◆贴近硬件,运行极快,效率极高. ◆操作系统,编译器,数据库,网络系统等 ◆指针和内存管理 ◆1982年C++诞生 ◆面向对象 ...
- Spring官网阅读(五)BeanDefinition(下)
上篇文章已经对BeanDefinition做了一系列的介绍,这篇文章我们开始学习BeanDefinition合并的一些知识,完善我们整个BeanDefinition的体系,Spring在创建一个bea ...
- 中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnltk、snownlp、thulac)
2.1 jieba 2.1.1 jieba简介 Jieba中文含义结巴,jieba库是目前做的最好的python分词组件.首先它的安装十分便捷,只需要使用pip安装:其次,它不需要另外下载其它的数据包 ...
- Mybatis学习笔记汇总(包括源码和jar包)
博客整理 Mybatis学习笔记(一)--对原生jdbc中问题的总结 Mybatis学习笔记(二)--Mybatis框架 Mybatis学习笔记(三)--入门程序 MyBatis学习笔记(四)--入门 ...
- 浅谈mybatis如何半自动化解耦和ORM实现
在JAVA发展过程中,涌现出一系列的ORM框架,JPA,Hibernate,Mybatis和Spring jdbc,本系列,将来研究Mybatis. 通过研究mybatis源码,可将mybatis的大 ...
- VMware Tanzu已融合云原生与K8s 市场前景尚不确定
Tanzu是什么? Tanzu 结合了Wavefront IT监控的项目和产品,VMware于2017年5月收购了该软件,并加入了Cloud Foundry PaaS实用工具.VMware在2019年 ...