k-means聚类分析 python 代码实现(不使用现成聚类库)
一、实验目标
1、使用 K-means 模型进行聚类,尝试使用不同的类别个数 K,并分析聚类结果。
二、算法原理
首先确定k,随机选择k个初始点之后所有点根据距离质点的距离进行聚类分析,离某一个质点a相较于其他质点最近的点分配到a的类中,根据每一类mean值更新迭代聚类中心,在迭代完成后分别计算训 练集和测试集的损失函数SSE_train、SSE_test,画图进行分析。

伪代码如下:
num=10 #k的种类
for k in range(1,num):
随机选择k个质点
for i in range(n): #迭代n次
根据点与质点间的距离对于X_train进行聚类
根据mean值迭代更新质点
计算SSE_train
计算SSE_test
画图
算法流程图:

三、代码实现
1、导入库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
2、计算距离
def distance(p1,p2):
return np.sqrt((p1[0]-p2[0])**2+(p1[1]-p2[1])**2)
3、计算均值
def means(arr):
return np.array([np.mean([p[0] for p in arr]),np.mean([p[1] for p in arr])])
4、二维数据处理
#数据处理
data= pd.read_table('cluster.dat',sep='\t',header=None)
data.columns=['x']
data['y']=None
for i in range(len(data)): #遍历每一行
column = data['x'][i].split( ) #分开第i行,x列的数据。split()默认是以空格等符号来分割,返回一个列表
data['x'][i]=column[0] #分割形成的列表第一个数据给x列
data['y'][i]=column[1] #分割形成的列表第二个数据给y列
list=[]
list1=[]
for i in range(len(data)):
list.append(float(data['x'][i]))
list.append(float(data['y'][i]))
list1.append(list)
list=[]
arr=np.array(list1)
print(arr)

5、划分数据集和训练集
#按照8:2划分数据集和训练集
X_train, X_test = train_test_split(arr,test_size=0.2,random_state=1)
6、主要聚类实现
count=10 #k的种类:1、2、3...10
SSE_train=[] #训练集的SSE
SSE_test=[] #测试集的SSE
n=20 #迭代次数
for k in range(1,count):
cla_arr=[] #聚类容器
centroid=[] #质点
for i in range(k):
j=np.random.randint(0,len(X_train))
centroid.append(list1[j])
cla_arr.append([])
centroids=np.array(centroid)
cla_tmp=cla_arr #临时训练集聚类容器
cla_tmp1=cla_arr #临时测试集聚类容器
for i in range(n): #开始迭代
for e in X_train: #对于训练集中的点进行聚类分析
pi=0
min_d=distance(e,centroids[pi])
for j in range(k):
if(distance(e,centroids[j])<min_d):
min_d=distance(e,centroids[j])
pi=j
cla_tmp[pi].append(e) #添加点到相应的聚类容器中 for m in range(k):
if(n-1==i):
break
centroids[m]=means(cla_tmp[m])#迭代更新聚类中心
cla_tmp[m]=[]
dis=0
for i in range(k): #计算训练集的SSE_train
for j in range(len(cla_tmp[i])):
dis+=distance(centroids[i],cla_tmp[i][j])
SSE_train.append(dis) col = ['HotPink','Aqua','Chartreuse','yellow','red','blue','green','grey','orange'] #画出对应K的散点图
for i in range(k):
plt.scatter([e[0] for e in cla_tmp[i]],[e[1] for e in cla_tmp[i]],color=col[i])
plt.scatter(centroids[i][0],centroids[i][1],linewidth=3,s=300,marker='+',color='black')
plt.show() for e in X_test: #测试集根据训练集的质点进行聚类分析
ki=0
min_d=distance(e,centroids[ki])
for j in range(k):
if(distance(e,centroids[j])<min_d):
min_d=distance(e,centroids[j])
ki=j
cla_tmp1[ki].append(e)
for i in range(k): #计算测试集的SSE_test
for j in range(len(cla_tmp1[i])):
dis+=distance(centroids[i],cla_tmp1[i][j])
SSE_test.append(dis)
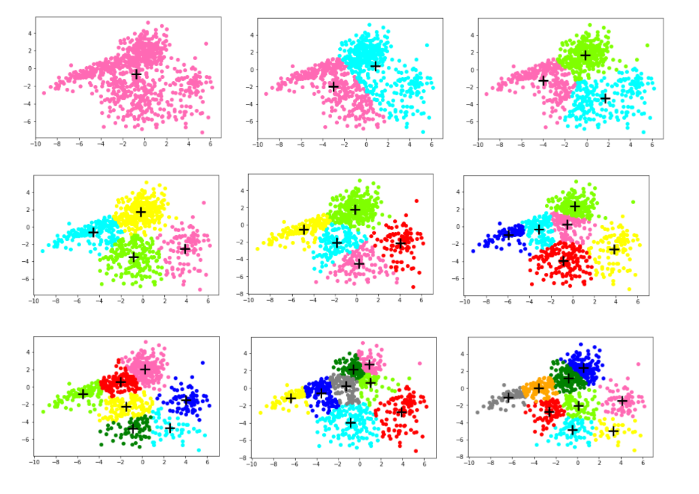
7、画图
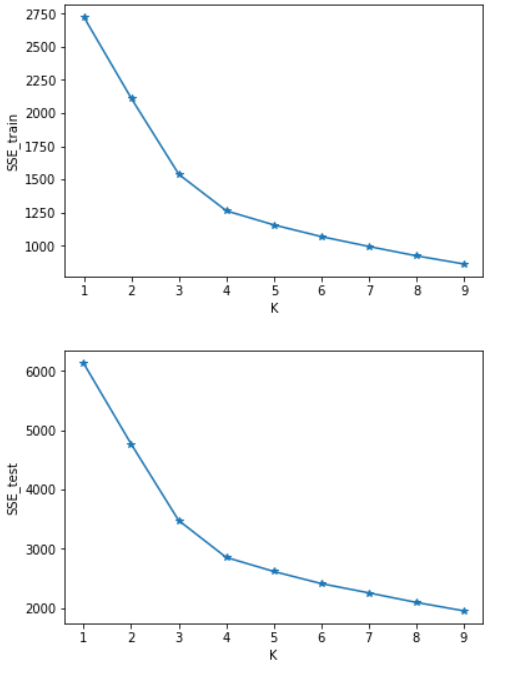
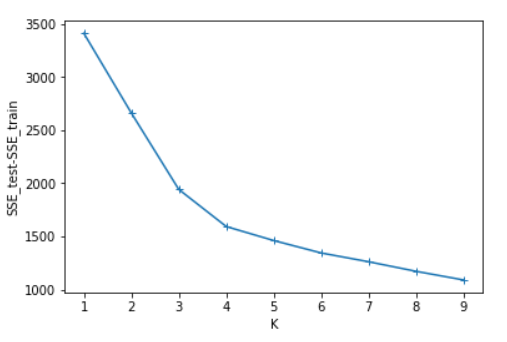
SSE=[] #计算测试集与训练集SSE的差值
for i in range(len(SSE_test)):
SSE.append(SSE_test[i]-SSE_train[i]) x=[1,2,3,4,5,6,7,8,9]
plt.figure()
plt.plot(x,SSE_train,marker='*')
plt.xlabel("K")
plt.ylabel("SSE_train")
plt.show() #画出SSE_train的图 plt.figure()
plt.plot(x,SSE_test,marker='*')
plt.xlabel("K")
plt.ylabel("SSE_test")
plt.show() #画出SSE_test的图 plt.figure()
plt.plot(x,SSE,marker='+')
plt.xlabel("K")
plt.ylabel("SSE_test-SSE_train")
plt.show() #画出SSE_test-SSE_train的图
四、实验结果分析
可以看出SSE随着K的增长而减小,测试集和训练集的图形趋势几乎一致,在相同的K值下,测试集的SSE大于训练集的SSE。于是我对于在相同的K值下的SSE_test和SSE_train做了减法(上图3),可知K=4时数据得出结果最好。这里我主要使用肘部原则来判断。本篇并未实现轮廓系数,由于博主是python小白,故此次代码参考了一部分CSDN的博客:https://blog.csdn.net/qq_37509235/article/details/82925781
k-means聚类分析 python 代码实现(不使用现成聚类库)的更多相关文章
- kd树 求k近邻 python 代码
之前两篇随笔介绍了kd树的原理,并用python实现了kd树的构建和搜索,具体可以参考 kd树的原理 python kd树 搜索 代码 kd树常与knn算法联系在一起,knn算法通常要搜索k近邻, ...
- Python 代码风格
1 原则 在开始讨论Python社区所采用的具体标准或是由其他人推荐的建议之前,考虑一些总体原则非常重要. 请记住可读性标准的目标是提升可读性.这些规则存在的目的就是为了帮助人读写代码,而不是相反. ...
- [转] Python 代码性能优化技巧
选择了脚本语言就要忍受其速度,这句话在某种程度上说明了 python 作为脚本的一个不足之处,那就是执行效率和性能不够理想,特别是在 performance 较差的机器上,因此有必要进行一定的代码优化 ...
- Python代码性能优化技巧
摘要:代码优化能够让程序运行更快,可以提高程序的执行效率等,对于一名软件开发人员来说,如何优化代码,从哪里入手进行优化?这些都是他们十分关心的问题.本文着重讲了如何优化Python代码,看完一定会让你 ...
- Python 代码性能优化技巧(转)
原文:Python 代码性能优化技巧 Python 代码优化常见技巧 代码优化能够让程序运行更快,它是在不改变程序运行结果的情况下使得程序的运行效率更高,根据 80/20 原则,实现程序的重构.优化. ...
- Python 代码性能优化技巧
选择了脚本语言就要忍受其速度,这句话在某种程度上说明了 python 作为脚本的一个不足之处,那就是执行效率和性能不够理想,特别是在 performance 较差的机器上,因此有必要进行一定的代码优化 ...
- 数据关联分析 association analysis (Aprior算法,python代码)
1基本概念 购物篮事务(market basket transaction),如下表,表中每一行对应一个事务,包含唯一标识TID,和购买的商品集合.本文介绍一种成为关联分析(association a ...
- 一起来写2048(160行python代码)
前言: Life is short ,you need python. --Bruce Eckel 我与2048的缘,不是缘于一个玩家,而是一次,一次,重新的ACM比赛.四月份校赛初赛,第一次碰到20 ...
- 一起写2048(160行python代码)
前言: Life is short ,you need python. --Bruce Eckel 我与2048的缘,不是缘于一个玩家.而是一次,一次,重新的ACM比赛.四月份校赛初赛,第一次碰到20 ...
随机推荐
- 一文带你深入了解 Lambda 表达式和方法引用
前言 尽管目前很多公司已经使用 Java8 作为项目开发语言,但是仍然有一部分开发者只是将其设置到 pom 文件中,并未真正开始使用.而项目中如果有8新特性的写法,例如λ表达式.也只是 Idea Al ...
- CSS的基础使用
一,css是什么? CSS全称为“层叠样式表” ,与HTML相辅相成,实现网页的排版布局与样式美化 二,CSS使用方式 1.行内样式/内联样式(单一页面中使用) 借助于style标签属性,为当前的标签 ...
- 译文:在GraalVM中部署运行Spring Boot应用
GraalVM是一种高性能的多语言虚拟机,用于运行以JavaScript等基于LLVM的各种语言编写的应用程序.对于Java应用也可作为通常JVM的替代,它更具有性能优势.GraalVM带来的一个有趣 ...
- 如何应对Kubernetes的安全挑战?
导读:Kubernetes的广泛使用证明了企业的信念,即他们不仅具有处理现代应用程序开发和现代化计划的复杂性的能力,而且具有大规模处理能力. 根据CNCF对各种规模的公司中1340位技术专家的最新调查 ...
- 关于C语言的位运算符
早期cpu架构在运行位运算时 略微领先 + - 运算 大幅领先 * / % 运算 '&' 运算符 总结 两个二进制中对应的位置都为 1 结果的对应二进制为 1 '&'运算符可以用到奇偶 ...
- Java ThreadLocal解析
简介 ThreadLocal 类似局部变量,解决了单个线程维护自己线程内的变量值(存.取.删),让线程之间的数据进行隔离.(InheritableThreadLocal 特例) 这里涉及三个类,Thr ...
- C# -- WebClient自动获取web页面编码并转换
C# -- WebClient自动获取web页面编码并转换 抽个时间,写篇小文章,最近有个朋友,用vb开发一个工具,遇到WebClient获取的内容出现乱码,可惜对vb不是很熟悉,看了几分钟vb的语法 ...
- mfw
0x01 可能为git泄露 git泄露 githack下载源码 index.php <?php if (isset($_GET['page'])) { $page = $_GET['page'] ...
- 大技霸教你远程执行Linux脚本和命令
如果现在需要在 Linux 服务器上执行一系列命令(比如搭建 LNMP 环境)我应该会第一时间想到想办法写个 Shell 脚本,然后扔上去执行以下看看结果. 然而一贯懒惰的我并不想这么去执行 Shel ...
- EOS基础全家桶(十二)智能合约IDE-VSCode
简介 上一篇我们介绍了EOS的专用IDE工具EOS Studio,该工具的优势是简单,易上手,但是灵活性低,且对系统资源开销大,依赖多,容易出现功能异常.那么我们开发人员最容易使用的,可能还是深度定制 ...