《机器学习_02_线性模型_Logistic回归》
import numpy as np
import os
os.chdir('../')
from ml_models import utils
import matplotlib.pyplot as plt
%matplotlib inline
一.简介
逻辑回归(LogisticRegression)简单来看就是在线性回归模型外面再套了一个\(Sigmoid\)函数:
\]
它的函数形状如下:
t=np.arange(-8,8,0.5)
d_t=1/(1+np.exp(-t))
plt.plot(t,d_t)
[<matplotlib.lines.Line2D at 0x233d3c47a58>]
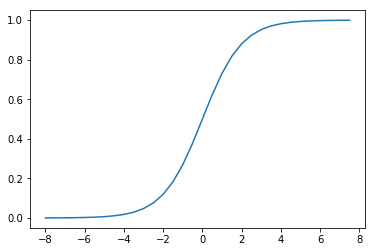
而将\(t\)替换为线性回归模型\(w^Tx^*\)(这里\(x^*=[x^T,1]^T\))即可得到逻辑回归模型:
\]
我们可以发现:\(Sigmoid\)函数决定了模型的输出在\((0,1)\)区间,所以逻辑回归模型可以用作区间在\((0,1)\)的回归任务,也可以用作\(\{0,1\}\)的二分类任务;同样,由于模型的输出在\((0,1)\)区间,所以逻辑回归模型的输出也可以看作这样的“概率”模型:
P(y=0\mid x)=1-f(x)
\]
所以,逻辑回归的学习目标可以通过极大似然估计求解:\(\prod_{j=1}^n f(x_j)^{y_j}(1-f(x_j))^{(1-y_j)}\),即使得观测到的当前所有样本的所属类别概率尽可能大;通过对该函数取负对数,即可得到交叉熵损失函数:
\]
这里\(n\)表示样本量,\(x_j\in R^m\),\(m\)表示特征量,\(y_j\in \{0,1\}\),接下来的与之前推导一样,通过梯度下降求解\(w\)的更新公式即可:
\]
所以\(w\)的更新公式:
\]
二.代码实现
同LinearRegression类似,这里也将\(L1,L2\)的正则化功能加入
class LogisticRegression(object):
def __init__(self, fit_intercept=True, solver='sgd', if_standard=True, l1_ratio=None, l2_ratio=None, epochs=10,
eta=None, batch_size=16):
self.w = None
self.fit_intercept = fit_intercept
self.solver = solver
self.if_standard = if_standard
if if_standard:
self.feature_mean = None
self.feature_std = None
self.epochs = epochs
self.eta = eta
self.batch_size = batch_size
self.l1_ratio = l1_ratio
self.l2_ratio = l2_ratio
# 注册sign函数
self.sign_func = np.vectorize(utils.sign)
# 记录losses
self.losses = []
def init_params(self, n_features):
"""
初始化参数
:return:
"""
self.w = np.random.random(size=(n_features, 1))
def _fit_closed_form_solution(self, x, y):
"""
直接求闭式解
:param x:
:param y:
:return:
"""
self._fit_sgd(x, y)
def _fit_sgd(self, x, y):
"""
随机梯度下降求解
:param x:
:param y:
:return:
"""
x_y = np.c_[x, y]
count = 0
for _ in range(self.epochs):
np.random.shuffle(x_y)
for index in range(x_y.shape[0] // self.batch_size):
count += 1
batch_x_y = x_y[self.batch_size * index:self.batch_size * (index + 1)]
batch_x = batch_x_y[:, :-1]
batch_y = batch_x_y[:, -1:]
dw = -1 * (batch_y - utils.sigmoid(batch_x.dot(self.w))).T.dot(batch_x) / self.batch_size
dw = dw.T
# 添加l1和l2的部分
dw_reg = np.zeros(shape=(x.shape[1] - 1, 1))
if self.l1_ratio is not None:
dw_reg += self.l1_ratio * self.sign_func(self.w[:-1]) / self.batch_size
if self.l2_ratio is not None:
dw_reg += 2 * self.l2_ratio * self.w[:-1] / self.batch_size
dw_reg = np.concatenate([dw_reg, np.asarray([[0]])], axis=0)
dw += dw_reg
self.w = self.w - self.eta * dw
# 计算losses
cost = -1 * np.sum(
np.multiply(y, np.log(utils.sigmoid(x.dot(self.w)))) + np.multiply(1 - y, np.log(
1 - utils.sigmoid(x.dot(self.w)))))
self.losses.append(cost)
def fit(self, x, y):
"""
:param x: ndarray格式数据: m x n
:param y: ndarray格式数据: m x 1
:return:
"""
y = y.reshape(x.shape[0], 1)
# 是否归一化feature
if self.if_standard:
self.feature_mean = np.mean(x, axis=0)
self.feature_std = np.std(x, axis=0) + 1e-8
x = (x - self.feature_mean) / self.feature_std
# 是否训练bias
if self.fit_intercept:
x = np.c_[x, np.ones_like(y)]
# 初始化参数
self.init_params(x.shape[1])
# 更新eta
if self.eta is None:
self.eta = self.batch_size / np.sqrt(x.shape[0])
if self.solver == 'closed_form':
self._fit_closed_form_solution(x, y)
elif self.solver == 'sgd':
self._fit_sgd(x, y)
def get_params(self):
"""
输出原始的系数
:return: w,b
"""
if self.fit_intercept:
w = self.w[:-1]
b = self.w[-1]
else:
w = self.w
b = 0
if self.if_standard:
w = w / self.feature_std.reshape(-1, 1)
b = b - w.T.dot(self.feature_mean.reshape(-1, 1))
return w.reshape(-1), b
def predict_proba(self, x):
"""
预测为y=1的概率
:param x:ndarray格式数据: m x n
:return: m x 1
"""
if self.if_standard:
x = (x - self.feature_mean) / self.feature_std
if self.fit_intercept:
x = np.c_[x, np.ones(x.shape[0])]
return utils.sigmoid(x.dot(self.w))
def predict(self, x):
"""
预测类别,默认大于0.5的为1,小于0.5的为0
:param x:
:return:
"""
proba = self.predict_proba(x)
return (proba > 0.5).astype(int)
def plot_decision_boundary(self, x, y):
"""
绘制前两个维度的决策边界
:param x:
:param y:
:return:
"""
y = y.reshape(-1)
weights, bias = self.get_params()
w1 = weights[0]
w2 = weights[1]
bias = bias[0][0]
x1 = np.arange(np.min(x), np.max(x), 0.1)
x2 = -w1 / w2 * x1 - bias / w2
plt.scatter(x[:, 0], x[:, 1], c=y, s=50)
plt.plot(x1, x2, 'r')
plt.show()
def plot_losses(self):
plt.plot(range(0, len(self.losses)), self.losses)
plt.show()
三.校验
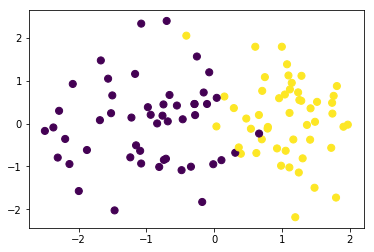
我们构造一批伪分类数据并可视化
from sklearn.datasets import make_classification
data,target=make_classification(n_samples=100, n_features=2,n_classes=2,n_informative=1,n_redundant=0,n_repeated=0,n_clusters_per_class=1)
data.shape,target.shape
((100, 2), (100,))
plt.scatter(data[:, 0], data[:, 1], c=target,s=50)
<matplotlib.collections.PathCollection at 0x233d4c86748>
训练模型
lr = LogisticRegression(l1_ratio=0.01,l2_ratio=0.01)
lr.fit(data, target)
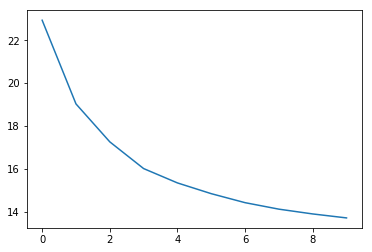
查看loss值变化
交叉熵损失
lr.plot_losses()
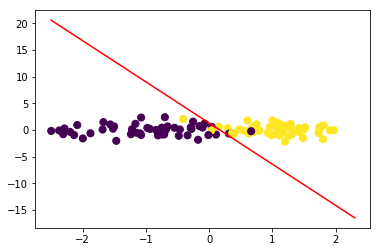
绘制决策边界:
令\(w_1x_1+w_2x_2+b=0\),可得\(x_2=-\frac{w_1}{w_2}x_1-\frac{b}{w_2}\)
lr.plot_decision_boundary(data,target)
#计算F1
from sklearn.metrics import f1_score
f1_score(target,lr.predict(data))
0.96
与sklearn对比
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(data, target)
D:\app\Anaconda3\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2',
random_state=None, solver='warn', tol=0.0001, verbose=0,
warm_start=False)
w1=lr.coef_[0][0]
w2=lr.coef_[0][1]
bias=lr.intercept_[0]
w1,w2,bias
(3.119650945418208, 0.38515595805512637, -0.478776183999758)
x1=np.arange(np.min(data),np.max(data),0.1)
x2=-w1/w2*x1-bias/w2
plt.scatter(data[:, 0], data[:, 1], c=target,s=50)
plt.plot(x1,x2,'r')
[<matplotlib.lines.Line2D at 0x233d5f84cf8>]
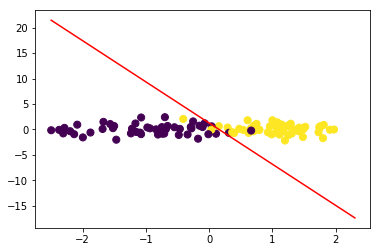
#计算F1
f1_score(target,lr.predict(data))
0.96
四.问题讨论:损失函数为何不用mse?
上面我们基本完成了二分类LogisticRegression代码的封装工作,并将其放到liner_model模块方便后续使用,接下来我们讨论一下模型中损失函数选择的问题;在前面线性回归模型中我们使用了mse作为损失函数,并取得了不错的效果,而逻辑回归中使用的确是交叉熵损失函数;这是因为如果使用mse作为损失函数,梯度下降将会比较困难,在\(f(x^i)\)与\(y^i\)相差较大或者较小时梯度值都会很小,下面推导一下:
我们令:
\]
则有:
\]
我们简单看两个极端的情况:
(1)\(y^i=0,f(x^i)=1\)时,\(\frac{\partial L}{\partial w}=0\);
(2)\(y^i=1,f(x^i)=0\)时,\(\frac{\partial L}{\partial w}=0\)
接下来,我们绘图对比一下两者梯度变化的情况,假设在\(y=1,x\in(-10,10),w=1,b=0\)的情况下
y=1
x0=np.arange(-10,10,0.5)
#交叉熵
x1=np.multiply(utils.sigmoid(x0)-y,x0)
#mse
x2=np.multiply(utils.sigmoid(x0)-y,utils.sigmoid(x0))
x2=np.multiply(x2,1-utils.sigmoid(x0))
x2=np.multiply(x2,x0)
plt.plot(x0,x1)
plt.plot(x0,x2)
[<matplotlib.lines.Line2D at 0x233d6046048>]
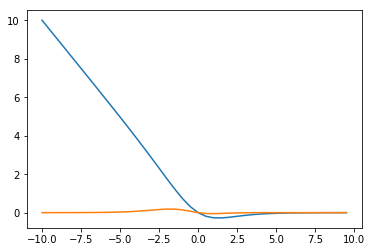
可见在错分的那一部分(x<0),mse的梯度值基本停留在0附近,而交叉熵会让越“错”情况具有越大的梯度值
《机器学习_02_线性模型_Logistic回归》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- 数值分析实验之曲线最小二乘拟合含有噪声扰动(python实现)
一.实验目的 掌握最小二乘法拟合离散数据,多项式函数形式拟合曲线以及可以其他可以通过变量变换转化为多项式的拟合曲线目前待实现功能: 1. 最小二乘法的基本实现. 2. 用不同数据量,不同参数,不同的多 ...
- TensorFlow keras中一些著名的神经网络
- 【Inno Setup】Pascal 脚本 ---- 事件函数
转载 事件函数 Inno Setup支持以下函数和过程. 1. [安装初始化]该函数在安装程序初始化时调用,返回False 将中断安装,True则继续安装,测试代码如下: function Initi ...
- spring boot 使用maven和fat jar/war运行应用程序的对比
文章目录 简介 Spring Boot Maven Plugin 使用Maven命令来运行应用程序 作为fat jar/war包运行应用程序 详解War文件 详解jar文件 如何选择 使用maven和 ...
- Scala教程之:函数式的Scala
文章目录 高阶函数 强制转换方法为函数 方法嵌套 多参数列表 样例类 比较 拷贝 模式匹配 密封类 单例对象 伴生对象 正则表达式模式 For表达式 Scala是一门函数式语言,接下来我们会讲一下几个 ...
- Linux系统介绍与环境搭建准备
1 什么是操作系统? 操作系统,Operating System,简称OS,是计算机系统中必不可少的基础软件,它是应用程序运行以及用户操作必备的基础环境支撑,是计算机系统的核心. 操作系统的作用是 ...
- java switch用法
为什么80%的码农都做不了架构师?>>> Java 7中,switch的参数可以是String类型了,这对我们来说是一个很方便的改进.到目前为止switch支持这样几种数据类型: ...
- CultureInfo 类中需要的【区域性名称】查询
2019独角兽企业重金招聘Python工程师标准>>> 提供有关特定区域性的信息(对于非托管代码开发,则称为"区域设置"). 这些信息包括区域性的名称.书写系统. ...
- CodeForces - 1245F Daniel and Spring Cleaning (数位DP)
While doing some spring cleaning, Daniel found an old calculator that he loves so much. However, it ...
- 图论--最短路--Floyd(含路径输出)
#include<bits/stdc++.h> using namespace std; #define INF 0x3f3f3f3f #define maxn 1005 int D[ma ...