Python中作Q-Q图(quantile-quantile Plot)
Q-Q图主要可以用来回答这些问题:
- 两组数据是否来自同一分布
PS:当然也可以用KS检验,利用python中scipy.stats.ks_2samp函数可以获得差值KS statistic和P值从而实现判断。 - 两组数据的尺度范围是否一致
- 两组数据是否有类似的分布形状
前面两个问题可以用样本数据集在Q-Q图上的点与参考线的距离判断;而后者则是用点的拟合线的斜率判断。
用Q-Q图来分析分布的好处都有啥?(谁说对了就给他)
- 两组数据集的大小可以不同
- 可以回答上面的后两个问题,这是更深入的数据分布层面的信息。
那么,Q-Q图要怎么画呢?
将其中一组数据作为参考,另一组数据作为样本。样本数据每个值在样本数据集中的百分位数(percentile)作为其在Q-Q图上的横坐标值,而该值放到参考数据集中时的百分位数作为其在Q-Q图上的纵坐标。一般我们会在Q-Q图上做一条45度的参考线。如果两组数据来自同一分布,那么样本数据集的点应该都落在参考线附近;反之如果距离越远,这说明这两组数据很可能来自不同的分布。
python中利用scipy.stats.percentileofscore函数可以轻松计算上诉所需的百分位数;而利用numpy.polyfit函数和sklearn.linear_model.LinearRegression类可以用来拟合样本点的回归曲线
from scipy.stats import percentileofscore
from sklearn.linear_model import LinearRegression
import pandas as pd
import matplotlib.pyplot as plt
# df_samp, df_clu are two dataframes with input data set
ref = np.asarray(df_clu)
samp = np.asarray(df_samp)
ref_id = df_clu.columns
samp_id = df_samp.columns
# theoretical quantiles
samp_pct_x = np.asarray([percentileofscore(ref, x) for x in samp])
# sample quantiles
samp_pct_y = np.asarray([percentileofscore(samp, x) for x in samp])
# estimated linear regression model
p = np.polyfit(samp_pct_x, samp_pct_y, 1)
regr = LinearRegression()
model_x = samp_pct_x.reshape(len(samp_pct_x), 1)
model_y = samp_pct_y.reshape(len(samp_pct_y), 1)
regr.fit(model_x, model_y)
r2 = regr.score(model_x, model_y)
# get fit regression line
if p[1] > 0:
p_function = "y= %s x + %s, r-square = %s" %(str(p[0]), str(p[1]), str(r2))
elif p[1] < 0:
p_function = "y= %s x - %s, r-square = %s" %(str(p[0]), str(-p[1]), str(r2))
else:
p_function = "y= %s x, r-square = %s" %(str(p[0]), str(r2))
print "The fitted linear regression model in Q-Q plot using data from enterprises %s and cluster %s is %s" %(str(samp_id), str(ref_id), p_function)
# plot q-q plot
x_ticks = np.arange(0, 100, 20)
y_ticks = np.arange(0, 100, 20)
plt.scatter(x=samp_pct_x, y=samp_pct_y, color='blue')
plt.xlim((0, 100))
plt.ylim((0, 100))
# add fit regression line
plt.plot(samp_pct_x, regr.predict(model_x), color='red', linewidth=2)
# add 45-degree reference line
plt.plot([0, 100], [0, 100], linewidth=2)
plt.text(10, 70, p_function)
plt.xticks(x_ticks, x_ticks)
plt.yticks(y_ticks, y_ticks)
plt.xlabel('cluster quantiles - id: %s' %str(ref_id))
plt.ylabel('sample quantiles - id: %s' %str(samp_id))
plt.title('%s VS %s Q-Q plot' %(str(ref_id), str(samp_id)))
plt.show()
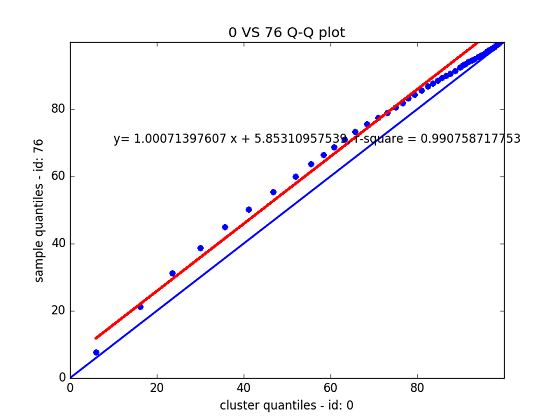
效果如上图所示,在本例中所用的样本数据在左下稀疏,在右上集中,且整体往上偏移,说明其分布应该与参考数据是不一样的(分布形状不同),用KS检验得到ks-statistic: 0.171464; p_value: 0.000000也验证了这一点;但是其斜率在约为1,且整体上偏的幅度不大,说明这两组数据的尺度是接近的。
PS: 这里的方法适用于不知道数据分布的情况。如果想检验数据是否符合某种已知的分布,例如正态分布请出门左转用scipy.stats.probplot函数。
参考:
Python中作Q-Q图(quantile-quantile Plot)的更多相关文章
- python中matplotlib画折线图实例(坐标轴数字、字符串混搭及标题中文显示)
最近在用python中的matplotlib画折线图,遇到了坐标轴 "数字+刻度" 混合显示.标题中文显示.批量处理等诸多问题.通过学习解决了,来记录下.如有错误或不足之处,望请指 ...
- Python中的 __name__有什么作用?最详细解读
案例说明: Python中的模块(.py文件)在创建之初会自动加载一些内建变量,__name__就是其中之一.Python模块中通常会定义很多变量和函数,这些变量和函数相当于模块中的一个功能,模块被导 ...
- Neo4j:图数据库GraphDB(四)Python中的操作
本文总结下Python中如何操作Neo4j数据库,用到py2neo包,Pip install 一下. 1 连接neo4j数据库:跟其它数据库一样,操作前必须输入用户名和密码及地址连接一下. from ...
- 天啦噜!仅仅5张图,彻底搞懂Python中的深浅拷贝
Python中的深浅拷贝 在讲深浅拷贝之前,我们先重温一下 is 和==的区别. 在判断对象是否相等比较的时候我们可以用is 和 == is:比较两个对象的引用是否相同,即 它们的id 是否一样 == ...
- 深入Python中的正则表达式
正则表达式应用的场景也非常多.常见的比如:搜索引擎的搜索.爬虫结果的匹配.文本数据的提取等等都会用到,所以掌握甚至精通正则表达式是一个硬性技能,非常必要. 正则表达式 正则表达式是一个特殊的字符序列, ...
- Python爬虫学习(4): python中re模块中的向后引用以及零宽断言
使用小括号的时候,还有很多特定用途的语法.下面列出了最常用的一些: 表4.常用分组语法 分类 代码/语法 说明 捕获 (exp) 匹配exp,并捕获文本到自动命名的组里 (?<name>e ...
- 精通 Oracle+Python,第 9 部分:Jython 和 IronPython — 在 Python 中使用 JDBC 和 ODP.NET
成功的编程语言总是会成为顶级开发平台.对于 Python 和世界上的两个顶级编程环境 Java 和 Microsoft .NET 来说的确如此. 虽然人们因为 Python 能够快速组装不同的软件组件 ...
- 在python中的使用Libsvm
http://blog.csdn.net/pipisorry/article/details/38964135 LIBSVM是台湾大学林智仁(LinChih-Jen)教授等开发设计的一个简单.易于使用 ...
- 互相关(cross-correlation)及其在Python中的实现
互相关(cross-correlation)及其在Python中的实现 在这里我想探讨一下“互相关”中的一些概念.正如卷积有线性卷积(linear convolution)和循环卷积(circular ...
随机推荐
- understanding checkpoint_completion_target
Starting new blog series – explanation of various configuration parameters. I will of course follow ...
- Sklearn库例子2:分类——线性回归分类(Line Regression )例子
线性回归:通过拟合线性模型的回归系数W =(w_1,…,w_p)来减少数据中观察到的结果和实际结果之间的残差平方和,并通过线性逼近进行预测. 从数学上讲,它解决了下面这个形式的问题: Lin ...
- iframe中子页面通过js计算高度(使得页面不会显示不全)
使用过iframe的人,都知道,它是一个模版,里面有一个iframe,而iframe当中,是可以嵌套多个页面的.(比较常见的问题,就是iframe页面中,经常会出现内容显示不全的时候). 谨记,通过j ...
- 部署 mozilla-BrowserQuest
1,到GitHub下载代码 https://github.com/mozilla/BrowserQuest 2,安装Node.Js 下载地址 http://nodejs.org/ 直接下载安装版就可 ...
- CSS3 必须要知道的10 个顶级命令
来源:http://www.cnblogs.com/damonlan/archive/2012/04/23/2465569.html 作者:浪迹天涯 1.边框圆角(Border Radiuas) 这个 ...
- OpenJudge计算概论-字符串最大跨距
/*====================================================================== 字符串最大跨距 总时间限制: 1000ms 内存限制: ...
- android虚拟机(ROOT)权限
自己找的一个比较好用的pc端安卓模拟器,蓝手指总所周知吧,这个是较高版本但不是最新的一个版本,关键是自带root功能,对于破解安卓存档类游戏还是有用的.安卓版本4.4.2 BlueStacks 0.9 ...
- JdbcUtils
JdbcUtils 项目结构 db.properties driverClass=com.mysql.jdbc.Driver url=jdbc:mysql:///myTest username=r ...
- 【extjs】 extjs5 Ext.grid.Panel 搜索示例
先看效果图: 页面js: <script type="text/javascript"> /** * 日志类型 store * */ var logTypeStore ...
- C#Winfrom系统打印机调用/设置默认打印机
实现如下效果: 实现方式如下: using System;using System.Drawing.Printing;using System.Runtime.InteropServices;usin ...