2.数码相框-编码(ASCII/GB2312/Unicode)介绍
转载:https://www.cnblogs.com/lifexy/p/8485634.html
本章主要内容如下:
- 1)熟悉ASCII/GB2312/Unicode编码
- 2)写应用程序,使LCD显示汉字和字符
大家都知道,数据传输的是二进制,而字符和汉字却有各种各样的,所以便通过二进制将字符和汉字编成一个字符集(charset).
1.而字符集(charset)又经历3个阶段
ASCII码
最早的计算机采用ASCII码,一个字节便包括了英文数字这些符号
GB2312编码
由于不支持中文,那时候的常用汉字就有6763个,所以中国人发明了GB2312(GB国标),汉字为2个字节,与ascll码兼容,后来又继续扩展汉字,所以又有了GBK编码.
GB2312编码是将字符进行一个分区处理,共有94个区,每个区有94个位,所以区位码范围为0000~9393
汉字分为了一级汉字(常用)和二级汉字(不常用).
其中GB2312分区表如下图所示:
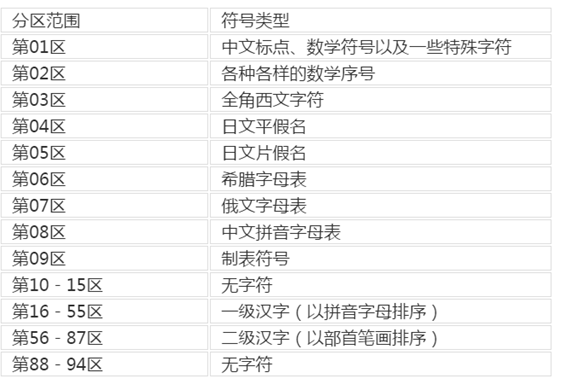
比如“啊”,位于第16区第1位,也就是1500.
然后分别在区和位上加0xA1,便转换为了GB2312编码(编码从0xA1A1开始是为了兼容英文字符,)
所以“啊”的GB2312编码为: 0xB0A1
15(区)+0xA1=0xB0
00(位)+0xA1=0xA1

这种编码方式仅仅在中国行的通,若去浏览繁体字或日文时,便会出现乱码,因为繁体字使用的是Big5编码,日文则需要安装日本的Shift_JIS 编码才行.
在不同的国家的编码标准都不同,所以在PC里,使用ANSI编码来代表它们,比如中文PC里,ANSI编码代表GBK编码.
Unicode编码(统一世界所有符号)
包括中、日、韩、英文等字符,格式有utf-32、utf-16、utf-8
在PC,Unicode一般代表utf-16,而utf-8是单独列出来的,
utf-32
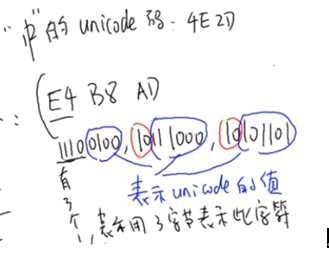
指每个字符都采用4个字节(32位),缺点在于浪费空间,比如:a=0x0000 0061,啊=0x0000554A.
utf-16(错一个字节,则整个乱码)
每个字符的长度为2字节或4字节,常用的都是2字节(包括汉字等). 比如: a=0x0061,啊=0x554A.
utf-8(容错能力高)
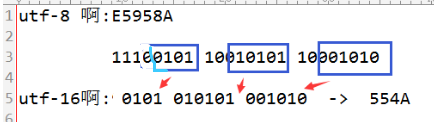
指每个字符的长度为1~4个字节,越常用的字符,字节越短,比如:a=0x61,啊=0xE5958A
可以通过utf-16转换过来,高4位表示有多少个字节,然后剩下的每个字节的高2位都为10(表示只有一个字节),剩下的值加起来就是utf-16编码,如下图所示:
如果是unicode转utf-8,则对应代码为:

int UnicodeToUtf8( unsigned short* src, unsigned short* putf8)
{
int len = 0;
while (*src)
{
if (*src < 0x80) //one byte
{
putf8[len++] = *src;
}
else if (*src < 0x800) //two byte
{
putf8[len++] = 0xC0 | (*src >> 6);
putf8[len++] = 0x80 | ((*src) & 0x3F);
}
else
{
putf8[len++] = 0xE0 | (*src >> 12); //获取src高4位
putf8[len++] = 0x80 | ((*src >> 6) & 0x3F); //获取src 第6位,长度为3f(6位)
putf8[len++] = 0x80 | (*src & 0x3F); //获取src低6位
}
src++;
}
putf8[len] = 0;
return len;
} int main()
{
unsigned short Unicode[2]={0x4e2d}; //中的unicode码 unsigned short utf[4]={0,0,0,0}; UnicodeToUtf8(Unicode,utf); for(int i=0;i<4;i++)
printf(" %x ",utf[i]);
return 0; }
一般一个文件的开头会有标志,通过十六进制编辑文件,便可以看到
EF BB BF 表示utf-8
FE FF 表示utf-16大端(大开头,比如a=00 61)
FF FE 表示utf-16小端(小开头,比如a=61 00)
没有前缀 表示ANSI格式
2.所以文件格式不同,执行的结果也不同
2.1我们下面代码为例:
#include <stdio.h>
int main(int argc,char **argv)
{
int i=0;
unsigned char s[]="abc中"; while(s[i])
{
printf("%02x ",s[i]);
i++;
}
printf("\n");
return 0;
}
然后在PC上,另存为ANSI.c和UTF-8.c,编码分别选择ANSI(GBK编码)和UTF-8
2.2然后拖到linux里编译运行:
gcc -o ANSI ANSI.c
gcc -o UTF-8 UTF-8.c

3.如何解决文件格式不同,编码也不同的问题?
我们可以指定字符集(charset), 强制使它以什么编码格式解析
man gcc //查看gcc使用手册
/charset //搜索charset相关字
找到:
-finput-charset=charset //表示源文件的编码方式, 默认以UTF-8来解析
-fexec-charset=charset //表示可执行程序里的字时候以什么编码方式来表示,默认是UTF-8
3.1指定字符集(charset)
gcc -finput-charset=GBK -fexec-charset=UTF-8 -o utf-8_2 ANSI.c

如上图所示,通过参数,告诉gcc该文件是GBK编码,需要转换为UTF-8编码后,再编译,便解决了文件格式问题.
2.数码相框-编码(ASCII/GB2312/Unicode)介绍的更多相关文章
- 2.数码相框-编码(ASCII/GB2312/Unicode)介绍,并使LCD显示汉字字符(2)
在上章-学习了数码相框的框架分析(1)了 本章主要内容如下: 1)熟悉ASCII/GB2312/Unicode编码 2)写应用程序,使LCD显示汉字和字符 大家都知道,数据传输的是二进制,而字符和汉字 ...
- 字节的高低位知识,Ascii,GB2312,UNICODE等编码的关系与来历
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关状态是好的,于是他们把这称为"字节". 再后来,他们又做了一些可以处理 ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 字符编码(ASCII,Unicode和UTF-8) 和 大小端(zz)
本文包括2部分内容:“ASCII,Unicode和UTF-8” 和 “Big Endian和Little Endian”. 第1部分 ASCII,Unicode和UTF-8 介绍 1. ASCII码 ...
- 编码 ASCII, GBK, Unicode+utf-8
0. 1.参考 网页编码就是那点事 阮一峰 字符编码笔记:ASCII,Unicode 和 UTF-8 2.总结 美国 ASCII 码 发音: /ˈæski/ :128个字符,只占用了一个字节的后面7位 ...
- 字符编码 ASCII、Unicode和UTF-8的关系
摘抄自廖雪峰 教程 字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机 ...
- Java 字符编码 ASCII、Unicode、UTF-8、代码点和代码单元
1 ASCII码 统一规定英语字符与二进制位之间的关系.ASCII码一共规定了128个字符的编码.例如,空格“SPACE”是32(二进制00100000),大写字母A是65(二进制01000001). ...
- 转载:从程序员的角度看ASCII, GB2312, UNICODE, UTF-8
以下内容转自博客:http://blog.chinaunix.net/uid-22670933-id-1771613.html. 一.字符编码是怎么回事 0. 概念 字节是计算机的最基本存储单位,一个 ...
- 字符编码ascii、unicode、utf-‐8、gbk 的关系
ASIIC码: 计算机是美国人发明和最早使用的,他们为了解决计算机处理字符串的问题,就将数字字母和一些常用的符号做成了一套编码,这个编码就是ASIIC码.ASIIC码包括数字大小写字母和常用符号,一共 ...
随机推荐
- 记录一下我的git连接不上GitHub问题
1.日常操作,提交代码,报错误下: $ git clone git@github.com:hanchao5272/myreflect.git Cloning into 'myreflect'... s ...
- 【ARM-Linux开发】Linux查看设备驱动
驱动操作命令: insmod / modprobe 加载驱动 rmmod 卸载驱动 lsmod 查看系统中所有已经被 ...
- MySQL初始化脚本mysql_install_db使用简介及选项参数
mysql_install_db是一个默认放在.../mysql/scripts的一个初始化脚本. 该脚本可以在任何装有perl的操作系统上被使用,在5.6.8之前的版本,该脚本是一个shell脚本, ...
- python线程信号量semaphore(33)
通过前面对 线程互斥锁lock / 线程事件event / 线程条件变量condition / 线程定时器timer 的讲解,相信你对线程threading模块已经有了一定的了解,同时执行多个线程的 ...
- Asp.Net Core集成Swagger
工作中一个公司会有很多个项目,项目之间的交互经常需要编写 API 来实现,但是编写文档是一件繁琐耗时的工作,并且随着 API 的迭代,每次都需要去更新维护接口文档,很多时候由于忘记或者人员交替的愿意造 ...
- 乐字节Java变量与数据类型之一:Java编程规范,关键字与标识符
大家好,我是乐字节的小乐,这次要给大家带来的是Java变量与数据类型.本文是第一集:Java编程规范,关键字与标识符. 一.编程规范 任何地方的名字都需要见名知意: 代码适当缩进 书写过程成对编程 对 ...
- 通过getAdaptiveExtension生成的动态类
通过getAdaptiveExtension生成的动态类 方便调式使用 请放在根目录下
- 待续:s5p6818移植 uboot 2014.07 移植
前言: 之前半年一直在嵌入式Linux移植中挣扎,不知道该从哪个方面开始入手,也失败了很多次,苦思了很久最终决定先从uboot开始. uboot版本的不同会导致添加板子的时候的配置方法会不一样.由于手 ...
- hdu 1002 prime 模板
Constructing Roads Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Other ...
- 【Transact-SQL】找出不包含字母、不包含汉字的数据
原文:[Transact-SQL]找出不包含字母.不包含汉字的数据 测试的同事,让我帮忙写个sql语句,找出表中xx列不包含汉字的行. 下面的代码就能实现. IF EXISTS(SELECT * FR ...