Prometheus HA详解
Prometheus 横向扩展
当Exporter或者采集信息需要越来越多时就会考虑高可用,高可用优点不会因为集群中某个节点down而导致Prometheus不可用,可以让算力下沉;
缺点是A-Prometheus和B-Prometheus这两个实例会定时去scrape数据,并且存储在各本地,这样导致数据会存储两份;

- 高可用配置
将Prometheus启动两个实例,配置一样只需要暴露的service的端口不同,'Nginx Controller'配置session-affinity的service名称;
Prometheus 联邦
在多个数据中心部署Prometheus需要将多数据中心数据合在一起管理,使用联邦模式非常合适,如果担心数据单点,可以在联邦的基础上再扩展高可用;
优点集中式管理数据,报警,不需要为每个Prometheus实例管理数据,如有些敏感节点报警要求高可以在Prometheus数据节点上加报警信息,可以按功能环境划分启动多个Prometheus采集实例;
缺点数据集中化,网络可能会延时,数据单点等问题;

终级解决方案
Prometheus 是支持远程读写TSDB数据库,请看官方网站支持哪些数据库的读写,因为有些数据只支持写而不支持读,你内网搭建TSDB集群,你所有启动的Prometheus实例都把数据写入到远程数据库,再使用高可用方案支持查询,只支持远程读,这样就可无限扩展采集实例和查询实例,非常的爽,作者没有实践过只是YY中;
- 采集的
Metrics远程写入TSDB
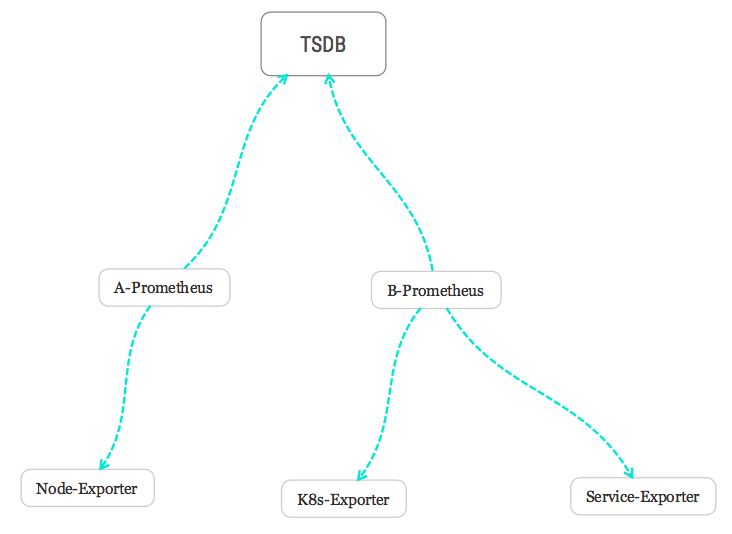
Prometheus远程读TSDB

Prometheus HA详解的更多相关文章
- Prometheus 配置文件详解
Prometheus 配置文件详解 官方文档:https://prometheus.io/docs/prometheus/latest/configuration/configuration/ 指标说 ...
- prometheus学习系列十一: Prometheus exporter详解
exporter详解 前面的系列中,我们在主机上面安装了node_exporter程序,该程序对外暴露一个用于获取当前监控样本数据的http的访问地址, 这个的一个程序成为exporter,Expor ...
- hadoop HA 详解
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- Hadoop2之NameNode HA详解
在Hadoop1中NameNode存在一个单点故障问题,如果NameNode所在的机器发生故障,整个集群就将不可用(Hadoop1中虽然有个SecorndaryNameNode,但是它并不是NameN ...
- HDFS2.0架构以及HA详解
HDFS2.0概述 一背景,Hadoop1.0中HDFS和MapReduce在高可用,扩展性等方面存在问题 HDFS存在问题,1,NameNode单点故障,难以应用于在线场景.2,NameNod ...
- 【转载】VMware vSphere 5 HA详解 1
很久没有动笔写博客了.总算最近的几项工作告一段落,对iOS和Android的折腾也兴趣稍退,该写点技术博客了. 想写一篇关于VMware HA的博客由来已久,曾经做了些功课,查了不少资料,写了点笔记, ...
- Prometheus 介绍详解
Prometheus 介绍 Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统.自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区.为强调开源及独立维护,P ...
- Prometheus Node_exporter 详解
Basic CPU / Mem / Disk Info https://www.cnblogs.com/qianyuliang/p/10479515.html Basic CPU / Mem / Di ...
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
随机推荐
- [Vue]vue中路由重定向redirect
1.重定向的地址不需要接收参数 const routes = [ { path: '/', redirect: '/index'}, { path: '/index', component: inde ...
- VBA变量(七)
变量是一个指定的内存位置,用于保存脚本执行过程中可以更改的值.以下是命名变量的基本规则. 变量名称必须使用一个字母作为第一个字符. 变量名称不能使用空格,句点(.),感叹号(!)或字符@,&, ...
- jQuery异步请求ajax()之complete参数详解
请求完成后回调函数 (请求success 和 error之后均调用).这个回调函数得到2个参数:XMLHTTPRequest) 对象和一个描述请求状态的字符串("success", ...
- node - path路径
1.node命令路径与js文件路径 node命令路径为node命令所执行的目录,js文件路径指的是你要运行的js所在的目录. 如上图所示: server.js路径为E:\zyp: node命令路径我们 ...
- vue拦截
```javascript import Vue from 'vue' import App from './App.vue' import router from './router' import ...
- python数据写入Excel表格
from openpyxl import Workbook def main(): sheet_name = "表名1" row_count = 6 # 行数 info_resul ...
- MVC方式显示数据(手动添加数据)
Model添加类 Customers using System; using System.Collections.Generic; using System.Linq; using System.W ...
- Linux命令——cat、more、less、head、tail
cat 一次显示整个文件 -n:显示行号 -b :和 -n 相似,只不过对于空白行不编号 -s:当遇到有连续两行以上的空白行,就代换为一行的空白行 -E显示换行符 [root@localhost ~] ...
- 一:(1.1)了解MVC之路由重写
Mvc默认路由 //系统的Url路由规则 routes.MapRoute( name: "Default", url: "{controller}/{action}/{i ...
- Linux基本命令-chmod
chmod命令用来变更文件或目录的权限.在UNIX系统家族里,文件或目录权限的控制分别以读取.写入.执行3种一般权限来区分,另有3种特殊权限可供运用.用户可以使用chmod指令去变更文件 ...