Elastic Search中normalization和分词器
为key_words提供更加完整的倒排索引。
如:时态转化(like | liked),单复数转化(man | men),全写简写(china | cn),同义词(small | little)等。
如:china 搜索时,如果条件为cn是否可搜索到。
如:dogs,搜索时,条件为dog是否可搜索到数据。
如果可以使用简写(cn)或者单复数(dog&dogs)搜索到想要的结果,那么称为搜索引擎normalization人性化。
normalization是为了提升召回率的(recall),就是提升搜索能力的。
normalization是配合分词器(analyzer)完成其功能的。
分词器的功能就是处理Document中的field的。就是创建倒排索引过程中用于切分field数据的。
如:I think dogs is human’s best friend.在创建倒排索引的时候,使用分词器实现数据的切分。
上述的语句切分成若干的词条,分别是: think dog human best friend。
常见搜索条件有:think、 human、 best、 friend,很少使用is、a、the、i这些数据作为搜索条件。
1 ES默认提供的常见分词器
要切分的语句:Set the shape to semi-transparent by calling set_trans(5)
standard analyzer - 是ES中的默认分词器。标准分词器,处理英语语法的分词器。
切分后的key_words:set, the, shape, to, semi, transparent, by, calling, set_trans, 5。
这种分词器也是ES中默认的分词器。切分过程中会忽略停止词等(如:the、a、an等)。
会进行单词的大小写转换。过滤连接符(-)或括号等常见符号。
simple analyzer - 简单分词器。切分后的key_words:set, the, shape, to, semi, transparent, by, calling, set, trans。
就是将数据切分成一个个的单词。使用较少,经常会破坏英语语法。
whitespace analyzer - 空白符分词器。切分后的key_words:Set, the, shape, to, semi-transparent, by, calling, set_trans(5)。就是根据空白符号切分数据。如:空格、制表符等。使用较少,经常会破坏英语语法。
language analyzer - 语言分词器,如英语分词器(english)等。
切分后的key_words:set, shape, semi, transpar, call, set_tran, 5。
根据英语语法分词,会忽略停止词、转换大小写、单复数转换、时态转换等,应用分词器分词功能类似standard analyzer。
注意:搜索条件中的key_words也需要经过分词,且搜索条件中的条件数据使用的分词器与对应的字段使用的分词器是统一的。否则会导致搜索结果丢失。搜索条件的分词结果和测试的分词结果完全一致。
ES中提供的所有的英语相关的分词器,对中文的分词都是一字一词。
2 安装中文分词器
2.1 下载&打包IK分词器
使用git下载IK分词器,并使用maven实现打包。
git clone https://github.com/medcl/elasticsearch-analysis-ik.git
git checkout tags/v6.3.0
mvn clean
mvn compile
mvn package
打包后的资源在target/releases目录中,资源为zip压缩包。
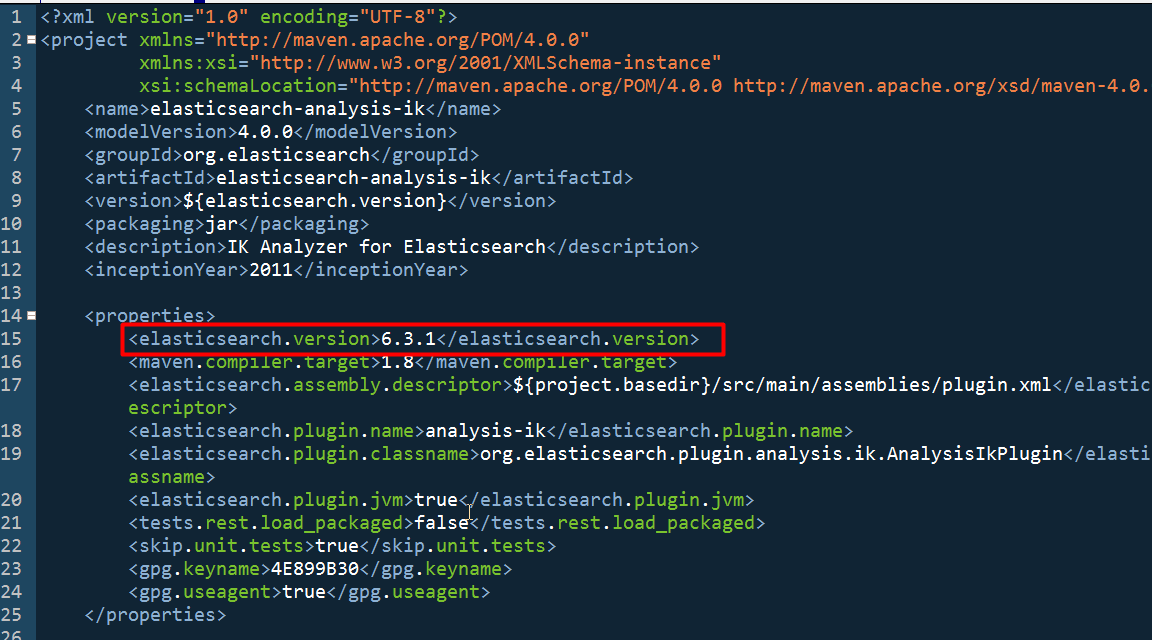
IK也需要去链接ES,ES需要访问IK分词器。 IK在链接ES的时候,是需要使用ES提供的java版客户端api的。IK提供的源码中,是一个maven工程,pom.xml配置文件中依赖的ES客户端jar,使用的是6.3.0 。本地安装的什么版本ES,就修改为对应的ES版本即可。
IK默认提供的pom.xml文件中依赖的是elasticsearch6.3.0的客户端,需要手工修改pom.xml中的依赖。将6.3.0修改为6.3.1。github中提供的IK支持6.x相关版本的ES。
2.2 安装IK分词器
ES是一个开箱即用的工具。插件安装方式也非常简单。
将打包后的zip文件复制,并在ES安装目录的plugins目录中手工创建子目录,目录命名为ik。将zip解压缩到新建目录ik中。重新启动ES即可。
所有的分词器,都是针对词语的,不是语句的。拆分单元是词语,不是语句。
2.3 测试IK分词器
IK分词器提供了两种analyzer,分别是ik_max_word和ik_smart。
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,国,国歌”,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
上述内容引用自github官方数据。
GET _analyze
{
"text" : "中华人民共和国国歌",
"analyzer": "ik_max_word"
} GET _analyze
{
"text" : "中华人民共和国国歌",
"analyzer": "ik_smart"
}
2.4 IK配置文件
IK的打包后,根目录中有配置文件:通常来说不需要关注下述两个配置文件。
plugin-security.policy: 是用于在JRE环境中授权的配置文件,相当于是$JAVA_HOME/jre/lib/security/java.policy。后期使用源代码修改实现热词更新的时候,很可能需要修改JDK中的java.policy文件。
plugin-descriptor.properties: 是ES启动的时候,加载IK插件时,IK插件上下文配置信息解析的配置文件。用于配置IK上下文信息,如:IK所在的ES版本是什么,IK所在的JDK环境版本是什么等。
IK的配置文件在ES安装目录/plugins/ik/config/中。
配置文件有:
main.dic : IK中内置的词典。 main dictionary。记录了IK统计的所有中文单词。一行一次。文件中未记录的单词,IK无法实现有效分词。如:蓝瘦香菇。不建议修改当前文件中的单词。这个是最核心的中文单词库。就好像,很多的网络词不会收集到辞海中一样。
quantifier.dic : IK内置的数据单位词典
suffix.dic :IK内置的后缀词典
surname.dic :IK内置的姓氏词典
stopword.dic :IK内置的英文停用词
preposition.dic :IK内置的中文停用词(介词)
IKAnalyzer.cfg.xml : 用于配置自定义词库的
自定义词库是用户手工提供的特殊词典,类似网络热词,特定业务用词等。
ext_dict - 自定义词库,配置方式为相对于IKAnalyzer.cfg.xml文件所在位置的相对路径寻址方式。相当于是用户自定义的一个main.dic文件。是对main.dic文件的扩展。不是热更新,是固定的扩展。
ext_stopwords - 自定义停用词,配置方式为相对于IKAnalyzer.cfg.xml文件所在位置的相对路径寻址方式。相当于是preposition.dic的扩展。
IK的所有的dic词库文件,必须使用UTF-8字符集。不建议使
用windows自带的文本编辑器编辑。Windows中自带的文本编辑器是使用GBK字符集。IK不识别,是乱码。
2.5 IK热词更新
如果使用本地自定义词库文件的形式定义最新词条,那么想让最新热词词条生效则需要重启ES。这样对系统的效率有很大的影响。
IK支持远程词库加载,可以通过配置或修改IK源代码的方式实现远程词库加载。
IK提供了HTTP协议形式的远程词库加载方式,不推荐使用,毕竟会对效率有一定的影响。
我们这里使用修改IK源代码的形式,从MYSQL数据库中动态加载词库。
具体操作细节下次再整理。
Elastic Search中normalization和分词器的更多相关文章
- Elastic search中使用nested类型的内嵌对象
在大数据的应用环境中,往往使用反范式设计来提高读写性能. 假设我们有个类似简书的系统,系统里有文章,用户也可以对文章进行赞赏.在关系型数据库中,如果按照数据库范式设计,需要两张表:一张文章表和一张赞赏 ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- 如何在Elasticsearch中安装中文分词器(IK+pinyin)
如果直接使用Elasticsearch的朋友在处理中文内容的搜索时,肯定会遇到很尴尬的问题--中文词语被分成了一个一个的汉字,当用Kibana作图的时候,按照term来分组,结果一个汉字被分成了一组. ...
- Elastic Search中mapping的问题
Mapping在ES中是非常重要的一个概念.决定了一个index中的field使用什么数据格式存储,使用什么分词器解析,是否有子字段,是否需要copy to其他字段等.Mapping决定了index中 ...
- Elastic Search中Document的CRUD操作
一. 新增Document在索引中增加文档.在index中增加document.ES有自动识别机制.如果增加的document对应的index不存在.自动创建,如果index存在,type不存在自动创 ...
- (2)ElasticSearch在linux环境中集成IK分词器
1.简介 ElasticSearch默认自带的分词器,是标准分词器,对英文分词比较友好,但是对中文,只能把汉字一个个拆分.而elasticsearch-analysis-ik分词器能针对中文词项颗粒度 ...
- 如何在Elasticsearch中安装中文分词器(IK)和拼音分词器?
声明:我使用的Elasticsearch的版本是5.4.0,安装分词器前请先安装maven 一:安装maven https://github.com/apache/maven 说明: 安装maven需 ...
- 5.Solr4.10.3中配置中文分词器
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.下载IK Analyzer 2012FF_hf1.zip并上传到/home/test 2.按照如下命令安装 ...
- Elastic Search中filter的理解
在ES中,请求一旦发起,ES服务器是按照请求参数的顺序依次执行具体的搜索过滤逻辑的.如何定制请求体中的搜索过滤条件顺序,是一个经验活.类似query(指search中的query请求参数),也是搜索的 ...
随机推荐
- google中select添加onclick
有下拉跳转框如下所示: <select name="page" size="1" > <option onclick="refurb ...
- codeforces gym #101161G - Binary Strings(矩阵快速幂,前缀斐波那契)
题目链接: http://codeforces.com/gym/101161/attachments 题意: $T$组数据 每组数据包含$L,R,K$ 计算$\sum_{k|n}^{}F(n)$ 定义 ...
- main.js中import引入css与引入js的区别
表现:引入css样式文件能够作用到全局,而引入js文件就只能在main.js中产生作用 在 main.js 中引入的 css 都是全局生效的.引入的 js 文件只在 main.js 中生效,是因为 m ...
- C++ STL——map和multimap
目录 一 map和multimap 注:原创不易,转载请务必注明原作者和出处,感谢支持! 一 map和multimap map相对于set的区别:map具有键值和实值,所有元素根据键值自动排序.pai ...
- mybatis之动态SQL操作之更新
1) 更新条件不确定,需要根据情况产生SQL语法,这种情况叫动态SQL /** * 持久层*/ public class StudentDao { /** * 动态SQL--更新 */ public ...
- centos6里面装zabbix(二)
第一步: 如果这一步的时候有错误,那么修改php.ini(/usr/local/php/etc/这个目录下),然后重启php这个配置文件. 第二步: 第三步: 第四步: 第五步: 第六步:做到这一步的 ...
- DPDK 网络加速在 NFV 中的应用
目录 文章目录 目录 前文列表 传统内核协议栈的数据转发性能瓶颈是什么? DPDK DPDK 基本技术 DPDK 架构 DPDK 核心组件 应用 NUMA 亲和性技术减少跨 NUMA 内存访问 应用 ...
- [CDH] New project for ML pipeline
启动后台服务: [CDH] Cloudera's Distribution including Apache Hadoop 这里只介绍一些基本的流程,具体操作还是需要实践代码. 一.开发环境配置 JD ...
- RDD的cache 与 checkpoint 的区别
问题:cache 与 checkpoint 的区别? 关于这个问题,Tathagata Das 有一段回答: There is a significant difference between cac ...
- nginx配置静态资源关闭访问日志
location ~ .*\.(css|js|gif|png|jpg|jpeg|bmp|swf)$ { root $root_path; access_log off; }